







1、逻辑回归基本概念
Logistic 回归模型是目前广泛使用的学习算法之一,通常用来解决二分类问题(即输出只有两种,分别代表两个类别),虽然名字中有“回归”,但它是一个分类算法。
Logistic 回归的优点是计算代价不高,容易理解和实现;缺点是容易欠拟合,分类精度可能不高。
与线性回归的区别:线性回归预测输出的是(-∞,+∞)
而逻辑回归输出的是{0,1},这里面0我们称之为负例,1称之为正例。
如果分类器用的是回归模型,并且已经训练好了一个模型,可以设置一个阈值:
如果,则预测
,既y属于正例
如果,则预测
,既y属于负例
但是对于二分类问题来说,线性回归模型的输出值可以大于1也可以小于0,所以我们需要一个函数,将输出转换到0和1之间。这里我们引入一个函数,sigmoid函数:
g代表的就是这个函数:
图像如下:

从图像可以看出,sigmoid 函数将负无穷到正无穷之间的数转化为 0 到 1 之间,负无穷处趋向 0 ,正无穷处趋向 1,原点处为 0.5。
该函数的倒数如下:
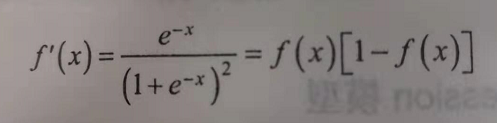
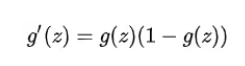
2、逻辑回归公式算法
逻辑回归的数学表达模型:
其中是参数,输出的直观解释:
对于给定的输入
,
时估计的概率
例如:对于肿瘤问题(恶性/良性),输入变量为肿瘤的大小,表示的是病人的肿瘤有70%的可能是恶性的。
较正式的说法可以如下表示:
给定输入,参数化的
(参数空间),
时的概率。数学上可以如下表示:
2.1、损失函数
对数似然损失函数作为逻辑回归的损失函数 。
损失函数为:
前面的可以去掉,化简为:
注意中括号中的公式正是对逻辑回归进行最大似然估计中的最大似然函数
将两个合在一起
有了这个我们可以求出逻辑回归的最大似然函数
对数似然函数为:
对数似然取最大值等价于损失函数取最小值
2.3、正则化
说明:下面中的代价函数Cos(y,β)同2.2中损失函数

2.3 梯度下降法
算法流程:
(1)初始化 (随机初始化)
(2)进行迭代,新的能够使得
更小
(3)如果能够继续减小,返回(2)
其中,称为学习率或步长
这其中最主要的就是求解的梯度,即梯度方向
注意,这个算法和线性回归里的梯度下降算法几乎是一致的,除了的表示不同。
2.4 为什么损失函数不用最小二乘
也就是损失函数为什么不应平方损失而是选择用交叉熵。原因是平方损失在训练的时候会出现一定的问题。当预测值与真实值之间的差距过大时,这时候参数的调整就需要变大,但是如果使用平方损失,训练的时候可能看到的情况是预测值和真实值之间的差距越大,参数调整的越小,训练的越慢。
如果使用平方损失作为损失函数,损失函数如下
其中表示真实值,
表示预测值。
对参数求梯度
由此可以看出,参数除了跟真实值与预测值之间的差距有关外,还和激活函数的该点的导数有关,跟激活函数的梯度成正比,常见的激活函数是
函数,当这个点越靠近上边或者下边的时候梯度会变得非常小,这样会导致当真实值与预测值差距很大时,参数变化的非常缓慢,与我们的期望不符合。
而使用交叉熵损失在更新参数的时候,当误差越大时,梯度也就越大,参数调整也能更大更快。















 9433
9433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









