










Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
--Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
(Submitted on 18 Jun 2014 (v1), last revised 23 Apr 2015 (this version, v4)) -- (TPAMI) 2015
摘要:
Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This requirement is "artificial" and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip the networks with another pooling strategy, "spatial pyramid pooling", to eliminate the above requirement. The new network structure, called SPP-net, can generate a fixed-length representation regardless of image size/scale. Pyramid pooling is also robust to object deformations. With these advantages, SPP-net should in general improve all CNN-based image classification methods. On the ImageNet 2012 dataset, we demonstrate that SPP-net boosts the accuracy of a variety of CNN architectures despite their different designs. On the Pascal VOC 2007 and Caltech101 datasets, SPP-net achieves state-of-the-art classification results using a single full-image representation and no fine-tuning.
The power of SPP-net is also significant in object detection. Using SPP-net, we compute the feature maps from the entire image only once, and then pool features in arbitrary regions (sub-images) to generate fixed-length representations for training the detectors. This method avoids repeatedly computing the convolutional features. In processing test images, our method is 24-102x faster than the R-CNN method, while achieving better or comparable accuracy on Pascal VOC 2007.
In ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014, our methods rank #2 in object detection and #3 in image classification among all 38 teams. This manuscript also introduces the improvement made for this competition.
R-CNN模型存在的问题之一
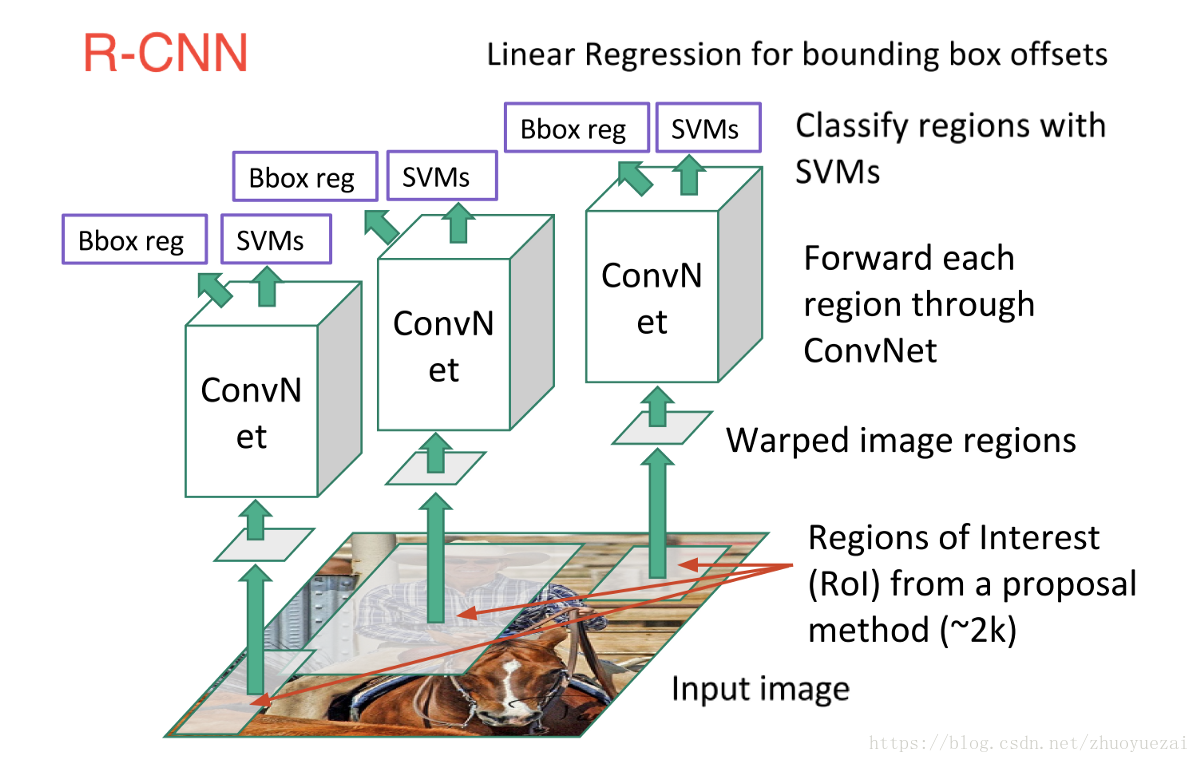
require a fixed-size (e.g., 224x224) input image.
现实中图像大小是不一致的,R-CNN的方法是crop / warp一张图像然后再输入到网络中,而作者用的SPP-net是下面这样的

So why do CNNs require a fixed input size?
A CNNmainly consists of two parts: convolutional layers, and fully-connected layers that follow. The convolutional layers operate in a sliding-window manner and output feature maps which represent the spatial arrangement of the activations In fact, convolutional layers do not require a fixed image size and can generate feature maps of any sizes.
On the other hand, the fully-connected layers need to have fixed size/length input by their definition. Hence, the fixedsize constraint comes only from the fully-connected layers, which exist at a deeper stage of the network.(根本原因在于fully-connected layers need to have fixed size/length )按照这个思路只要在fc layers之前尺寸一致就可以了,所以就可以在conv layers 之前或者之后进行一些操作。
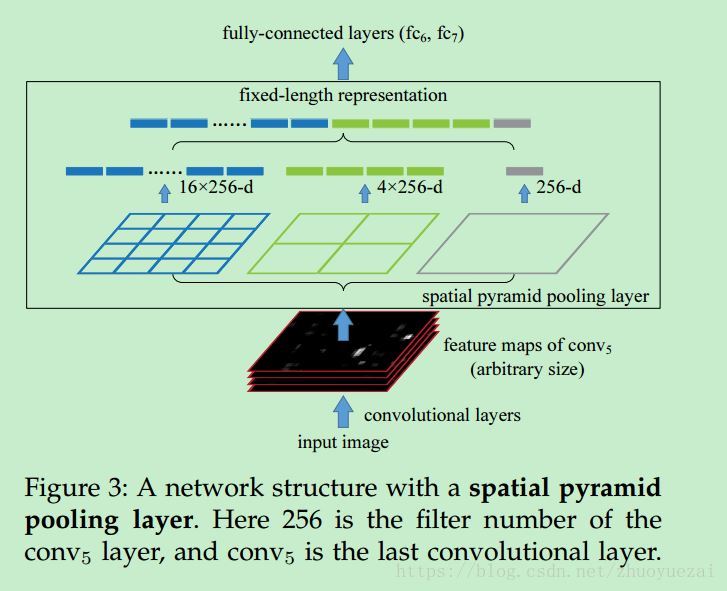
本篇文章的创新点(见图2)
In this paper, we introduce a spatial pyramid pooling (SPP) layer to remove the fixed-size constraint of the network. Specifically, we add an SPP layer on top of the last convolutional layer. The SPP layer pools the features and generates fixedlength outputs, which are then fed into the fullyconnected layers (or other classifiers). In other words, we perform some information “aggregation” at a deeper stage of the network hierarchy (between convolutional layers and fully-connected layers) to avoid the need for cropping or warping at the beginning.
SPP的几个特点
1) SPP is able to generate a fixed length output regardless of the input size, while the sliding window pooling used in the previous deep networks [3] cannot;
2) SPP uses multi-level spatial bins, while the sliding window pooling uses only a single window size. Multi-level pooling has been shown to be robust to object deformations [15];
3) SPP can pool features extracted at variable scales thanks to the flexibility of input scales. Through experiments we show that all these factors elevate the recognition accuracy of deep networks.
The convolutional layers use sliding filters, and their outputs have roughly the same aspect ratio as the inputs. These outputs are known as feature maps [1] - they involve not only the strength of the responses, but also their spatial positions.
相对于R-CNN节约时间的地方
In this paper, we show that we can run the convolutional layers only once on the entire image (regardless of the number of windows), and then extract features by SPP-net on the feature maps. (而 R-CNN需要 computes features for each proposal using a large convolutional neural network (CNN),可能要计算2000次,所以本文的方法节约了很多时间)
先分析到这里
参考文献
深度学习研究理解7:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition














 698
698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









