







一、内存对齐的原因
我们都知道计算机是以字节(Byte)为单位划分的,理论上来说CPU是可以访问任一编号的字节数据的,我们又知道CPU的寻址其实是通过地址总线来访问内存的,CPU又分为32位和64位,在32位的CPU一次可以处理4个字节(Byte)的数据,那么CPU实际寻址的步长就是4个字节,也就是只对编号是4的倍数的内存地址进行寻址。同理64位的CPU的寻址步长是8字节,只对编号是8的倍数的内存地址进行寻址,如下图所示是64位CPU的寻址示意图:
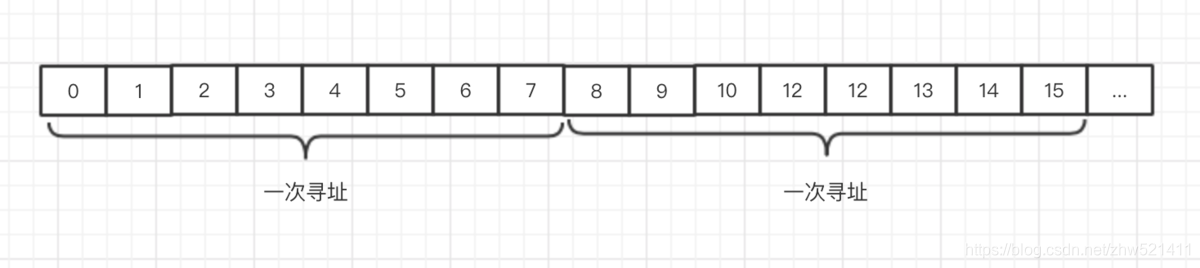
这样做可以实现最快速的方式寻址且不会遗漏一个字节,也不会重复寻址。
那么对于程序而言,一个变量的数据存储范围是在一个寻址步长范围内的话,这样一次寻址就可以读取到变量的值,如果是超出了步长范围内的数据存储,就需要读取两次寻址再进行数据的拼接,效率明显降低了。例如一个double类型的数据在内存中占据8个字节,如果地址是8,那么好办,一次寻址就可以了,如果是20呢,那就需要进行两次寻址了。这样就产生了数据对齐的规则,也就是将数据尽量的存储在一个步长内,避免跨步长的存储,这就是内存对齐。在32位编译环境下默认4字节对齐,在64位编译环境下默认8字节对齐。
查看自己电脑是多少位操作系统
终端下输入:uname -a 回车
x86_64 表示系统为64位
i686 表示系统32位的
二、对齐规则
1:数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员的偏移为 #pragma pack 指定的数值和这个数据成员自身长度中较小那个的整数倍。
2:数据成员为结构体:如果结构体的数据成员还为结构体,则该数据成员的“自身长度”为其内部最大元素的大小。(struct a 里存有 struct b,b 里有char,int,double等元素,那 b “自身长度”为 8)
3:结构体的整体对齐规则:在数据成员按照 #1 完成各自对齐之后,结构体本身也要进行对齐。对齐会将结构体的大小增加为 #pragma pack 指定的数值和结构体最大数据成员长度中较小那个的整数倍。
(看不懂没关系,因为我也没看懂,也是打印之后才明白)
三、实例
typedef struct test1 {
char a;//1
int b;//4字节
double c;//8
char d[11];//11
}Test1;//数据成员
int main(int argc, const char * argv[]) {
Test1 t1;
//xcode默认对齐系数8,即#pragma pack(8)
//char a, 1<8按1对齐,offset=0 [0]
//int b, 4<8按4对齐,char a占到[0],int b应该从地址1开始排, 地址1不是对齐数4的倍数,所以int b的首地址是从4的最小倍数开始,所以offset=4, [4...7];
//dou 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









