







原文链接:
机器学习总结(一):线性回归、岭回归、Lasso回归1、线性回归
Scikit-Learn学习笔记——线性回归(基函数回归、岭回归正则化、Lasso正则化)
1.1、线性回归一般形式
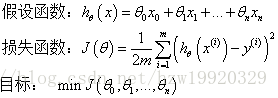
1.2、线性回归可能遇到的问题
- 求解损失函数的最小值有两种方法:梯度下降法以及正规方程。
- 特征缩放:即对特征数据进行归一化操作,进行特征缩放的好处有两点,一是能够提升模型的收敛速度,因为如果特征间的数据相差级别较大的话,以两个特征为例,以这两个特征为横纵坐标绘制等高线图,绘制出来是扁平状的椭圆,这时候通过梯度下降法寻找梯度方向最终将走垂直于等高线的之字形路线,迭代速度变慢。但是如果对特征进行归一化操作之后,整个等高线图将呈现圆形,梯度的方向是指向圆心的,迭代速度远远大于前者。二是能够提升模型精度。
- 学习率α的选取:如果学习率α选取过小,会导致迭代次数变多,收敛速度变慢;学习率α选取过大,有可能会跳过最优解,最终导致根本无法收敛。
1.3、过拟合及其解决办法
当样本特征很多,样本数相对较少时,模型容易陷入过拟合。为了缓解过拟合问题,有两种方法:
方法一:减少特征数量(人工选择重要特征来保留,也可通过PCA算法来实现,会丢弃部分信息)。
方法二:正则化,保留所有特征,但是减少特征前面的参数θ的大小,具体就是修改线性回归中的损失函数形式即可,如岭回归、Lasso回归。
1.4、简单线性回归代码示例
#简单线性回归
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns;sns.set()
rng = np.random.RandomState(42)
x = 10 * rng.rand(50)
y = 2 * x + 5 + rng.randn(50)
#使用Scikit-Learn的LinearRegression评估器来拟合数据,并获得最佳拟合直线
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(x.reshape(-1,1), y)
x_test = np.linspace(-1, 11, 50)
y_test = model.predict(x_test.reshape(-1, 1))
plt.scatter(x, y)
plt.plot(x_test, y_test)
2、正则化(Regularization)
正则化是结构风险(损失函数+正则化项)最小化策略的体现,是在经验风险(平均损失函数)上加一个正则化项。正则化的作用就是选择经验风险和模型复杂度同时较小的模型。
防止过拟合的原理:正则化项一般是模型复杂度的单调递增函数,而经验风险负责最小化误差,使模型偏差尽可能小经验风险越小,模型越复杂,正则化项的值越大。要使正则化项也很小,那么模型复杂程度受到限制,因此就能有效地防止过拟合。
3、线性回归正则化
正则化一般具有如下形式的优化目标:
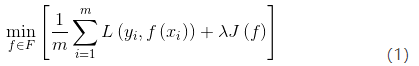
其中,![]() 是用来平衡正则化项和经验风险的系数。
是用来平衡正则化项和经验风险的系数。
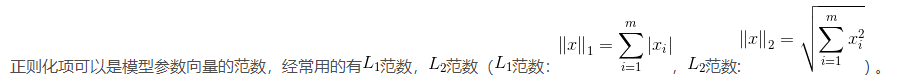
L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为∣∣w∣∣1
- L2正则化是指权值向量w中各个元素的平方和然后再求平方根,通常表示为∣∣w∣∣2
L1正则化和L2正则化的作用:
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
其中,范数正则化、范数正则化都有助于降低过拟合风险,范数通过对参数向量各元素平方和求平方根,使得范数最小,从而使得参数的各个元素接近0 ,但不等于0。
我们考虑最简单的线性回归模型。



4、岭回归求解(Ridge)
岭回归不抛弃任何一个特征,缩小了回归系数,岭回归求解与一般线性回归一致。

岭回归示例代码
#! -*- coding:utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model, model_selection
def load_data():
diabetes = datasets.load_diabetes()
return model_selection.train_test_split(diabetes.data, diabetes.target, test_size=0.25, random_state=0)
def test_lasso(*data):
X_train, X_test, y_train, y_test = data
lassoRegression = linear_model.Lasso()
lassoRegression.fit(X_train, y_train)
print("权重向量:%s, b的值为:%.2f" % (lassoRegression.coef_, lassoRegression.intercept_))
print("损失函数的值:%.2f" % np.mean((lassoRegression.predict(X_test) - y_test) ** 2))
print("预测性能得分: %.2f" % lassoRegression.score(X_test, y_test))
#测试不同的α值对预测性能的影响
def test_lasso_alpha(*data):
X_train, X_test, y_train, y_test = data
alphas = [0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 50, 100, 200, 500, 1000]
scores = []
for i, alpha in enumerate(alphas):
lassoRegression = linear_model.Lasso(alpha=alpha)
lassoRegression.fit(X_train, y_train)
scores.append(lassoRegression.score(X_test, y_test))
return alphas, scores
def show_plot(alphas, scores):
figure = plt.figure()
ax = figure.add_subplot(1, 1, 1)
ax.plot(alphas, scores)
ax.set_xlabel(r"$\alpha$")
ax.set_ylabel(r"score")
ax.set_xscale("log")
ax.set_title("Ridge")
plt.show()
if __name__=='__main__':
X_train, X_test, y_train, y_test = load_data()
# 使用默认的alpha
test_lasso(X_train, X_test, y_train, y_test)
# 使用自己设置的alpha
alphas, scores = test_lasso_alpha(X_train, X_test, y_train, y_test)
show_plot(alphas, scores)
5、LASSO回归求解
由于![]() 范数用的是绝对值,导致LASSO的优化目标不是连续可导的,也就是说,最小二乘法,梯度下降法,牛顿法,拟牛顿法都不能用。
范数用的是绝对值,导致LASSO的优化目标不是连续可导的,也就是说,最小二乘法,梯度下降法,牛顿法,拟牛顿法都不能用。
![]() 正则化问题求解可采用近端梯度下降法(Proximal Gradient Descent,PGD)。
正则化问题求解可采用近端梯度下降法(Proximal Gradient Descent,PGD)。





Lasso回归示例代码:
#! -*- coding:utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model, model_selection
def load_data():
diabetes = datasets.load_diabetes()
return model_selection.train_test_split(diabetes.data, diabetes.target, test_size=0.25, random_state=0)
def test_lasso(*data):
X_train, X_test, y_train, y_test = data
lassoRegression = linear_model.Lasso()
lassoRegression.fit(X_train, y_train)
print("权重向量:%s, b的值为:%.2f" % (lassoRegression.coef_, lassoRegression.intercept_))
print("损失函数的值:%.2f" % np.mean((lassoRegression.predict(X_test) - y_test) ** 2))
print("预测性能得分: %.2f" % lassoRegression.score(X_test, y_test))
#测试不同的α值对预测性能的影响
def test_lasso_alpha(*data):
X_train, X_test, y_train, y_test = data
alphas = [0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 50, 100, 200, 500, 1000]
scores = []
for i, alpha in enumerate(alphas):
lassoRegression = linear_model.Lasso(alpha=alpha)
lassoRegression.fit(X_train, y_train)
scores.append(lassoRegression.score(X_test, y_test))
return alphas, scores
def show_plot(alphas, scores):
figure = plt.figure()
ax = figure.add_subplot(1, 1, 1)
ax.plot(alphas, scores)
ax.set_xlabel(r"$\alpha$")
ax.set_ylabel(r"score")
ax.set_xscale("log")
ax.set_title("Lasso")
plt.show()
if __name__=='__main__':
X_train, X_test, y_train, y_test = load_data()
# 使用默认的alpha
test_lasso(X_train, X_test, y_train, y_test)
# 使用自己设置的alpha
alphas, scores = test_lasso_alpha(X_train, X_test, y_train, y_test)
show_plot(alphas, scores)















 1435
1435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









