









前言
前面讲到只是爬取了title和url,那么怎么爬取文章,其实原理是一样的。
过程
保存文章内容的Item
我们在item.py中添加一项,如下:
class CsdnArticleItem(Item):
title = Field()
article = Field()
pass我们保存文章的题目和内容。
分析文章的链接
csdn是怎么来保存一篇文章的,我们来看一个url:
http://blog.csdn.net/zhx6044/article/details/45698535
http://blog.csdn.net是域名。
zhx6044是作者。
article/details是固定的,那么只是最后的数字不同,所以数字用来索引一篇文章。
更新我们的爬虫
在csdn_crawler.py中的CsdnCrawlerSpider的rules中添加一个对于文章内容的爬取规则,如下:
rules = (
Rule(LinkExtractor(allow=r'article/list/[0-9]{1,20}'), callback='parse_item', follow=True),
Rule(LinkExtractor(allow=r'article/details/[0-9]{1,20}'), callback='parse_article', follow=True),
)然后我们实现一个其处理这个规则链接内容的回调函数。如下:
def parse_article(self, response):
i = CsdnArticleItem()
i['title'] = response.xpath('//*[@id="article_details"]/div[1]/h1/span/a/text()').extract()
i['article'] = response.xpath('//*[@id="article_content"]').extract()
return i使用的还是Chromium浏览器的Copy XPath功能。
在提取文章内容时不好处理,为了实现更好的页面表现效果,其中实现比较复杂,我不能值爬取文字内容,所以现在只能连样式一起爬下来。
这样添加之后,我们的爬虫就可是运行了。
结果
这是其中的一些运行log:
2015-05-16 14:35:51+0800 [csdn_crawler] DEBUG: Filtered duplicate request: <GET http://blog.csdn.net/zhx6044/article/list/3> - no more duplicates will be shown (see DUPEFILTER_DEBUG to show all duplicates)
2015-05-16 14:35:57+0800 [csdn_crawler] DEBUG: Crawled (200) <GET http://blog.csdn.net/zhx6044/article/details/45649045> (referer: http://blog.csdn.net/zhx6044)
2015-05-16 14:35:57+0800 [csdn_crawler] DEBUG: Article add to mongodb database!
其可以看到其爬取了http://blog.csdn.net/zhx6044/article/details/45649045这篇文章。
大家需要注意的是,这个爬虫虽然是从你的blog开始爬取,但是你的博客页面中还会包含其它人的链接,比如在推荐文章这一栏,如图:
这是你可以在添加爬取规则时添加上限制,比如:
Rule(LinkExtractor(allow=r'zhx6044/article/details/[0-9]{1,20}'), callback='parse_article', follow=True),
就可以了,不然你会发现你的爬虫根本停不下来。
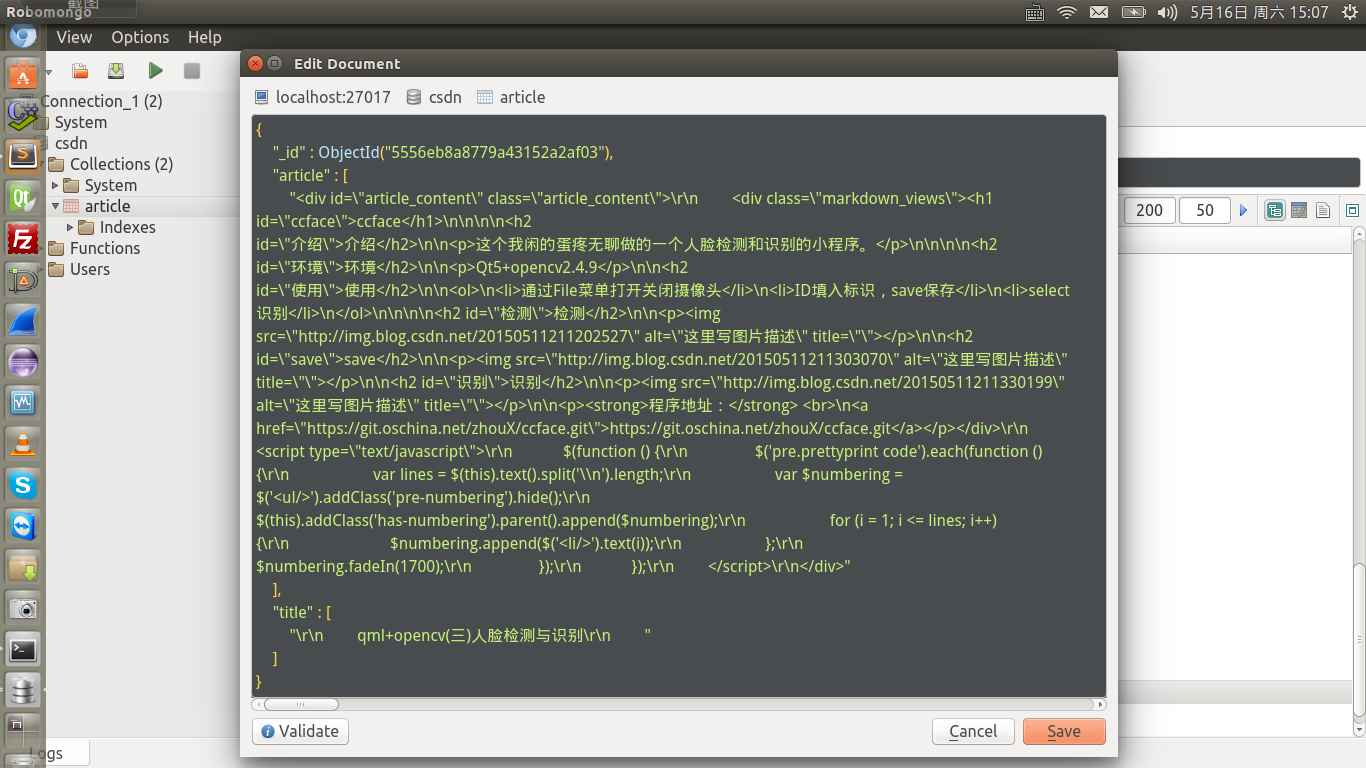
这是我爬取到的数据,文章内容有点乱。















 1853
1853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









