







1、CBOW(continuous bags of words)和 skip-gram
CBOW:根据中心词的周围的词预测中心词
skip-gram:根据中心词预测中心词周围的词


2、CBOW结构图

①输入层:上下文单词的onehot(假设单词向量空间dim为V,上下文单词个数为C)
②所有的onehot分别乘以共享的输入权重矩阵W(V*N矩阵,n为自己设定的数,初始化权重矩阵W)
③所得的向量相加求平均作为隐层向量,size为1*N
④隐层向量乘以输出权重矩阵W‘(N*V),得到向量(1*V)
⑤激活函数处理后,得到V-dim概率分布
⑥用prediction与true lable作比较,误差越小越好
(根据onehot,其中每一维代表一个单词。则最后得到的概率分布中,概率最大的index所指示的单词维预测出的中间词)
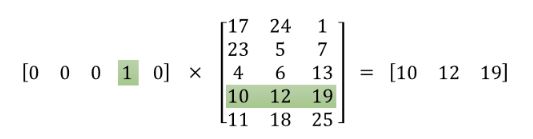
【注】loss function(一般为交叉熵代价函数),采用梯度下降算法更新 W 和 W'。训练结束后,输入层的每个单词与矩阵W相乘得到的向量就是我们想要的词向量(word embedding)。这个矩阵(所有单词的word embedding)也叫做look_up_table。根据look_up_table,就可以直接查表得到单词的词向量。根据每个词的onehot特点,假设有词向量为a = [0 0 0 1 0],则a与矩阵w相乘得到的是矩阵 w 的第四行。
【示例代码】https://www.cnblogs.com/NosenLiu/p/10153419.html (写的很详细的说!!!)
Pytorch实现:
import torch
from torch import nn, optim
from torch.autograd import Variable
import torch.nn.functional as F
CONTEXT_SIZE = 2
raw_text = "We are about to study the idea of a computational process. Computational processes are abstract beings that inhabit computers. As they evolve, processes manipulate other abstract things called data. The evolution of a process is directed by a pattern of rules called a program. People create programs to direct process. In effect, we conjure the spirits of the computer with our spells.".split(' ')
vocab = set(raw_text)
word_to_idx = {word:i for i,word in enumerate(vocab)}
data = []
for i in range(CONTEXT_SIZE, len(raw_text)-CONTEXT_SIZE):
context = [raw_text[i-2], raw_text[i-1], raw_text[i+1], raw_text[i+2]]
target = raw_text[i]
data.append((context, target))
class CBOW(nn.Module):
def __init__(self, n_word, n_dim, context_size):
super(CBOW, self)__init__()
self.embedding = nn.Embedding(n_word, n_dim)
self.linear1 = nn.Linear(2*context_size*n_dim, 128)
self.linear2 = nn.Linear(128, n_word)
def forward(self, x):
x = self.embedding(x)
x = x.view(1, -1)
x = self.linear1(x)
x = F.relu(x, inplace=True)
x = self.linear2(x)
x = F.log_softmax(x)
return x
model = CBOW(len(word_to_idx), 100, CONTEXT_SIZE)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=1e-3)
for epoch in range(1000):
print('Epoch{}'.format(epoch))
print('*'*10)
running_loss = 0
for word in data:
context, target = word
context = Variable(torch.LongTensor([word_to_idx[i] for i in context]))
target = Variable(torch.LongTensor([word_to_idx[target]]))
context, target = context.to(device), target.to(device)
out = model(context)
loss = criterion(out, target)
running_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('loss:{:.6f}'.format(running_loss) / len(data))
参考博客:https://blog.csdn.net/qq_36328915/article/details/103583846
3、skip-gram结构图
【转载】https://blog.csdn.net/weixin_41843918/article/details/90312339
代码实现:https://www.cnblogs.com/deeplearning1/p/11423387.html
Pytorch朴素实现
class SkipGram(nn.Module):
def __init__(self, n_vocab, n_embed):
super().__init__()
self.embed = nn.Embedding(n_vocab, n_embed)
self.output = nn.Linear(n_embed, n_vocab)
self.log_softmax = nn.LogSoftmax(dim=1)
def forward(self, x):
x = self.embed(x)
scores = self.output(x)
log_ps = self.log_softmax(scores)
return log_ps
device = 'cuda' if torch.cuda.is_available() else 'cpu'
embedding_dim = 300
model = SkipGram(len(vocab_to_int), embedding_dim).to(device)
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
print_every = 500
steps = 0
epochs = 5
for e in range(epochs):
for inputs, targets in get_batches(train_words, 512):
steps += 1
inputs, targets = torch.LongTensor(inputs), torch.LongTensor(targets)
inputs, targets = inputs.to(device), targets.to(device)
log_ps = model(inputs)
loss = criterion(log_ps, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def get_target(words, idx, window_size=5):
R = np.random.randint(1, window_size+1)
start = idx - R if (idx-R) > 0 else 0
stop = idx + R
target_words = words[start:idx] + words[idx+1:stop+1]
return list(target_words)
def get_batches(words, batch_size, window_size=5):
n_batches = len(words) // batch_size
words = words[:n_batches*batch_size]
for idx in range(0, len(words), batch_size):
x, y = [], []
batch = words[idx:idx+batch_size]
for ii in range(len(batch)):
batch_x = batch[ii]
batch_y = get_target(batch, ii, window_size)
y.extend(batch_y)
x.extend([batch_x] * len(batch_y))
yield x, y
#采样时的优化:Subsampling 降低高频词的概率
from collections import Counter
import random
import numpy as np
threshold = 1e-5
word_counts = Counter(int_words)
total_count = len(int_words)
freqs = {word: count/total_count for word,count in word_counts.items()}
p_drop = {word:1-np.sqrt(threshold/freqs[word]) for word in word_counts}
train_words = [word for word in int_words if random.random() < (1-p_drop[word])]skip-gram进阶:negative sampling
class NegativeSamplingLoss(nn.Moudle):
def __init__(self):
super().__init__()
def forword(self, input_vectors, output_vectors, noise_vectors):
batch_size, embed_size = input_vectors.shape
input_vectors = input_vectors.view(batch_size, embed_size, 1)
output_vectors = output_vectors.view(batch_size, 1, embed_size)
out_loss = torch.bmm(output_vectors, input_vectors).sigmoid().log()
out_loss = out_loss.squeeze()
noise_loss = torch.bmm(noise_vectors.neg(), input_vectors).sigmoid()
noise_loss = noise_loss.squeeze().sum(1)
return -(out_loss + noise_loss).mean()
#get our noise distribution
#using word frequencies calculated earlier in the notebook
word_freqs = np.array(sorted(freqs.values(), reverse = True))
unigram_dist = word_freqs/word_freqs.sum()
noise_dist = torch.from_numpy(unigram_dist**(0.75)/np.sum(unigram_dist**(0.75)))
class SkipGramNeg(nn.Module):
def __init__(self, n_vocab, n_embed, noise_dist=None):
super().__init__()
self.n_vocab = n_vocab
self.n_embed = n_embed
self.noise_dist = noise_dist
#define embedding layers for input and output words
self.in_embed = nn.Embedding(n_vocab, n_embed)
self.out_embed = nn.Embedding(n_vocab, n_mebed)
#Initialize embedding tables with uniform distribution
#I believe this helps with convergence
self.in_embed.weight.data.uniform_(-1, 1)
self.out_embed.weight.data.uniform_(-1, 1)
def forward_input(self, input_words):
input_vectors = self.in_embed(input_words)
return input_vectors
def forward_output(self, output_words):
output_vectors = self.out_embed(output_words)
return output_vectors
def forward_noise(self, batch_size, n_samples):
#generate noise vectors with shape (batch_size, n_samples, n_embed)
if self.noise_dist is None:
noise_dist = torch.ones(self.n_vocab)
else:
noise_dist = self.noise_dist
noise_words = torch.multinomial(noise_dist, batch_size*n_samples, replacement=True)
device = 'cuda' if model.out_embed.weight.is_cuda else 'cpu'
noise_words = noise_words.to(device)
noise_vectors = self.out_embed(noise_words).view(batch_size, n_samples, self.n_embed)
return noise_vectors
#training
device = 'cuda' if torch.cuda.is_available() else 'cpu'
embedding_dim = 300
model = SkipGramNeg(len(vocab_to_int), embedding_dim, noise_dist=noise_dist).to(device)
criterion = NegativeSamplingLoss()
optimizer = optim.Adam(model.parameters(), lr=0.003)
print_every = 1500
steps = 0
epochs = 5
#train for some number of epochs
for e in range(epochs):
#get our input, target batches
for input_words, target_words in ger_batches(train_words, 512):
step += 1
inputs, targets = torch.LongTensor(input_words), torch.LongTensor(targets)
inputs, targets = input.to(device), targets.to(device)
input_vectors = model.forward_input(inputs)
output_vectors = model.forward_output(targets)
noise_vectors = model.forward_noise(inputs.shape[0], 5)
#negative sampling loss
loss = criterion(input_vectors, output_vectors, noise_vectors)
optimizer.zero_grad()
loss.backward()
optimizer.step()
参考博客:https://blog.csdn.net/weixin_40759186/article/details/87857361















 494
494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









