







实验目的
本实验的主要目的是通过对特定网站的分析,深入了解万维网的运行原理和相关技术,以及通过使用抓包工具采集HTTP协议包并进行分析,实现以下几个具体目标:
深入了解万维网的结构、原理和相关技术:通过分析特定网站,探讨万维网的构建和运行原理,包括网络拓扑结构、分布式系统、域名系统(DNS)、IP地址分配等方面的知识。
深入了解并掌握WEB页面的组成:通过分析特定网站的页面,学习了解WEB页面的基本组成部分,包括HTML、CSS、JavaScript等前端技术,以及后端技术如服务器端脚本、数据库等。
深入了解并掌握HTTP协议:通过使用抓包工具采集HTTP协议包,并对其进行详细分析,探讨HTTP协议的工作原理、请求响应过程、状态码的含义以及常见的HTTP头部字段等关键知识点,从而更好地理解网站之间的通信和数据传输过程。
本实验能够让我深刻理解万维网的运行机制和相关技术,为进一步学习和应用网络和Web开发领域的知识打下坚实的基础。同时,通过实际操作和分析,我将能够更好地理解抽象的网络概念,并具备分析和解决网络问题的能力。
实验内容
在本实验中,我们将通过对一个特定网站的深入分析,探索并理解万维网的运行原理以及与之相关的技术,尤其是HTTP协议的工作机制。具体而言,本实验将包括以下主要内容:
- 选择特定网站:首先,我们会选择一个特定的网站作为我们的研究对象。这个选择的网站将成为我们实验的核心,通过分析它,我们将深入了解该网站的运行方式以及所用的技术。
- 登录并操作网站:在选择的网站上进行登录并执行多种操作,例如浏览不同页面、进行搜索、点击链接或提交表单等。这些操作将生成多个HTTP请求,有助于我们观察网站行为和与之相关的HTTP通信。
- 使用浏览器开发者工具:我们将利用浏览器的开发者工具,特别是网络面板,以捕获和查看与所选网站之间的HTTP通信内容。通过这些工具,我们可以详细分析HTTP请求和响应,以便深入了解数据交换过程。
- 绘制网络拓扑和数据流向:基于我们观察到的网络通信情况,我们将绘制一个网络拓扑图,清晰展示各组成部分之间的连接关系。此外,我们还会标示数据流向,包括数据是如何在浏览器、协议、服务器之间流动的。
- 分析单个网页的组成:我们将仔细分析所选网站中的一个单独网页,包括其HTML组成要素,如页面结构、标签、CSS样式等。这将帮助我们理解前端构建。
- HTTP协议分析:对所选网站的HTTP协议进行深入分析,包括请求报文和应答报文的结构和内容。特别关注报文中的关键点,例如请求方法、URL、状态码、响应数据等,以深入理解网站与客户端之间的通信细节。
实验步骤
网址的选取
本次实验选择了 https://stackoverflow.com/ 作为实验的研究对象。Stack Overflow是一个知名的问答网站,广泛用于程序员和开发者社区。这个选择的网站具有丰富的内容和复杂的前后端技术,适合用于深入了解万维网的运行原理和相关技术。
在Edge浏览器中输入网址:首先,我们在Edge浏览器的地址栏中输入了 https://stackoverflow.com/ 网址,以便进入该网站的主页。
进入页面:浏览器会加载并呈现Stack Overflow的主页,这是一个动态的网页,包含了各种问题、答案以及与开发者社区相关的信息。
打开开发者工具:我们通过浏览器的开发者工具来捕获和分析与网站之间的HTTP通信。在Edge浏览器中,可以通过按下F12键或右键点击页面并选择“检查”来打开开发者工具。
刷新页面:在开发者工具打开的情况下,我们刷新了Stack Overflow的主页。这一步操作会触发新的HTTP请求,包括页面的资源加载和数据请求,这些请求将在后续的分析中被详细研究。
通过这些操作,我们进入了Stack Overflow网站,启用了开发者工具,准备开始对该网站的HTTP通信和页面结构进行深入分析,以更好地理解万维网的运行原理和相关技术。
分析网络拓扑和数据流向
拓扑图见下方实验内容部分
分析网页组成
在开发者工具中打开元素标签,便可以对网页的html组成进行查看。分析结果见下方实验内容部分
分析HTTP协议
为了更深入地理解网站的运行原理,我们在开发者工具中打开了Network标签,通过以下步骤查看Stack Overflow网站的HTTP协议细节:
- 打开Network标签:在开发者工具中,我们点击了Network标签,以便监视所有与网站之间的网络请求和响应。
- 刷新页面:随后,我们执行了页面的刷新操作,这导致浏览器向Stack Overflow网站发送了多个HTTP请求,以获取页面所需的资源和数据。
- 找到https://stackoverflow.com/:在Network标签中,我们可以看到多个请求列表,其中包括与Stack Overflow网站相关的请求。我们找到了名为https://stackoverflow.com/的请求,这是对网站主页的请求。
- 点击Headers:为了查看HTTP协议的详细信息,我们点击了https://stackoverflow.com/请求下的Headers选项。这一步骤将显示该请求的HTTP头部信息,包括请求头和响应头。

实验结果
网络拓扑和数据流向

网页组成分析
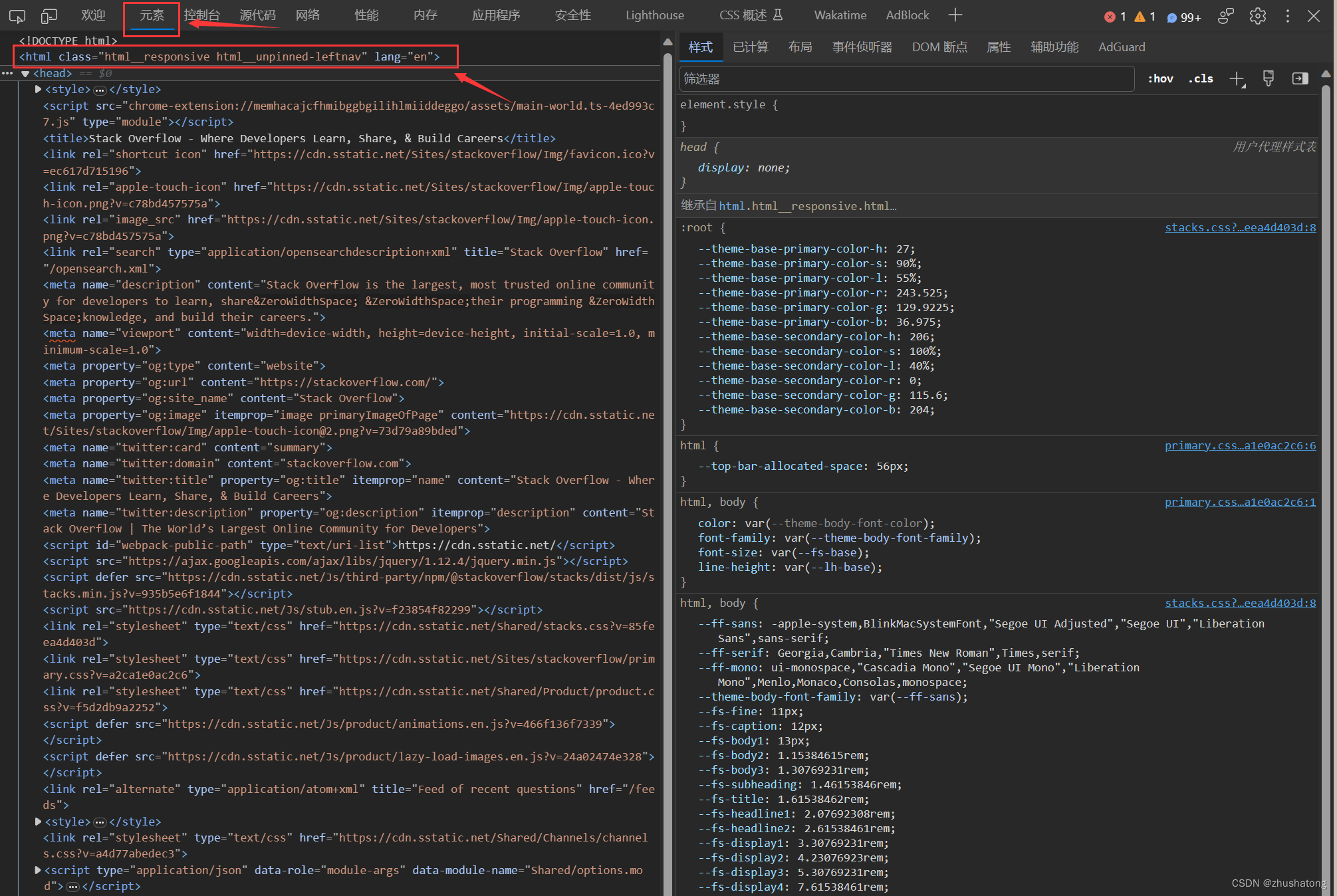
首先,在这个HTML网页中,<head>标签通常用于包含文档的元数据信息,例如页面的标题和字符集设置。而<body>标签则用于包含网页的实际内容,例如文本、图像、链接和其他媒体元素。
在<head>标签内,通常会包含<meta>标签来定义字符集和其他元数据。这些元数据可以帮助浏览器正确地渲染网页,并让搜索引擎更好地理解网页的内容。此外,<head>标签还可以包含<link>标签,用于引用外部样式表(CSS)和图标。
在<body>标签内,网页的实际内容开始展现。这可能包括文章的主要文本,段落,标题,以及图像、视频和音频等多媒体元素。链接也经常出现在<body>标签内,以便用户可以导航到其他网页。
网页的语言设置(lang="en")非常重要,因为它有助于浏览器和搜索引擎正确地解释和呈现文本。

先看子标签head,子标签<head>通常包含了网页的元信息和资源链接。以下是<head>标签中可能包含的一些子标签及其作用:
- <title>标签:该标签包含了网站的标题,通常显示在浏览器标签页的标题栏上,对于搜索引擎优化(SEO)也很重要。
- <meta>标签:用于提供网站的元信息,如关键词、简介、作者等。这些信息有助于搜索引擎了解网页内容和分类。
- <link>标签:通常用于引用外部样式表文件(CSS),用于控制网页的布局和外观。也可以用于定义网站图标(favicon)等信息。
- <script>标签:包含网页的JavaScript脚本代码,用于实现网页的交互和功能。JavaScript是一种常用的客户端脚本语言。
- <style>标签:包含网页的CSS样式规则,用于定义网页的外观和排版,可以控制字体、颜色、边距等样式属性。
这些子标签共同构成了<head>部分,以帮助网页正确地渲染和交互。<title>标签定义了网页的标题,<meta>标签提供了重要的元信息,<link>标签引用外部样式表,<script>标签包含了JavaScript代码,而<style>标签则定义了内部样式。
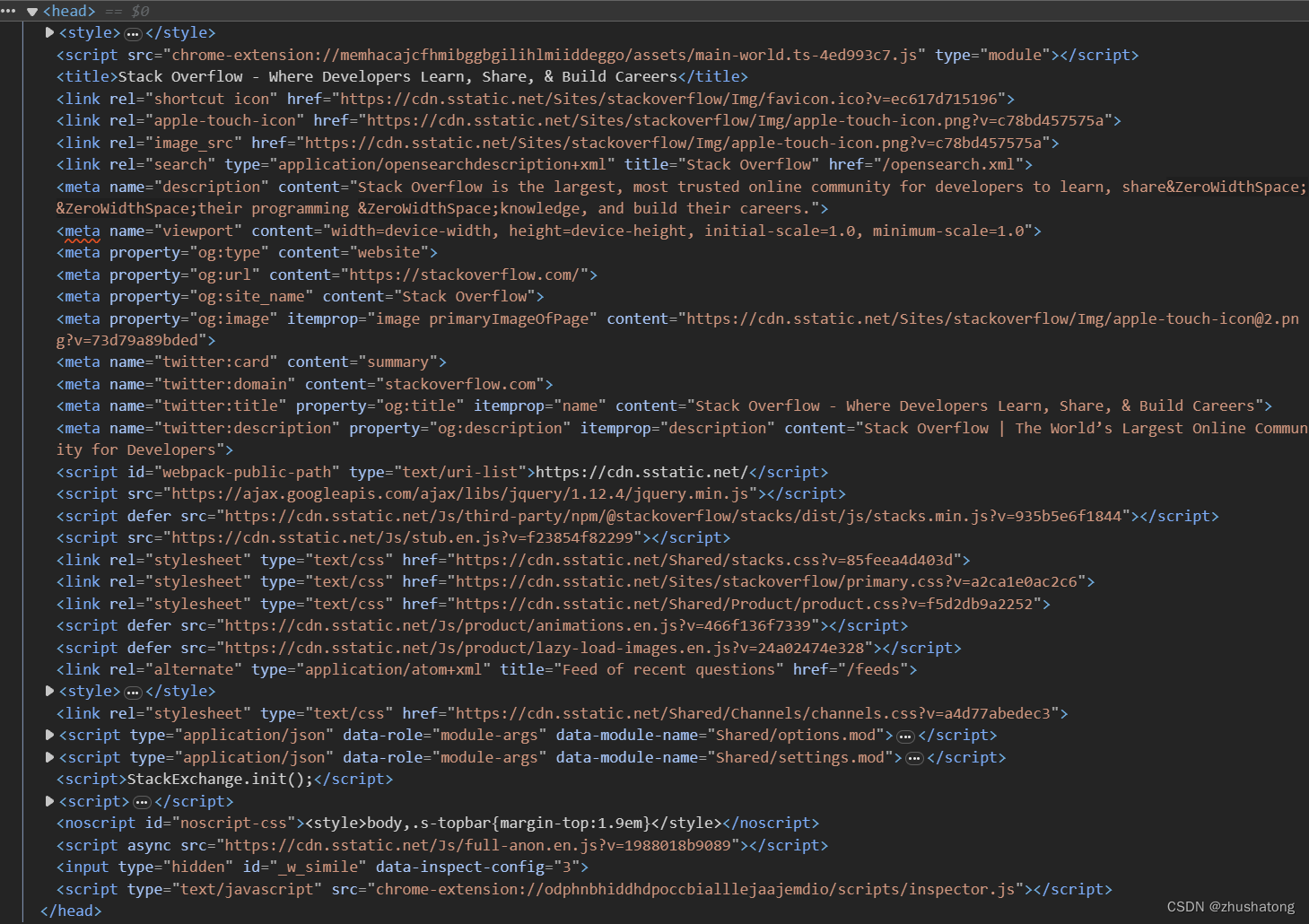
子标签<body>是网页的主要内容部分,通常包含了网站的实际显示内容。在<body>中,常见的标签是<div>,它们用来划分网页的布局,将页面分成多个小块,每个小块可以具有自己的样式、属性和行为。
这些<div>标签的目的是将网页内容组织成易于管理和排列的结构。通过使用不同的<div>,可以创造出各种不同的布局,例如页眉、导航栏、内容区域和页脚等。

HTTP协议分析
请求报文

- :authority: stackoverflow.com
这是HTTP/2中的伪标头字段,指示请求的目标主机名。
- :method: GET
该伪标头字段指定了HTTP方法,这里是GET,表示客户端希望获取资源。
- :path: /
这是伪标头字段,表示请求的路径,即要访问的资源的相对路径。在这里,请求的路径是根路径 /。
- :scheme: https
这是伪标头字段,指示请求使用的协议方案,这里是HTTPS。
- Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
这是客户端发送的Accept头部字段,指示客户端可以接受的响应媒体类型和优先级。
- Accept-Encoding: gzip, deflate, br
这是客户端发送的Accept-Encoding头部字段,指示客户端支持的响应内容编码方法,包括gzip、deflate和br(Brotli)等。
- Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,en-GB;q=0.6
这是客户端发送的Accept-Language头部字段,指示客户端支持的语言首选项,以便服务器返回相应的本地化内容。
- Cache-Control: max-age=0
这是客户端发送的Cache-Control头部字段,指示客户端不要使用缓存副本,要求服务器始终提供最新的资源。
- Cookie:
这是客户端发送的Cookie头部字段,包含了一个或多个HTTP Cookie,用于标识客户端的会话信息。
- Sec-Ch-Ua: "Microsoft Edge";v="117", "Not;A=Brand";v="8", "Chromium";v="117"
这是一个安全头部,指示客户端的用户代理(User Agent)信息。它包括了用户代理名称及版本号。
- Sec-Ch-Ua-Mobile: ?0
这是一个安全头部,指示客户端是否在移动设备上运行。
- Sec-Ch-Ua-Platform: "Windows"
这是一个安全头部,指示客户端的操作系统平台。
- Sec-Fetch-Dest: document
这是一个安全头部,指示客户端期望获取的响应类型是文档。
- Sec-Fetch-Mode: navigate
这是一个安全头部,指示客户端的请求模式,这里是导航模式,表示客户端希望导航到新的页面。
- Sec-Fetch-Site: none
这是一个安全头部,指示请求的站点类型。"none" 表示请求没有来源站点。
- Sec-Fetch-User: ?1
这是一个安全头部,表示用户是否参与了请求。 "?1" 表示用户参与。
- Upgrade-Insecure-Requests: 1
这是一个请求头部字段,指示客户端希望将不安全的HTTP请求升级为HTTPS,以增加安全性。
- User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47
这是用户代理头部字段,包含了客户端的详细信息,包括浏览器类型、版本和操作系统信息。
响应报文

- Cache-Control: private
该字段指定了响应的缓存控制策略。在这种情况下,响应被标记为私有的,意味着它只能被单个用户缓存,而不能被共享缓存。
- Cf-Cache-Status: DYNAMIC
该字段是由Cloudflare CDN (Content Delivery Network) 提供的,表示缓存状态。这里的 "DYNAMIC" 表示响应是动态生成的,没有被缓存。
- Cf-Ray: 812670151cfb1073-HKG
这是Cloudflare使用的一个标识符,用于跟踪请求/响应的详细信息。
- Content-Encoding: gzip
这个字段指定了响应主体使用了gzip压缩算法进行压缩。
- Content-Security-Policy: upgrade-insecure-requests; frame-ancestors 'self' https://stackexchange.com
这是内容安全策略(CSP)的设置,用于控制哪些内容和来源可以加载到页面中。在这里,它要求升级不安全的请求,并限制框架(iframe)的来源只能是本站和https://stackexchange.com。
- Content-Type: text/html; charset=utf-8
表明响应主体的内容类型为HTML,字符集为UTF-8编码。
- Date: Sat, 07 Oct 2023 13:19:48 GMT
指示响应的生成日期和时间。
- Feature-Policy: microphone 'none'; speaker 'none'
这是特性策略的设置,用于控制页面的一些功能,例如麦克风和扬声器的使用。在这里,禁用了麦克风和扬声器。
- Server: cloudflare
指明了服务器的类型,这里是Cloudflare。
- Set-Cookie: prov=59d5b555-1148-488a-a9a6-e50a239720a8; expires=Mon, 07 Oct 2024 13:19:48 GMT; domain=.stackoverflow.com; path=/; secure; samesite=none; httponly
设置了一个HTTP Cookie,包括名称、值、过期时间、作用域、路径和一些安全选项。
- Strict-Transport-Security: max-age=15552000
告诉浏览器在未来的时间内强制使用HTTPS进行通信,以增加安全性。
- Vary: Accept-Encoding
指定了Vary头部,表示响应的内容可能会根据请求中的Accept-Encoding头部不同而变化。
- X-Dns-Prefetch-Control: off
控制DNS预取的设置,这里是禁用了DNS预取。
- X-Frame-Options: SAMEORIGIN
这是一个安全头部,用于控制页面是否可以嵌套在iframe中。这里的 "SAMEORIGIN" 意味着只有相同来源的页面可以嵌套当前页面。
X-Request-Guid: b89fcadb-1473-479e-be05-06d9b82ffbbc
一个请求标识符,用于跟踪请求的唯一性。
实验总结
利用浏览器的开发者工具,特别是网络面板,捕获和查看了与所选网站之间的HTTP通信内容。通过这些工具,详细分析了HTTP请求和响应,深入了解了数据交换过程,包括请求头、响应头、请求方法、URL、状态码等关键信息。
基于观察到的网络通信情况,绘制了一个网络拓扑图,清晰展示了各组成部分之间的连接关系,同时标示了数据流向,包括数据在浏览器、协议、服务器之间的流动路径。这有助于更好地理解网站的整体架构和数据传输流程。
进一步,深入分析了所选网站中的一个单独网页,包括其HTML组成要素、页面结构、标签、CSS样式等。这帮助理解了前端构建的基本原理和技术。
最重要的是,对HTTP协议进行了深入分析,包括请求报文和应答报文的结构和内容。特别关注了请求方法、URL、状态码、响应数据等关键点,从而更深入地理解了网站与客户端之间的通信细节。















 2221
2221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









