







算法原理
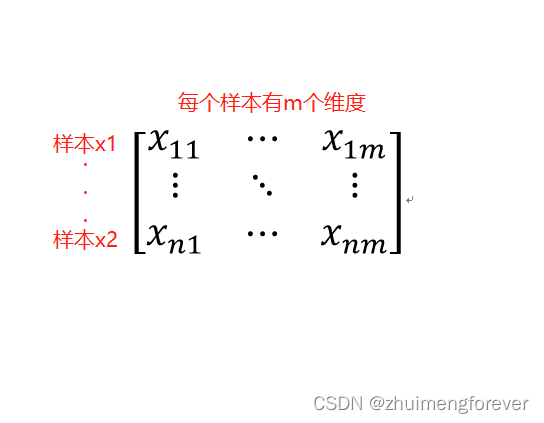
假设有一矩阵,行为样本,列为样本的参数,Kennard-Stone算法就是要从中选择预定数目的样品。(1) 首先计算两两样本之间距离,选择距离最大的两个样品。(2) 然后分别计算剩余的样本与已选择的两个样本之间的距离。(3) 对于每个剩余样本而言, 其与已选样品之间的最短距离被选择, 然后选择这些最短距离中相对最长的距离所对应的样本, 作为第三个样品。(4) 重复步骤(3) , 直至所选的样品的个数等于事先确定的数目为止,比如10个,或者20个。比如:给你100个样品,以及每个样品的参数(比如有1000个),如何根据参数,从100个选择80个作为训练集,来建立回归模型,而剩余的作为预测集。
如何用KS方法挑选出这80个训练集。
图解原理
1.计算每两个点之间的距离,获得距离最大的两个点,如下图所示,在n个点两两之间的距离中,A点到其他n-1个点的距离在图中标注,其中A到B的距离最大。
![获取距离最大的两个点A和B
2.计算其他n-2个样本与A、B两个点之间的较短距离,组成一个数组,在此较短距离数组中再选择距离最长的所连接的除A或B外的样本点,为第三个点。
3.重复上述步骤,选择样本点,直至获得所需样本数量。
Python实现
import numpy as np
import pandas as pd
#数据集只有表头一列一特征,一行一样本
x_variables=pd.read_excel("D:/桌面/毕设/数据集/LAI-VIs新1.xlsx",sheetname='新总')
# 定义算法
def kennardstonealgorithm(x_variables, k):
x_variables = np.array(x_variables)
original_x = x_variables
distance_to_average = ((x_variables - np.tile(x_variables.mean(axis=0), (x_variables.shape[0], 1))) ** 2).sum(
axis=1)
max_distance_sample_number = np.where(distance_to_average == np.max(distance_to_average))
max_distance_sample_number = max_distance_sample_number[0][0]
selected_sample_numbers = list()
selected_sample_numbers.append(max_distance_sample_number)
remaining_sample_numbers = np.arange(0, x_variables.shape[0], 1)
x_variables = np.delete(x_variables, selected_sample_numbers, 0)
remaining_sample_numbers = np.delete(remaining_sample_numbers, selected_sample_numbers, 0)
for iteration in range(1, k):
selected_samples = original_x[selected_sample_numbers, :]
min_distance_to_selected_samples = list()
for min_distance_calculation_number in range(0, x_variables.shape[0]):
distance_to_selected_samples = ((selected_samples - np.tile(x_variables[min_distance_calculation_number, :],
(selected_samples.shape[0], 1))) ** 2).sum(
axis=1)
min_distance_to_selected_samples.append(np.min(distance_to_selected_samples))
max_distance_sample_number = np.where(
min_distance_to_selected_samples == np.max(min_distance_to_selected_samples))
max_distance_sample_number = max_distance_sample_number[0][0]
selected_sample_numbers.append(remaining_sample_numbers[max_distance_sample_number])
x_variables = np.delete(x_variables, max_distance_sample_number, 0)
remaining_sample_numbers = np.delete(remaining_sample_numbers, max_distance_sample_number, 0)
return selected_sample_numbers, remaining_sample_numbers
#调用k-s算法函数
a=kennardstonealgorithm(x_variables, 72)
#得到训练集和测试集索引值
train=a[0]
test=a[1]
data=np.array(x_variables)
#根据索引值获取对应的样本实际值
train_samples=data[train]
test_samples=data[test]
参考:
https://blog.sciencenet.cn/blog-464042-552038.html
https://zhuanlan.zhihu.com/p/492263636















 1650
1650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}