







论文地址:https://arxiv.org/pdf/2011.11893.pdf
Abstract
在视频中训练时间动作检测需要大量的标记数据,但这种注释的收集成本很高。将未标记或弱标记的数据合并到训练动作检测模型中,有助于降低标注成本。在这项工作中,我们首先引入了半监督的动作检测(SSAD)任务,并分析了直接将半监督任务应用过来时会出现的错误。为了解决SSAD baselines中的主要问题(动作不完整性),我们利用前景和背景运动之间的“独立性”,设计了一个无监督的前景注意(UFA)模块。然后,我们将弱标记数据合并到SSAD中,并提出了具有三个级别监督的全监督动作检测(OSAD)。信息瓶颈(IB)模块在非动作帧中抑制场景信息,同时保留动作信息,以帮助克服OSAD基线中伴随的动作上下文混淆问题。我们在THUMOS14和ActivityNet1.2中创建的数据分割上对SSAD和OSAD进行了广泛的基准测试,并演示了所提出的UFA和IB方法的有效性。
Introduction
视频标记动作区间是一件非常耗时的工作,为了缓解这个问题,一个方向是最大限度地使用未标记或弱标记的数据,以以更少的注释成本提高性能。在这项工作中,我们研究了时间动作检测使用较少的标记视频和其他级别的监督,如未标记和弱标记的视频。
在半监督图像分类的任务中,已经研究了对未标记数据的学习,并显示出了良好的结果,而这种问题设置在时间动作检测中尚未得到探索。我们引入了半监督动作检测(SSAD)任务,并通过将三个最先进的半监督学习(SSL)模型(Mean Teacher,MixMatch,FixMatch)合并到一个完全监督动作检测(FSAD)主干中,建立了三个SSAD baselines。为了对SSAD基准进行初步评估,我们选择了一种直接而有效的FSAD方法,SSN,作为我们的骨干,并将开发更复杂的骨干留给未来的工作。
在SSAD基线模型中直接应用SSL算法,只会带来很小的结果改进。为了追踪误差的主要来源,我们对SSAD基线进行了误差分析,发现SSAD基线的主要问题是动作不完全性,即动作持续时间的缺失部分,如下图所示:
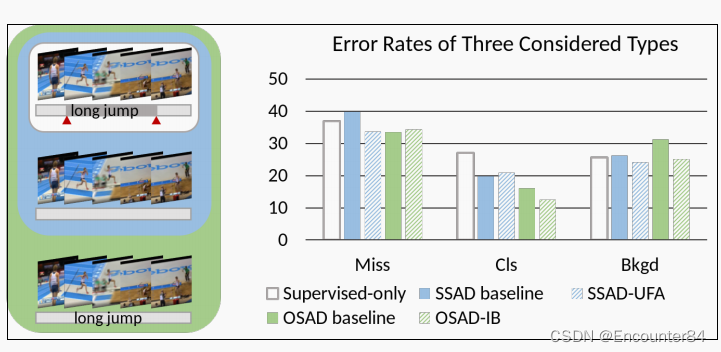
具体来说,我们通过最小化未标记数据中前景和背景运动之间的信息减少率来学习注意力。为此,我们提出的无监督前景注意(UFA)模块成功地帮助SSAD模型识别相对完整的动作,而不需要额外的注释成本。
主要贡献如下:(i)提出SSAD和OSAD任务在时间动作检测中利用未标记和弱标记数据,并为它们建立几个基线模型;(ii)设计无监督前景注意模块,缓解SSAD基线中的动作不完整性问题;(iii)设计一种信息瓶颈方法来解决OSAD基线中的动作上下文混淆问题;(iv)通过广泛的实验验证了所提出的SSAD和OSAD方法,并在给出注释预算的现实场景下展示了我们的OSAD-ib模型的优势。
Method
Semi-Supervised Action Detection Baselines:
在SSN中,我们在提案级别训练一个分类模块
h
c
l
s
h_{cls}
hcls和一个回归模块
h
r
e
g
h_{reg}
hreg,同时我们也训练一个完整性模块
h
c
o
m
p
h_{comp}
hcomp来预测提案的完整性,以表明proposal是否是一个完整的动作片段。如果一个提案自己的跨度超过80%与一个动作片段重叠,而它与该片段的IoU低于0.3,则被认为是不完整的(ci=0)。第i项提案的总损失LS包括三个部分:
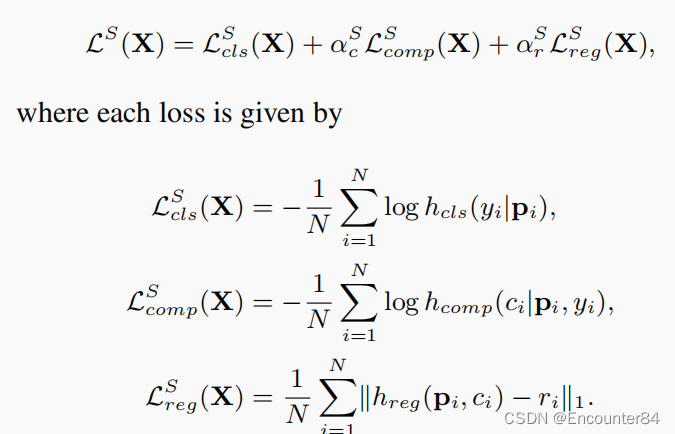
在所有的SSL算法中,我们都利用了视频数据的空间和时间增强。对于空间增强,我们对每个方案中的所有帧应用随机噪声和水平翻转。我们还设计了三个时间增强器:(i)时间重采样:我们通过平均池化获得了提议的特征。在实际应用中,我们只从提议中采样L帧,并将其特征的平均值作为一个有效的估计。在时间重采样中,我们从提议中重新采样L帧,并将新的平均值作为一个增强特征。(ii)时间分辨率:我们不是从每个方案中采样L帧,而是采样2L或L/2帧。(iii)时间翻转:视频向后播放。对于固定匹配中的弱增强,我们只使用空间增强,而不使用时间增强。
Unsupervised Foreground Attention:
这一块没看懂,抽空再补上
Omni-Supervised Action Detection with Information Bottleneck:
现在,我们添加了弱标记数据来训练模型的三个监督水平,并形成了全监督动作检测(OSAD)。对于完全标记和未标记的数据,我们最小化引入的
L
S
(
X
)
L^S(X)
LS(X)和
L
U
(
X
)
L^U(X)
LU(X)。对于弱标记数据,我们优化了一个视频层分类损失
L
W
(
X
)
L^W(X)
LW(X):

然而,OSAD baseline很容易将非动作框架归类为动作框架(动作-上下文混淆)。这个问题在从弱标记的数据中学习动作检测时很常见。理想情况下,识别模型期望基于动作信息(如游泳)对弱标记视频进行分类,这也有利于动作检测任务。然而,该模型倾向于采取“捷径”,并学习根据场景信息(如游泳池)对动作进行分类,这将会将非动作帧与场景误为动作帧,从而干扰检测。现在的问题是,在只训练分类任务时,我们如何过滤掉场景信息,只保留动作信息?请注意,尽管动作帧同时包含动作信息和场景信息,但非动作帧只包含场景部分。因此,我们建议通过惩罚从非动作帧中提取的所有信息来“忘却”场景信息。
假设特征分布为高斯分布,非作用帧的信息可以用:
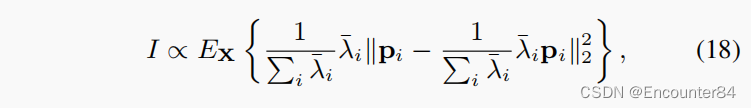
直观地说,这是一个显式的信息瓶颈(IB),其中我们最大化了关于分类标签的(动作)信息,同时最小化了关于非动作输入帧的(场景)信息。















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









