







谨以此篇献给刚刚步入程序员序列的年轻人,和励志写好代码的攻城狮,共勉。
亲爱的Niki伙伴:
祝贺你开启职业生涯的新篇章!在这个技术浪潮奔涌向前的时代,你选择以程序员的身份踏入行业,既是勇气的彰显,也是智慧的抉择。此刻想与你分享几点建议,愿你在代码世界的探索中步履坚定、行稳致远。
保持纯粹热爱,做技术的长期主义者。编程不仅是谋生的工具,更是创造价值的艺术。当你在代码中实现一个精妙算法,或是用代码构建出能改变用户体验的功能时,希望这份成就感能成为你持续深耕的动力。技术领域日新月异,唯有对知识的渴望和对创新的热情,能支撑你跨越版本迭代、技术更新的重重挑战。
深耕专业,锻造核心竞争力。初入职场,面对复杂的项目与陌生的技术栈,要保持谦逊的学习态度。多阅读优秀代码,参与开源项目,系统性构建知识体系;在日常工作中,主动思考代码的可维护性、扩展性,培养架构思维。同时,注重软技能的提升,清晰的逻辑表达、高效的团队协作能力,会让你的技术价值得到更充分的释放。
直面挫折,在磨砺中成长。调试时的 Bug、需求变更的压力、技术难题的瓶颈,都是成长路上的必修课。遇到困难时,不妨把它视为突破认知边界的契机。尝试拆解问题,向同事请教经验,或是从社区中寻找解决方案。请相信,每一次与困难的交锋,都是对技术能力和心智韧性的双重锤炼。
未来的编程之路或许布满荆棘,但请记得,那些深夜调试的专注、攻克难题后的喜悦,终将沉淀为你独特的职业勋章。愿你始终怀揣热忱,在代码的世界里披荆斩棘,书写属于自己的技术传奇!
目录
1. [简介](#简介)
2. [变量](#变量)
3. [函数](#函数)
4. [对象和数据结构](#对象和数据结构)
5. [类](#类)
6. [SOLID](#solid)
7. [测试](#测试)
8. [错误处理](#错误处理)
9. [格式化](#格式化)
10. [注释](#注释)
11. [工具](#工具)
12. 对象和数据结构
13. 死锁
14.并发
简介
这里的每一项原则都不是必须遵守的, 甚至只有更少的能够被广泛认可。 这些仅仅是指南而已, 但是却是
*Clean Code* 作者多年经验的结晶。
我们的软件工程行业只有短短的 50 年, 依然有很多要我们去学习。 当软件架构与建筑架构一样古老时,
也许我们将会有硬性的规则去遵守。 而现在, 让这些指南做为你和你的团队生产的C# 代码的
质量的标准。
还有一件事: 知道这些指南并不能马上让你成为一个更加出色的软件开发者, 并且使用它们工作多年也并
不意味着你不再会犯错误。 每一段代码最开始都是草稿, 像湿粘土一样被打造成最终的形态。 最后当我们
和搭档们一起审查代码时清除那些不完善之处, 不要因为最初需要改善的草稿代码而自责, 而是对那些代
码下手。
让我们先看看编程大师Robert C. Martin的杰作《[Clean Code](http://t.cn/zHPF56e)》里的一句话:
> “注释的目的是为了弥补代码自身在表达上的不足。”
这句话可以简单的理解为**如果你的代码需要注释,最有可能是你的代码写的很烂。**同样,如果在没有注释的情况下你无法用**代码**完整的表达你对一个问题或一个算法的思路,那这就是一个失败的信号。最终,这意味着你需要用注释来阐明一部分的思想,而这部分在**代码**里是看不出来的。**好的代码能够让任何人在不需要任何注释的情况下看懂。**好的编码风格能将所有有助于理解这个问题的所有信息都蕴含在**代码**里。
命名
为什么我们选择使用C#、Java和Python等现代编程语言,而非古老的汇编语言呢?
这背后的原因之一是这些语言与自然语言更为接近。或者说,它们更有可能被我们赋予自然语言的特性。毕竟,有时我们编写代码的目的仅仅是为了让它能够运行,而忽略了向他人展示我们正在做什么的重要性。然而,这种忽视往往会在未来给我们带来意想不到的困扰,尤其是当那个“他人”是我们自己的时候。
为了编写更易读、易懂的代码,我们可以尝试使用词性命名法。通过让代码尽可能地像英语,我们可以将其转化为一个富有故事性的描述。这意味着我们需要智能地为故事中的实体和动作命名,从而清晰地表达代码的流程。
```c#
/// <summary>
/// 扫码信号枚举
/// </summary>
public enum ScanSignal : int
{
NONE = 1, Excute = 2
}
/// <summary>
/// 扫码状态枚举
/// </summary>
public enum ScanState : int
{
None = 1,
OK = 2,
Fault = 3
}
```
旧的
```c#
if (trueValue == (int)ScanState.None)
{
signalObject.Value = (int)ScanState.None;
WriteCommand(signalObject);
}
else if (trueValue == Convert.ToInt32(ScanState.OK))
{
signalObject.Value = (int)ScanState.OK;
WriteCommand(signalObject);
map.Add("State", trueValue);
OnCommonEvent?.Invoke(this, map);
}
```
新的
```c#
if (trueValue == (int)ScanSignal.None)
{
signalObject.Value = (int)ScanState.None;
WriteCommand(signalObject);
}
else if (trueValue == Convert.ToInt32(ScanSignal.Excute))
{
signalObject.Value = (int)ScanState.OK;
WriteCommand(signalObject);
map.Add("State", trueValue);
OnCommonEvent?.Invoke(this, map);
}
```
**核心原则**
- **KISS原则**: Keep It Simple, Stupid(保持简单)
- **DRY原则**: Don't Repeat Yourself(不要重复自己)
- **YAGNI原则**: You Aren't Gonna Need It(你不会需要它)
- **SOLID原则**: 单一职责、开闭原则、里氏替换、接口隔离、依赖倒置。
```c#
- **单一职责原则**: 一个类只负责一个功能。
- **开闭原则**: 对扩展开放,对修改关闭。
- **里氏替换原则**: 子类应该可以替换父类。
- **接口隔离原则**: 使用多个专门的接口,而不是一个臃肿的接口。
- **依赖倒置原则**: 依赖于抽象,而不是具体实现。
```
**代码整洁的重要性**
**可读性**: 代码是写给人看的,其次才是机器,任何人阅读代码时都能够迅速理解其意图。
**简洁性**:代码不冗余,所有内容都是必要的,没有多余的部分。
**一致性**:代码风格统一,遵循一致的命名规则和编写规范。
**可维护性**: 整洁的代码更容易修改和扩展。
**减少错误**: 清晰的代码结构有助于减少潜在的错误。
**团队协作**: 整洁的代码有助于团队合作和知识传递。
命名的重要性
命名在代码整洁中起着至关重要的作用。好的命名能够显著提高代码的可读性和可理解性。书中提到的命名原则包括:
1. **名副其实**:名称应该清晰地反映其含义。例如,用 `elapsedTimeInDays` 表示时间间隔,而不是简单地用 `d`。
2. **避免误导**:不要使用与实际功能不符的名称。例如,不要用 `accountList` 表示一个不是列表的数据结构。
3. **有意义的区分**:避免仅通过数字或不相关的词语来区分名称。例如,用 `source` 和 `target` 比用 `data1` 和 `data2` 更有意义。
4. **使用可读的名称**:如 `generationTimestamp` 比 `genymdhms` 更容易理解。
5. **避免编码**:不要在变量名中使用前缀或其他编码方式。
6. **避免思维映射**:在循环体中,使用 `i`、`j` 或 `k` 作为循环变量比使用其他字母更好。
函数设计
书中提到,函数应该尽量短小且只做一件事。每个函数应在一个抽象层级上,确保其内容易于理解。函数名应具有描述性,并避免使用过多参数。理想的函数参数个数为零,其次是一,再次是二,应尽量避免使用三参数函数。函数的设计原则包括:
1. **单一职责**:每个函数只做一件事,并且做得很好。
2. **简短**:函数应该足够短,最好能在一个屏幕内显示完毕。
3. **减少嵌套**:尽量减少嵌套层级,使代码更扁平、更易读。
4. **函数名描述行为**:函数名应明确描述其功能,例如 `calculateSum` 比 `calc` 更清晰。
注释的使用
注释是代码的一部分,但注释的存在并不能弥补糟糕的代码。好的注释应该补充代码的不足,提供必要的上下文和解释。马丁提到,注释的最佳实践包括:
1. **解释意图**:注释应解释代码的意图,而不是描述代码的行为。
2. **提供背景信息**:在代码中使用专业术语或业务逻辑时,注释应提供背景信息。
3. **警示潜在问题**:在代码中标记潜在的陷阱或需要注意的问题。
4. **避免多余注释**:注释不应重复代码本身已经表达的信息。
格式和布局
整洁的代码不仅仅在于逻辑和结构,还包括代码的格式和布局。书中强调了保持代码一致性和良好格式的重要性,包括:
1. **一致的缩进**:使用一致的缩进风格,使代码层次结构清晰。
2. **适当的空行**:通过空行分隔逻辑块,提高代码的可读性。
3. **对齐**:对齐相关代码元素,使代码更整洁。
测试驱动开发(TDD)
《代码整洁之道》中提到,测试驱动开发(TDD)是一种确保代码质量的重要方法。通过先编写测试,再编写实现代码,可以有效减少缺陷,提高代码的可靠性。TDD 的原则包括:
1. **先写测试**:在编写功能代码之前,先编写相应的测试用例。
2. **小步快跑**:每次只进行小幅度的代码修改,并立即运行测试。
3. **重构**:在确保测试通过的前提下,不断重构代码,使其更简洁、更高效。
重构
重构是改善代码结构的重要手段,马丁在书中强调了重构的必要性和方法。重构不仅可以提高代码的可读性和可维护性,还可以减少技术债务。重构的最佳实践包括:
1. **小步重构**:每次只进行小规模的修改,确保改动不会引入新的问题。
2. **频繁提交**:在每次重构后及时提交代码,以便跟踪和回退。
3. **保持代码功能不变**:重构应在不改变代码外部行为的前提下进行。
**关键实践**
- 命名: 使用有意义的变量名、函数名和类名。
- 函数设计: 函数应短小、单一职责、避免副作用。
- **注释**: 避免冗余注释,注释应解释“为什么”而不是“是什么”。
- 格式: 一致的代码格式有助于提高可读性。
- 错误处理: 使用异常而不是返回错误码,避免忽略错误。
**个人感悟**
- **代码是艺术**: 编写代码不仅仅是完成任务,更是一种艺术表达。
- **持续改进**: 代码整洁是一个持续的过程,需要不断反思和改进。
- **团队文化**: 代码整洁不仅仅是个人习惯,团队文化也至关重要。
- **工具辅助**: 使用代码格式化工具、静态分析工具等可以帮助保持代码整洁。
**变量**
使用有意义并且可读的变量名称
**不好的:**
```
String yyyymmdstr = DateTime.Now.ToString("yyyyMMdd HH:mm:ss");
```
**好的:**
```
String currentDate = DateTime.Now.ToString("yyyyMMdd HH:mm:ss");
```
为相同类型的变量使用相同的词汇
**不好的:**
```c#
// 不好的命名
int studentCount = 10;
int numberOfTeachers = 5;
int totalCourses = 20;
```
**好的:**
```c#
//xxxCount
int studentCount = 10;
int teacherCount = 5;
int courseCount = 20;
```
我们要阅读的代码比要写的代码多得多, 所以我们写出的代码的可读性和可搜索性是很重要的。 使用没有
意义的变量名将会导致我们的程序难于理解, 将会伤害我们的读者, 所以请使用可搜索的变量名。
**不好的:**
```
// 艹, 86400000 是什么鬼?
setTimeout(blastOff, 86400000);
```
**好的:**
```
// 将它们声明为全局常量。
public static final int MILLISECONDS_IN_A_DAY = 86400000;
setTimeout(blastOff, MILLISECONDS_IN_A_DAY);
```
使用解释性的变量
**不好的:**
```c#
String address = "One Infinite Loop, Cupertino 95014";
String cityZipCodeRegex = "/^[^,\\\\]+[,\\\\\\s]+(.+?)\\s*(\\d{5})?$/";
saveCityZipCode(address.split(cityZipCodeRegex)[0],
address.split(cityZipCodeRegex)[1]);
```
**好的:**
```
String address = "One Infinite Loop, Cupertino 95014";
String cityZipCodeRegex = "/^[^,\\\\]+[,\\\\\\s]+(.+?)\\s*(\\d{5})?$/";
String city = address.split(cityZipCodeRegex)[0];
String zipCode = address.split(cityZipCodeRegex)[1];
saveCityZipCode(city, zipCode);
```
避免心理映射
显示比隐式更好
**不好的:**
```c#
String [] l = {"Austin", "New York", "San Francisco"};
for (int i = 0; i < l.length; i++) {
String li = l[i];
doStuff();
doSomeOtherStuff();
// ...
// ...
// ...
// Wait, what is `$li` for again?
dispatch(li);
}
```
**好的:**
```
String[] locations = {"Austin", "New York", "San Francisco"};
for (String location : locations) {
doStuff();
doSomeOtherStuff();
// ...
// ...
// ...
dispatch(location);
}
```
不添加不必要的上下文
如果你的类名/对象名有意义, 不要在变量名上再重复。
**不好的:**
```
class Car {
public String carMake = "Honda";
public String carModel = "Accord";
public String carColor = "Blue";
}
void paintCar(Car car) {
car.carColor = "Red";
}
```
**好的:**
```
class Car {
public String make = "Honda";
public String model = "Accord";
public String color = "Blue";
}
void paintCar(Car car) {
car.color = "Red";
}
```
为相同类型的变量使用相同的词汇是一种良好的编程实践,它可以提高代码的可读性、一致性和可维护性。以下是一些具体的建议和示例,帮助你在C#中实现这一点:
---
```csharp
不好的命名
int studentCount = 10;
int numberOfTeachers = 5;
int totalCourses = 20;
// 好的命名
int studentCount = 10;
int teacherCount = 5;
int courseCount = 20;
```
---
2. **集合类型的命名**
对于集合类型(如列表、数组、字典),使用一致的命名模式。
示例:
```csharp
// 不好的命名
List<string> studentNames = new List<string>();
string[] teacherNamesArray = new string[5];
Dictionary<int, string> courseIdToNameMap = new Dictionary<int, string>();
// 好的命名
List<string> students = new List<string>();
string[] teachers = new string[5];
Dictionary<int, string> courses = new Dictionary<int, string>();
```
---
3. **布尔变量的命名**
布尔变量通常表示某种状态或条件,命名时应使用清晰的前缀(如`is`、`has`、`can`)。
示例:
```csharp
// 不好的命名
bool active = true;
bool available = false;
// 好的命名
bool isActive = true;
bool isAvailable = false;
```
---
4. **方法参数的命名**
方法参数应与调用方传递的变量名保持一致。
示例:
```csharp
// 不好的命名
public void PrintStudentDetails(string name, int age)
{
Console.WriteLine($"Name: {name}, Age: {age}");
}
string studentName = "Alice";
int studentAge = 20;
PrintStudentDetails(studentName, studentAge);
// 好的命名
public void PrintStudentDetails(string name, int age)
{
Console.WriteLine($"Name: {name}, Age: {age}");
}
string name = "Alice";
int age = 20;
PrintStudentDetails(name, age);
```
---
5. **领域模型中的命名**
在领域驱动设计(DDD)中,确保领域模型中的变量命名与业务术语一致。
示例:
```csharp
// 不好的命名
public class Order
{
public int OrderId { get; set; }
public DateTime OrderDate { get; set; }
public decimal TotalAmount { get; set; }
}
// 好的命名
public class Order
{
public int Id { get; set; } // 使用 Id 而不是 OrderId
public DateTime Date { get; set; } // 使用 Date 而不是 OrderDate
public decimal Total { get; set; } // 使用 Total 而不是 TotalAmount
}
```
---
6. **常量的命名**
常量通常使用全大写字母和下划线分隔单词。
示例:
```csharp
// 不好的命名
const int maxStudents = 100;
const double piValue = 3.14;
// 好的命名
const int MAX_STUDENTS = 100;
const double PI = 3.14;
```
---
7. **避免缩写**
除非是广泛接受的缩写(如`id`、`url`),否则避免使用缩写。
示例:
```csharp
// 不好的命名
int empCnt = 10;
string custName = "John";
// 好的命名
int employeeCount = 10;
string customerName = "John";
```
---
8. **使用有意义的名称**
变量名应清晰地表达其用途,避免使用泛泛的名称(如`data`、`value`)。
示例:
```csharp
// 不好的命名
var data = GetStudentData();
var value = CalculateTotal();
// 好的命名
var students = GetStudents();
var totalPrice = CalculateTotalPrice();
```
---
9. **遵循团队约定**
如果团队有特定的命名约定(如前缀、后缀),请确保遵循这些约定。
示例:
```csharp
// 团队约定:私有字段使用下划线前缀
private int _studentCount;
// 团队约定:接口名称以 I 开头
public interface IStudentRepository
{
void Add(Student student);
}
```
为相同类型的变量使用相同的词汇可以提高代码的一致性和可读性。通过遵循命名约定、使用有意义的名称以及借助工具支持,你可以编写出更整洁、更易维护的代码。
函数**
函数参数 (两个以下最理想)
限制函数参数的个数是非常重要的, 因为这样将使你的函数容易进行测试。 一旦超过三个参数将会导致组
合爆炸, 因为你不得不编写大量针对每个参数的测试用例。
没有参数是最理想的, 一个或者两个参数也是可以的, 三个参数应该避免, 超过三个应该被重构。 通常,
如果你有一个超过两个函数的参数, 那就意味着你的函数尝试做太多的事情。 如果不是, 多数情况下一个
更高级对象可能会满足需求。
当你发现你自己需要大量的参数时, 你可以使用一个对象。
**不好的:**
```
void createMenu(String title,String body,String buttonText,boolean cancellable){}
```
**好的**:
```
class MenuConfig{
String title;
String body;
String buttonText;
boolean cancellable;
}
void createMenu(MenuConfig menuConfig){}
```
函数应当只做一件事情
这是软件工程中最重要的一条规则, 当函数需要做更多的事情时, 它们将会更难进行编写、 测试和推理。
当你能将一个函数隔离到只有一个动作, 他们将能够被容易的进行重构并且你的代码将会更容易阅读。 如
果你严格遵守本指南中的这一条, 你将会领先于许多开发者。
**不好的:**
```
public void emailClients(List<Client> clients) {
for (Client client : clients) {
Client clientRecord = repository.findOne(client.getId());
if (clientRecord.isActive()){
email(client);
}
}
}
```
**好的:**
```
public void emailClients(List<Client> clients) {
for (Client client : clients) {
if (isActiveClient(client)) {
email(client);
}
}
}
private boolean isActiveClient(Client client) {
Client clientRecord = repository.findOne(client.getId());
return clientRecord.isActive();
}
```
函数名称应该说明它要做什么
**不好的:**
```
private void addToDate(Date date, int month){
//..
}
Date date = new Date();
// It's hard to to tell from the method name what is added
addToDate(date, 1);
```
**好的:**
```
private void addMonthToDate(Date date, int month){
//..
}
Date date = new Date();
addMonthToDate(1, date);
```
函数应该只有一个抽象级别
当在你的函数中有多于一个抽象级别时, 你的函数通常做了太多事情。 拆分函数将会提升重用性和测试性。
**不好的:**
```
void parseBetterJSAlternative(String code){
String[] REGECES={};
String[] statements=code.split(" ");
String[] tokens={};
for(String regex: Arrays.asList(REGECES)){
for(String statement:Arrays.asList(statements)){
//...
}
}
String[] ast={};
for(String token:Arrays.asList(tokens)){
//lex ...
}
for(String node:Arrays.asList(ast)){
//parse ...
}
}
```
**好的:**
```
String[] tokenize(String code){
String[] REGECES={};
String[] statements=code.split(" ");
String[] tokens={};
for(String regex: Arrays.asList(REGECES)){
for(String statement:Arrays.asList(statements)){
//tokens push
}
}
return tokens;
}
String[] lexer(String[] tokens){
String[] ast={};
for(String token:Arrays.asList(tokens)){
//ast push
}
return ast;
}
void parseBetterJSAlternative(String code){
String[] tokens=tokenize(code);
String[] ast=lexer(tokens);
for(String node:Arrays.asList(ast)){
//parse ...
}
}
```
移除冗余代码
竭尽你的全力去避免冗余代码。 冗余代码是不好的, 因为它意味着当你需要修改一些逻辑时会有多个地方
需要修改。
想象一下你在经营一家餐馆, 你需要记录所有的库存西红柿, 洋葱, 大蒜, 各种香料等等。 如果你有多
个记录列表, 当你用西红柿做一道菜时你得更新多个列表。 如果你只有一个列表, 就只有一个地方需要更
新!
你有冗余代码通常是因为你有两个或多个稍微不同的东西, 它们共享大部分, 但是它们的不同之处迫使你使
用两个或更多独立的函数来处理大部分相同的东西。 移除冗余代码意味着创建一个可以处理这些不同之处的
抽象的函数/模块/类。
让这个抽象正确是关键的, 这是为什么要你遵循 *Classes* 那一章的 SOLID 的原因。 不好的抽象比冗
余代码更差, 所以要谨慎行事。 既然已经这么说了, 如果你能够做出一个好的抽象, 才去做。 不要重复
你自己, 否则你会发现当你要修改一个东西时时刻需要修改多个地方。
**不好的:**
```
void showDeveloperList(List<Developer> developers){
for(Developer developer:developers){
render(new Data(developer.expectedSalary,developer.experience,developer.githubLink));
}
}
void showManagerrList(List<Manager> managers){
for(Manager manager:managers){
render(new Data(manager.expectedSalary,manager.experience,manager.portfolio));
}
}
```
**好的:**
```
void showList(List<Employee> employees){
for(Employee employee:employees){
Data data=new Data(employee.expectedSalary,employee.experience,employee.githubLink);
String portfolio=employee.portfolio;
if("manager".equals(employee)){
portfolio=employee.portfolio;
}
data.portfolio=portfolio;
render(data);
}
}
```
不要使用标记位做为函数参数
标记位是告诉你的用户这个函数做了不只一件事情。 函数应该只做一件事情。 如果你的函数因为一个布尔值
出现不同的代码路径, 请拆分它们。
**不好的:**
```
void createFile(String name,boolean temp){
if(temp){
new File("./temp"+name);
}else{
new File(name);
}
}
```
**好的:**
```
void createFile(String name){
new File(name);
}
void createTempFile(String name){
new File("./temp"+name);
}
```
避免副作用
如果一个函数做了除接受一个值然后返回一个值或多个值之外的任何事情, 它将会产生副作用, 它可能是
写入一个文件, 修改一个全局变量, 或者意外的把你所有的钱连接到一个陌生人那里。
现在在你的程序中确实偶尔需要副作用, 就像上面的代码, 你也许需要写入到一个文件, 你需要做的是集
中化你要做的事情, 不要让多个函数或者类写入一个特定的文件, 用一个服务来实现它, 一个并且只有一
个。
重点是避免这些常见的易犯的错误, 比如在对象之间共享状态而不使用任何结构, 使用任何地方都可以写入
的可变的数据类型, 没有集中化导致副作用。 如果你能做到这些, 那么你将会比其它的码农大军更加幸福。
**不好的:**
```
String name="Ryan McDermott";
void splitIntoFirstAndLastName(){
name=name.split(" ").toString();
}
splitIntoFirstAndLastName();
System.out.println(name);
```
**好的:**
```
String name="Ryan McDermott";
String splitIntoFirstAndLastName(){
return name.split(" ").toString();
}
String newName=splitIntoFirstAndLastName();
System.out.println(name);
System.out.println(newName);
```
函数式编程优于指令式编程
函数式语言更加简洁
并且更容易进行测试, 当你可以使用函数式编程风格时请尽情使用。
**不好的:**
```
List<Integer> programmerOutput=new ArrayList<>();
programmerOutput.add(500);
programmerOutput.add(1500);
programmerOutput.add(150);
programmerOutput.add(1000);
int totalOutput=0;
for(int i=0;i<programmerOutput.size();i++){
totalOutput+=programmerOutput.get(i);
}
```
**好的:**
```
List<Integer> programmerOutput=new ArrayList<>();
programmerOutput.add(500);
programmerOutput.add(1500);
programmerOutput.add(150);
programmerOutput.add(1000);
int totalOutput= programmerOutput.stream().filter(programmer -> programmer > 500).mapToInt(programmer -> programmer).sum();
```
封装条件语句
**不好的:**
```
if(fsm.state.equals("fetching")&&listNode.isEmpty(){
//...
}
```
**好的:**
```
void shouldShowSpinner(Fsm fsm, String listNode) {
return fsm.state.equals("fetching")&&listNode.isEmpty();
}
if (shouldShowSpinner(fsmInstance, listNodeInstance)) {
// ...
}
```
避免负面条件
**不好的:**
```
void isDOMNodeNotPresent(Node node) {
// ...
}
if (!isDOMNodeNotPresent(node)) {
// ...
}
```
**好的:**
```
void isDOMNodePresent(Node node) {
// ...
}
if (isDOMNodePresent(node)) {
// ...
}
```
避免条件语句
这看起来似乎是一个不可能的任务。 第一次听到这个时, 多数人会说: “没有 `if` 语句还能期望我干
啥呢”, 答案是多数情况下你可以使用多态来完成同样的任务。 第二个问题通常是 “好了, 那么做很棒,
但是我为什么想要那样做呢”, 答案是我们学到的上一条代码整洁之道的理念: 一个函数应当只做一件事情。
当你有使用 `if` 语句的类/函数是, 你在告诉你的用户你的函数做了不止一件事情。 记住: 只做一件
事情。
**不好的:**
```
class Airplane{
int getCurisingAltitude(){
switch(this.type){
case "777":
return this.getMaxAltitude()-this.getPassengerCount();
case "Air Force One":
return this.getMaxAltitude();
case "Cessna":
return this.getMaxAltitude() - this.getFuelExpenditure();
}
}
}
```
**好的:**
```
class Airplane {
// ...
}
class Boeing777 extends Airplane {
// ...
int getCruisingAltitude() {
return this.getMaxAltitude() - this.getPassengerCount();
}
}
class AirForceOne extends Airplane {
// ...
int getCruisingAltitude() {
return this.getMaxAltitude();
}
}
class Cessna extends Airplane {
// ...
int getCruisingAltitude() {
return this.getMaxAltitude() - this.getFuelExpenditure();
}
}
```
移除僵尸代码
僵死代码和冗余代码同样糟糕。 没有理由在代码库中保存它。 如果它不会被调用, 就删掉它。 当你需要
它时, 它依然保存在版本历史记录中。
**不好的:**
```
void oldRequestModule(String url) {
// ...
}
void newRequestModule(String url) {
// ...
}
String req = newRequestModule;
inventoryTracker("apples", req, "www.inventory-awesome.io");
```
**好的:**
```
void newRequestModule(String url) {
// ...
}
String req = newRequestModule;
inventoryTracker("apples", req, "www.inventory-awesome.io");
```
**对象和数据结构**
使用 getters 和 setters
使用 getters 和 setters 来访问对象上的数据比简单的在一个对象上查找属性
要好得多。 “为什么?” 你可能会问, 好吧, 原因请看下面的列表:
* 当你想在获取一个对象属性的背后做更多的事情时, 你不需要在代码库中查找和修改每一处访问;
* 使用 `set` 可以让添加验证变得容易;
* 封装内部实现;
* 使用 getting 和 setting 时, 容易添加日志和错误处理;
* 继承这个类, 你可以重写默认功能;
* 你可以延迟加载对象的属性, 比如说从服务器获取。
**不好的:**
```
class BankAccount{
public int balance=1000;
}
BankAccount bankAccount=new BankAccount();
bankAccount.balance-=100;
```
**好的:**
```
class BankAccount{
private int blance=1000;
public int getBlance() {
return blance;
}
public void setBlance(int blance) {
if(verifyIfAmountCanBeSetted(blance)){
this.blance = blance;
}
}
void verifyIfAmountCanBeSetted(int amount){
//...
}
}
BankAccount bankAccount=new BankAccount();
bankAccount.setBlance(2000);
int balance=bankAccount.getBlance();
```
**类**
使用方法链
这个模式在C# 中是非常有用的, 并且你可以在许多类库比如 Glide 和 OkHttp 中见到。
它使你的代码变得富有表现力, 并减少啰嗦。 因为这个原因, 我说, 使用方法链然后再看看你的代码
会变得多么简洁。 在你的类/方法中, 简单的在每个方法的最后返回 `this` , 然后你就能把这个类的
其它方法链在一起。
**不好的:**
```c#
class Car{
private String make;
private String model;
private String color;
public void setMake(String make) {
this.make = make;
}
public void setModel(String model) {
this.model = model;
}
public void setColor(String color) {
this.color = color;
}
public void save(){
console.log(this.make, this.model, this.color);
}
}
Car car=new Car();
car.setColor("pink");
car.setMake("Ford");
car.setModel("F-150");
car.save();
```
**好的:**
```
class Car{
private String make;
private String model;
private String color;
public Car setMake(String make) {
this.make = make;
return this;
}
public Car setModel(String model) {
this.model = model;
return this;
}
public Car setColor(String color) {
this.color = color;
return this;
}
public Car save(){
console.log(this.make, this.model, this.color);
return this;
}
}
Car car=new Car()
.setColor("pink")
.setMake("Ford")
.setModel("F-150")
.save();
```
组合优先于继承
正如[*设计模式四人帮*](https://en.wikipedia.org/wiki/Design_Patterns)所述, 如果可能,
你应该优先使用组合而不是继承。 有许多好的理由去使用继承, 也有许多好的理由去使用组合。这个格言
的重点是, 如果你本能的观点是继承, 那么请想一下组合能否更好的为你的问题建模。 很多情况下它真的
可以。
那么你也许会这样想, “我什么时候改使用继承?” 这取决于你手上的问题, 不过这儿有一个像样的列表说
明什么时候继承比组合更好用:
1. 你的继承表示"是一个"的关系而不是"有一个"的关系(人类->动物 vs 用户->用户详情);
2. 你可以重用来自基类的代码(人可以像所有动物一样行动);
3. 你想通过基类对子类进行全局的修改(改变所有动物行动时的热量消耗);
**不好的:**
```
class Employee{
private String name;
private String email;
}
// 不好是因为雇员“有”税率数据, EmployeeTaxData 不是一个 Employee 类型。
class EmployeeTaxData extends Employee{
private String ssn;
private String salary;
}
```
**好的:**
```
class EmployeeTaxData{
private String ssn;
private String salary;
public EmployeeTaxData(String ssn, String salary) {
this.ssn = ssn;
this.salary = salary;
}
}
class Employee{
private String name;
private String email;
private EmployeeTaxData taxData;
void setTaxData(String ssn,String salary){
this.taxData=new EmployeeTaxData(ssn,salary);
}
}
```
**SOLID**
单一职责原则 (SRP)
正如代码整洁之道所述, “永远不要有超过一个理由来修改一个类”。 给一个类塞满许多功能, 就像你在航
班上只能带一个行李箱一样, 这样做的问题你的类不会有理想的内聚性, 将会有太多的理由来对它进行修改。
最小化需要修改一个类的次数时很重要的, 因为如果一个类拥有太多的功能, 一旦你修改它的一小部分,
将会很难弄清楚会对代码库中的其它模块造成什么影响。
**不好的:**
```
class UserSettings {
User user;
void changeSettings(UserSettings settings) {
if (this.verifyCredentials()) {
// ...
}
}
void verifyCredentials() {
// ...
}
}
```
**好的:**
```
User user;
UserAuth auth;
public UserSettings(User user) {
this.user = user;
this.auth = new UserAuth(user);
}
void changeSettings(UserSettings settings) {
if (this.auth.verifyCredentials()) {
// ...
}
}
```
开闭原则 (OCP)
Bertrand Meyer 说过, “软件实体 (类, 模块, 函数等) 应该为扩展开放, 但是为修改关闭。” 这
是什么意思呢? 这个原则基本上说明了你应该允许用户添加功能而不必修改现有的代码。
**不好的:**
```
class AjaxAdapter extends Adapter {
private String name;
public AjaxAdapter() {
this.name = "ajaxAdapter";
}
}
class NodeAdapter extends Adapter {
private String name;
public NodeAdapter() {
this.name = "nodeAdapter";
}
}
class HttpRequester {
public HttpRequester(Adapter adapter) {
this.adapter = adapter;
}
void fetch(String url) {
if ("ajaxAdapter".equals(this.adapter.name)) {
makeAjaxCall(url);
} else if ("httpNodeAdapter".equals(this.adapter.name)) {
makeHttpCall(url);
}
}
}
void makeAjaxCall(String url) {
// request and return promise
}
void makeHttpCall(String url) {
// request and return promise
}
```
**好的:**
```
class AjaxAdapter extends Adapter {
private String name;
public AjaxAdapter() {
this.name = "ajaxAdapter";
}
void request(String url){
}
}
class NodeAdapter extends Adapter {
private String name;
public NodeAdapter() {
this.name = "nodeAdapter";
}
void request(String url){
}
}
class HttpRequester {
public HttpRequester(Adapter adapter) {
this.adapter = adapter;
}
void fetch(String url) {
this.adapter.request(url);
}
}
```
**开闭原则(Open/Closed Principle, OCP)** 是面向对象设计中的五大原则之一(SOLID原则中的“O”)。它的核心思想是:
> **软件实体(类、模块、函数等)应该对扩展开放,对修改关闭。**
换句话说,当需求发生变化时,应该通过扩展现有代码来实现新功能,而不是修改已有的代码。这样可以减少对现有代码的影响,降低引入新错误的风险,同时提高代码的可维护性和可扩展性。
---
开闭原则的核心思想:
1. **对扩展开放**:当需求变化时,可以通过添加新的代码来扩展系统的功能。
2. **对修改关闭**:已有的代码应该尽量保持不变,避免直接修改。
---
在C#中的应用:
在C#中,开闭原则通常通过以下方式实现:
1. **使用抽象(抽象类或接口)**:通过定义抽象层,将具体实现与客户端代码解耦。
2. **依赖倒置原则**:依赖于抽象,而不是具体实现。
3. **使用设计模式**:如策略模式、工厂模式、装饰器模式等,来支持扩展。
---
示例:未遵循开闭原则的代码
以下代码未遵循开闭原则,当需要添加新的形状时,必须修改 `AreaCalculator` 类。
```csharp
public class Rectangle
{
public double Width { get; set; }
public double Height { get; set; }
}
public class Circle
{
public double Radius { get; set; }
}
public class AreaCalculator
{
public double CalculateArea(object shape)
{
if (shape is Rectangle)
{
var rectangle = (Rectangle)shape;
return rectangle.Width * rectangle.Height;
}
else if (shape is Circle)
{
var circle = (Circle)shape;
return Math.PI * circle.Radius * circle.Radius;
}
throw new ArgumentException("Unknown shape");
}
}
```
**问题**:
- 每次添加新形状时,都需要修改 `AreaCalculator` 类。
- 违反了开闭原则,代码难以扩展。
---
示例:遵循开闭原则的代码
通过引入抽象(接口或抽象类),我们可以使代码对扩展开放,对修改关闭。
```csharp
// 定义抽象类或接口
public abstract class Shape
{
public abstract double CalculateArea();
}
// 具体实现
public class Rectangle : Shape
{
public double Width { get; set; }
public double Height { get; set; }
public override double CalculateArea()
{
return Width * Height;
}
}
public class Circle : Shape
{
public double Radius { get; set; }
public override double CalculateArea()
{
return Math.PI * Radius * Radius;
}
}
// 计算面积的类
public class AreaCalculator
{
public double CalculateArea(Shape shape)
{
return shape.CalculateArea();
}
}
```
**改进点**:
1. **抽象层**:通过 `Shape` 抽象类定义了一个通用的 `CalculateArea` 方法。
2. **扩展性**:当需要添加新形状时,只需继承 `Shape` 并实现 `CalculateArea` 方法,而无需修改 `AreaCalculator` 类。
3. **符合开闭原则**:对扩展开放,对修改关闭。
---
示例:添加新形状
假设现在需要添加一个 `Triangle` 类,只需扩展代码,而无需修改现有代码。
```csharp
public class Triangle : Shape
{
public double Base { get; set; }
public double Height { get; set; }
public override double CalculateArea()
{
return 0.5 * Base * Height;
}
}
// 使用
var triangle = new Triangle { Base = 10, Height = 5 };
var areaCalculator = new AreaCalculator();
double area = areaCalculator.CalculateArea(triangle); // 25
```
---
开闭原则的好处:
1. **可维护性**:无需修改现有代码,减少引入新错误的风险。
2. **可扩展性**:通过扩展实现新功能,系统更容易适应变化。
3. **代码复用**:抽象层可以被多个具体实现复用。
4. **降低耦合**:客户端代码依赖于抽象,而不是具体实现。
---
总结:
在C#中,开闭原则是设计高质量、可维护代码的重要原则。通过使用抽象(接口或抽象类)和设计模式,可以使代码对扩展开放,对修改关闭。遵循开闭原则的代码更容易适应需求变化,同时降低了维护成本。
里氏代换原则 (LSP)
**里氏代换原则(Liskov Substitution Principle, LSP)** 是面向对象设计中的五大原则之一(SOLID原则中的“L”)。它的核心思想是:
> **子类必须能够替换其父类,并且替换后程序的行为不会发生变化。**
换句话说,如果一个程序使用了一个基类(父类),那么它应该能够使用该基类的任何子类,而不会产生错误或意外行为。里氏代换原则强调了继承关系的正确使用,确保子类不会破坏父类的行为。
---
里氏代换原则的核心思想:
1. **子类必须完全实现父类的行为**:子类不能改变父类的行为,只能扩展或完善。
2. **子类不能违反父类的约束**:例如,父类的方法不能被子类重写为抛出异常或返回不符合预期的结果。
3. **子类可以扩展父类的功能**:但不能修改父类的核心逻辑。
---
在C#中的应用:
在C#中,里氏代换原则通常通过以下方式实现:
1. **正确使用继承**:确保子类能够完全替代父类。
2. **避免违反父类的契约**:子类不能修改父类方法的输入、输出或行为。
3. **使用抽象类或接口**:通过定义清晰的契约,确保子类的行为符合预期。
---
示例:违反里氏代换原则的代码
以下代码违反了里氏代换原则,因为子类 `Square` 修改了父类 `Rectangle` 的行为。
```csharp
public class Rectangle
{
public virtual int Width { get; set; }
public virtual int Height { get; set; }
public int CalculateArea()
{
return Width * Height;
}
}
public class Square : Rectangle
{
public override int Width
{
set { base.Width = base.Height = value; }
}
public override int Height
{
set { base.Width = base.Height = value; }
}
}
// 使用
Rectangle rectangle = new Square();
rectangle.Width = 5;
rectangle.Height = 10;
Console.WriteLine(rectangle.CalculateArea()); // 输出 100,而不是预期的 50
```
**问题**:
- `Square` 类修改了 `Rectangle` 的行为,导致 `CalculateArea` 的结果不符合预期。
- 违反了里氏代换原则,因为 `Square` 不能完全替代 `Rectangle`。
---
示例:遵循里氏代换原则的代码
通过重新设计类结构,确保子类不会修改父类的行为。
```csharp
public abstract class Shape
{
public abstract int CalculateArea();
}
public class Rectangle : Shape
{
public int Width { get; set; }
public int Height { get; set; }
public override int CalculateArea()
{
return Width * Height;
}
}
public class Square : Shape
{
public int SideLength { get; set; }
public override int CalculateArea()
{
return SideLength * SideLength;
}
}
// 使用
Shape rectangle = new Rectangle { Width = 5, Height = 10 };
Shape square = new Square { SideLength = 5 };
Console.WriteLine(rectangle.CalculateArea()); // 输出 50
Console.WriteLine(square.CalculateArea()); // 输出 25
```
**改进点**:
1. **抽象类**:通过 `Shape` 抽象类定义了一个通用的 `CalculateArea` 方法。
2. **子类行为一致**:`Rectangle` 和 `Square` 都实现了 `CalculateArea`,但不会相互影响。
3. **符合里氏代换原则**:`Rectangle` 和 `Square` 都可以替换 `Shape`,且行为符合预期。
---
里氏代换原则的好处:
1. **提高代码的可维护性**:子类不会破坏父类的行为,减少意外错误。
2. **增强代码的可扩展性**:通过继承和多态,可以轻松扩展系统功能。
3. **降低耦合**:客户端代码依赖于抽象,而不是具体实现。
4. **提高代码的可靠性**:子类完全遵循父类的契约,行为可预测。
---
总结:
在C#中,里氏代换原则是设计高质量、可维护代码的重要原则。通过正确使用继承和多态,确保子类能够完全替代父类,而不会破坏程序的行为。遵循里氏代换原则的代码更容易扩展和维护,同时降低了引入错误的风险。
这是针对一个非常简单的里面的一个恐怖意图, 它的正式定义是: “如果 S 是 T 的一个子类型, 那么类
型为 T 的对象可以被类型为 S 的对象替换(例如, 类型为 S 的对象可作为类型为 T 的替代品)儿不需
要修改目标程序的期望性质 (正确性、 任务执行性等)。” 这甚至是个恐怖的定义。
最好的解释是, 如果你又一个基类和一个子类, 那个基类和字类可以互换而不会产生不正确的结果。 这可
能还有有些疑惑, 让我们来看一下这个经典的正方形与矩形的例子。 从数学上说, 一个正方形是一个矩形,
但是你用 "is-a" 的关系用继承来实现, 你将很快遇到麻烦。
**不好的:**
```
class Rectangle {
protected int width;
protected int height;
public Rectangle() {
this.width = 0;
this.height = 0;
}
void setColor(String color) {
// ...
}
void render(int area) {
// ...
}
void setWidth(int width) {
this.width = width;
}
void setHeight(int height) {
this.height = height;
}
int getArea() {
return this.width * this.height;
}
}
class Square extends Rectangle {
void setWidth(int width) {
this.width = width;
this.height = width;
}
void setHeight(int height) {
this.width = height;
this.height = height;
}
}
void renderLargeRectangles(List<Rectangle> rectangles) {
for(Rectangle rectangle:rectangles) {
rectangle.setWidth(4);
rectangle.setHeight(5);
int area = rectangle.getArea(); // BAD: Will return 25 for Square. Should be 20.
rectangle.render(area);
}
}
List<Rectangle> rectangles=new ArrayList<>();
rectangles.add(new Rectangle());
rectangles.add(new Rectangle());
rectangles.add(new Square());
renderLargeRectangles(rectangles);
```
**好的:**
```
class Shape {
void setColor(String color) {
// ...
}
int getArea() {
}
void render(int area) {
// ...
}
}
class Rectangle extends Shape {
private int width;
private int height;
public Rectangle(int width, int height) {
super();
this.width = width;
this.height = height;
}
int getArea() {
return this.width * this.height;
}
}
class Square extends Shape {
private int length;
public Square(int length) {
super();
this.length = length;
}
int getArea() {
return this.length * this.length;
}
}
void renderLargeShapes(List<Shape> shapes) {
for(Shape shape:shapes) {
int area = shape.getArea();
shape.render(area);
}
}
List<Shape> shapes=new ArrayList<>();
shapes.add(new Rectangle(4,5));
shapes.add(new Rectangle(4,5));
shapes.add(new Square(5));
renderLargeShapes(shapes);
```
接口隔离原则 (ISP)
接口隔离原则说的是 “客户端不应该强制依赖他们不需要的接口。“
**接口隔离原则(Interface Segregation Principle, ISP)** 是面向对象设计中的五大原则之一(SOLID原则中的“I”)。它的核心思想是:
> **客户端不应该依赖于它不需要的接口。**
换句话说,一个类不应该被迫实现它不需要的方法。应该将大的、臃肿的接口拆分为更小、更具体的接口,以便客户端只需关心它们实际需要的功能。
---
接口隔离原则的核心思想:
1. **小而专的接口**:接口应该尽量小,只包含客户端需要的方法。
2. **避免臃肿的接口**:不要让一个接口包含太多方法,否则实现类可能被迫实现一些无用的方法。
3. **按需实现**:客户端应该只依赖于它们实际需要的接口。
---
在C#中的应用:
在C#中,接口隔离原则通常通过以下方式实现:
1. **定义小而专的接口**:将大的接口拆分为多个小的接口。
2. **按需实现接口**:类只需实现它们需要的接口。
3. **避免“胖接口”**:不要让一个接口承担太多职责。
---
示例:违反接口隔离原则的代码
以下代码违反了接口隔离原则,因为 `IMachine` 接口包含了太多方法,导致实现类被迫实现不需要的方法。
```csharp
public interface IMachine
{
void Print();
void Scan();
void Fax();
}
public class MultiFunctionPrinter : IMachine
{
public void Print()
{
Console.WriteLine("Printing...");
}
public void Scan()
{
Console.WriteLine("Scanning...");
}
public void Fax()
{
Console.WriteLine("Faxing...");
}
}
public class SimplePrinter : IMachine
{
public void Print()
{
Console.WriteLine("Printing...");
}
public void Scan()
{
throw new NotImplementedException(); // 不需要的方法
}
public void Fax()
{
throw new NotImplementedException(); // 不需要的方法
}
}
```
**问题**:
- `SimplePrinter` 类被迫实现了 `Scan` 和 `Fax` 方法,尽管它不需要这些功能。
- 违反了接口隔离原则,因为客户端(`SimplePrinter`)依赖于它不需要的方法。
---
示例:遵循接口隔离原则的代码
通过将 `IMachine` 接口拆分为多个小的接口,每个接口只包含特定的功能。
```csharp
public interface IPrinter
{
void Print();
}
public interface IScanner
{
void Scan();
}
public interface IFax
{
void Fax();
}
public class MultiFunctionPrinter : IPrinter, IScanner, IFax
{
public void Print()
{
Console.WriteLine("Printing...");
}
public void Scan()
{
Console.WriteLine("Scanning...");
}
public void Fax()
{
Console.WriteLine("Faxing...");
}
}
public class SimplePrinter : IPrinter
{
public void Print()
{
Console.WriteLine("Printing...");
}
}
```
**改进点**:
1. **小而专的接口**:将 `IMachine` 拆分为 `IPrinter`、`IScanner` 和 `IFax`。
2. **按需实现**:`SimplePrinter` 只需实现 `IPrinter`,而无需实现不需要的方法。
3. **符合接口隔离原则**:客户端只依赖于它们实际需要的接口。
---
示例:组合接口
如果需要支持多种功能的设备,可以通过组合接口来实现。
```csharp
public interface IMultiFunctionDevice : IPrinter, IScanner, IFax
{
}
public class OfficeMachine : IMultiFunctionDevice
{
private readonly IPrinter _printer;
private readonly IScanner _scanner;
private readonly IFax _fax;
public OfficeMachine(IPrinter printer, IScanner scanner, IFax fax)
{
_printer = printer;
_scanner = scanner;
_fax = fax;
}
public void Print()
{
_printer.Print();
}
public void Scan()
{
_scanner.Scan();
}
public void Fax()
{
_fax.Fax();
}
}
```
**优点**:
- 通过组合接口,可以灵活地支持多种功能。
- 符合接口隔离原则,每个接口只包含特定的功能。
---
接口隔离原则的好处:
1. **提高代码的灵活性**:客户端只需依赖于它们需要的接口。
2. **降低耦合**:接口更小、更专一,减少了类之间的依赖。
3. **增强可维护性**:修改一个接口不会影响其他接口的实现。
4. **避免冗余代码**:实现类无需实现不需要的方法。
---
总结:
在C#中,接口隔离原则是设计高质量、可维护代码的重要原则。通过定义小而专的接口,确保客户端只依赖于它们实际需要的功能。遵循接口隔离原则的代码更灵活、更易于扩展和维护,同时降低了耦合性。
**不好的:**
```
interface I {
public void method1();
public void method2();
public void method3();
public void method4();
public void method5();
}
class A{
public void depend1(I i){
i.method1();
}
public void depend2(I i){
i.method2();
}
public void depend3(I i){
i.method3();
}
}
class B{
public void depend1(I i){
i.method1();
}
public void depend2(I i){
i.method4();
}
public void depend3(I i){
i.method5();
}
}
class C implements I{
public void method1() {
System.out.println("类B实现接口I的方法1");
}
public void method2() {
System.out.println("类B实现接口I的方法2");
}
public void method3() {
System.out.println("类B实现接口I的方法3");
}
//对于类B来说,method4和method5不是必需的,但是由于接口A中有这两个方法,
//所以在实现过程中即使这两个方法的方法体为空,也要将这两个没有作用的方法进行实现。
public void method4() {}
public void method5() {}
}
class D implements I{
public void method1() {
System.out.println("类D实现接口I的方法1");
}
//对于类D来说,method2和method3不是必需的,但是由于接口A中有这两个方法,
//所以在实现过程中即使这两个方法的方法体为空,也要将这两个没有作用的方法进行实现。
public void method2() {}
public void method3() {}
public void method4() {
System.out.println("类D实现接口I的方法4");
}
public void method5() {
System.out.println("类D实现接口I的方法5");
}
}
```
**好的:**
```
interface I1 {
public void method1();
}
interface I2 {
public void method2();
public void method3();
}
interface I3 {
public void method4();
public void method5();
}
class A{
public void depend1(I1 i){
i.method1();
}
public void depend2(I2 i){
i.method2();
}
public void depend3(I2 i){
i.method3();
}
}
class B{
public void depend1(I1 i){
i.method1();
}
public void depend2(I3 i){
i.method4();
}
public void depend3(I3 i){
i.method5();
}
}
class C implements I1, I2{
public void method1() {
System.out.println("类B实现接口I1的方法1");
}
public void method2() {
System.out.println("类B实现接口I2的方法2");
}
public void method3() {
System.out.println("类B实现接口I2的方法3");
}
}
class D implements I1, I3{
public void method1() {
System.out.println("类D实现接口I1的方法1");
}
public void method4() {
System.out.println("类D实现接口I3的方法4");
}
public void method5() {
System.out.println("类D实现接口I3的方法5");
}
```
依赖反转原则 (DIP)
这个原则阐述了两个重要的事情:
1. 高级模块不应该依赖于低级模块, 两者都应该依赖与抽象;
2. 抽象不应当依赖于具体实现, 具体实现应当依赖于抽象。
这个一开始会很难理解, 但是如果你使用过 Angular.js , 你应该已经看到过通过依赖注入来实现的这
个原则, 虽然他们不是相同的概念, 依赖反转原则让高级模块远离低级模块的细节和创建, 可以通过 DI
来实现。 这样做的巨大益处是降低模块间的耦合。 耦合是一个非常糟糕的开发模式, 因为会导致代码难于
重构。
如上所述,C#Script 没有接口, 所以被依赖的抽象是隐式契约。 也就是说, 一个对象/类的方法和
属性直接暴露给另外一个对象/类。 在下面的例子中, 任何一个 Request 模块的隐式契约 `InventoryTracker`
将有一个 `requestItems` 方法。
**不好的:**
```
class InventoryRequester {
private String REQ_METHODS;
public InventoryRequester() {
this.REQ_METHODS = "HTTP";
}
void requestItem(String item) {
// ...
}
}
class InventoryTracker {
private List<String> items;
private InventoryRequester requester;
public InventoryTracker(List<String> items) {
this.items = items;
// 不好的: 我们已经创建了一个对请求的具体实现的依赖, 我们只有一个 requestItems 方法依
// 赖一个请求方法 'request'
this.requester = new InventoryRequester();
}
void requestItems() {
this.items.stream().forEach(item->this.requester.requestItem(item));
}
}
List<String> items=new ArrayList<>();
items.add("apples");
items.add("bananas");
InventoryTracker inventoryTracker = new InventoryTracker(items);
inventoryTracker.requestItems();
```
**好的:**
```
interface Requester{
void requestItem(String item);
}
class InventoryTracker {
List<String> items;
Requester requester;
public InventoryTracker(List<String> items, Requester requester) {
this.items = items;
this.requester = requester;
}
void requestItems() {
this.items.stream().forEach(item->requester.requestItem(item));
}
}
class InventoryRequesterV1 implements Requester{
String REQ_METHODS;
public InventoryRequesterV1() {
this.REQ_METHODS="HTTP";
}
@Override
public void requestItem(String item) {
// ...
}
}
class InventoryRequesterV2 implements Requester{
String REQ_METHODS;
public InventoryRequesterV2() {
this.REQ_METHODS="WS";
}
@Override
public void requestItem(String item) {
// ...
}
}
// 通过外部创建依赖项并将它们注入, 我们可以轻松的用一个崭新的使用 WebSockets 的请求模块进行替换。
List<String> items=new ArrayList<>();
items.add("apples");
items.add("bananas");
InventoryTracker inventoryTracker = new InventoryTracker(items, new InventoryRequesterV2());
inventoryTracker.requestItems();
```
**测试**
测试比发布更加重要。 如果你没有测试或者测试不够充分, 每次发布时你就不能确认没有破坏任何事情。
测试的量由你的团队决定, 但是拥有 100% 的覆盖率(包括所有的语句和分支)是你为什么能达到高度自信
和内心的平静。 这意味着需要一个额外的伟大的测试框架, 也需要一个好的[覆盖率工具](http://gotwarlost.github.io/istanbul/)。
没有理由不写测试。 这里有[大量的优秀的 JS 测试框架](http://jstherightway.org/#testing-tools),
选一个适合你的团队的即可。 当为团队选择了测试框架之后, 接下来的目标是为生产的每一个新的功能/模
块编写测试。 如果你倾向于测试驱动开发(TDD), 那就太棒了, 但是要点是确认你在上线任何功能或者重
构一个现有功能之前, 达到了需要的目标覆盖率。
一个测试一个概念
**不好的:**
```
void testMakeMomentJSGreatAgain(){
Date date;
date = new MakeMomentJSGreatAgain("1/1/2015");
date.addDays(30);
Assert.equal(date.getString(),"1/31/2015").
date = new MakeMomentJSGreatAgain("2/1/2016");
date.addDays(28);
Assert.equal(date.getString(),"02/29/2016");
date = new MakeMomentJSGreatAgain("2/1/2015");
date.addDays(28);
Assert.equal(date.getString(),"03/01/2015");
}
```
**好的:**
```
void testThirtyDayMonths(){
Date date = new MakeMomentJSGreatAgain("1/1/2015");
date.addDays(30);
Assert.equal(date.getString(),"1/31/2015");
}
void testLeapYear(){
Date date = new MakeMomentJSGreatAgain("2/1/2016");
date.addDays(28);
Assert.equal(date.getString(),"02/29/2016");
}
void testNonLeapYear(){
Date date = new MakeMomentJSGreatAgain("2/1/2015");
date.addDays(28);
Assert.equal(date.getString(),"03/01/2015");
}
```
**错误处理**
抛出错误是一件好事情! 他们意味着当你的程序有错时运行时可以成功确认, 并且通过停止执行当前堆栈
上的函数来让你知道, 结束当前进程(在 Node 中), 在控制台中用一个堆栈跟踪提示你。
不要忽略捕捉到的错误
对捕捉到的错误不做任何处理不能给你修复错误或者响应错误的能力。 向控制台记录错误 (`console.log`)
也不怎么好, 因为往往会丢失在海量的控制台输出中。 如果你把任意一段代码用 `try/catch` 包装那就
意味着你想到这里可能会错, 因此你应该有个修复计划, 或者当错误发生时有一个代码路径。
**不好的:**
```
try {
functionThatMightThrow();
} catch (Exception error) {
console.log(error);
}
```
**好的:**
```
try {
functionThatMightThrow();
} catch (Exception error) {
// One option (more noisy than console.log):
console.error(error);
// Another option:
notifyUserOfError(error);
// Another option:
reportErrorToService(error);
// OR do all three!
}
```
**格式化**
格式化是主观的。 就像其它规则一样, 没有必须让你遵守的硬性规则。 重点是不要因为格式去争论, 这
里有[大量的工具](http://standardjs.com/rules.html)来自动格式化, 使用其中的一个即可! 因
为做为工程师去争论格式化就是在浪费时间和金钱。
针对自动格式化工具不能涵盖的问题(缩进、 制表符还是空格、 双引号还是单引号等), 这里有一些指南。
使用一致的大小写
JavaScript 是无类型的, 所以大小写告诉你关于你的变量、 函数等的很多事情。 这些规则是主观的,
所以你的团队可以选择他们想要的。 重点是, 不管你们选择了什么, 要保持一致。
**不好的:**
```
int DAYS_IN_WEEK = 7;
int daysInMonth = 30;
String[] songs = {"Back In Black", "Stairway to Heaven", "Hey Jude"};
String[] Artists = {"ACDC", "Led Zeppelin", "The Beatles"};
void eraseDatabase() {}
void restore_database() {}
class animal {}
class Alpaca {}
```
**好的:**
```
int DAYS_IN_WEEK = 7;
int DAYS_IN_MONTH = 30;
String[] songs = {"Back In Black", "Stairway to Heaven", "Hey Jude"};
String[] artists = {"ACDC", "Led Zeppelin", "The Beatles"};
void eraseDatabase() {}
void restoreDatabase() {}
class Animal {}
class Alpaca {}
```
函数的调用方与被调用方应该靠近
如果一个函数调用另一个, 则在代码中这两个函数的竖直位置应该靠近。 理想情况下,保持被调用函数在被
调用函数的正上方。 我们倾向于从上到下阅读代码, 就像读一章报纸。 由于这个原因, 保持你的代码可
以按照这种方式阅读。
**不好的:**
```
class PerformanceReview {
String employee;
public PerformanceReview(String employee) {
this.employee = employee;
}
String lookupPeers() {
return db.lookup(this.employee, "peers");
}
String lookupManager() {
return db.lookup(this.employee, "manager");
}
void getPeerReviews() {
String peers = this.lookupPeers();
// ...
}
public void perfReview() {
this.getPeerReviews();
this.getManagerReview();
this.getSelfReview();
}
void getManagerReview() {
String manager = this.lookupManager();
}
void getSelfReview() {
// ...
}
}
PerformanceReview review = new PerformanceReview("user");
review.perfReview();
```
**好的:**
```
class PerformanceReview {
String employee;
public PerformanceReview(String employee) {
this.employee = employee;
}
void perfReview() {
this.getPeerReviews();
this.getManagerReview();
this.getSelfReview();
}
void getPeerReviews() {
String peers = this.lookupPeers();
// ...
}
String lookupPeers() {
return db.lookup(this.employee, "peers");
}
void getManagerReview() {
String manager = this.lookupManager();
}
String lookupManager() {
return db.lookup(this.employee, "manager");
}
public void getSelfReview() {
// ...
}
}
PerformanceReview review = new PerformanceReview("user");
review.perfReview();
```
**注释**
仅仅对包含复杂业务逻辑的东西进行注释
注释是代码的辩解, 不是要求。 多数情况下, 好的代码就是文档。
**不好的:**
```
void hashIt(String data) {
// The hash
long hash = 0;
// Length of string
int length = data.length();
// Loop through every character in data
for (int i = 0; i < length; i++) {
// Get character code.
char mChar = data.charAt(i);
// Make the hash
hash = ((hash << 5) - hash) + mChar;
// Convert to 32-bit integer
hash &= hash;
}
}
```
**好的:**
```
void hashIt(String data) {
long hash = 0;
int length = data.length();
for (int i = 0; i < length; i++) {
char mchar = data.charAt(i);
hash = ((hash << 5) - hash) + mchar;
// Convert to 32-bit integer
hash &= hash;
}
}
```
不要在代码库中保存注释掉的代码
因为有版本控制, 把旧的代码留在历史记录即可。
**不好的:**
```
doStuff();
// doOtherStuff();
// doSomeMoreStuff();
// doSoMuchStuff();
```
**好的:**
```
doStuff();
```
不要有日志式的注释
记住, 使用版本控制! 不需要僵尸代码, 注释掉的代码, 尤其是日志式的注释。 使用 `git log` 来
获取历史记录。
**不好的:**
```
/**
* 2016-12-20: Removed monads, didn't understand them (RM)
* 2016-10-01: Improved using special monads (JP)
* 2016-02-03: Removed type-checking (LI)
* 2015-03-14: Added combine with type-checking (JR)
*/
void combine(String a, String b) {
return a + b;
}
```
**好的:**
```
void combine(String a, String b) {
return a + b;
}
```
避免占位符
它们仅仅添加了干扰。 让函数和变量名称与合适的缩进和格式化为你的代码提供视觉结构。
**不好的:**
```
// Scope Model Instantiation
String[] model = {"foo","bar"};
// Action setup
void action(){
//...
}
```
**好的:**
```
String[] model = {"foo","bar"};
void action(){
//...
}
```
--
**工具**
[Lint](https://developer.android.google.cn/studio/write/lint)
Android Studio 提供了一个名为 Lint 的代码扫描工具,可帮助您发现并更正代码结构质量的问题,而无需您实际执行应用,也不必编写测试用例。系统会报告该工具检测到的每个问题并提供问题的描述消息和严重级别,以便您可以快速确定需要优先进行的关键改进。此外,您还可以降低问题的严重级别以忽略与项目无关的问题,或者提高严重级别以突出特定问题。
Lint 工具可以检查您的 Android 项目源文件是否有潜在的错误,以及在正确性、安全性、性能、易用性、无障碍性和国际化方面是否需要优化改进。

Lint不仅支持Java语言,同是支持Kotlin、C/C++等的规范性检查,Android官方推荐的代码扫描工具。
[CheckStyle](https://checkstyle.org/)
CheckStyle作为检验代码规范的插件,除了可以使用配置默认给定的开发规范,如Sun的,Google的开发规范啊,也可以导入像阿里的开发规范的插件。事实上,每一个公司都存在不同的开发规范要求,所以大部分公司会给定自己的check规范,一般导入给定的checkstyle.xml文件即可实现。CheckStyle来辅助判断代码格式是否满足规范,保证团队成员开发的code风格一致。
CheckStyle检验的主要内容
- Javadoc注释
- 命名约定
- 标题
- Import语句
- 体积大小
- 空白
- 修饰符
- 块
- 代码问题
- 类设计
- 混合检查(包括一些有用的比如非必须的System.out和printstackTrace)
从上面可以看出,CheckStyle提供了大部分功能都是对于代码规范的检查。但CheckStyle目前只支持检查Java语言。

[SonarLint](https://www.sonarlint.org/)
SonarLint是一个IDE扩展,可帮助您在编写代码时检测和修复质量问题,在提交代码之前进行修复。
- 错误检测
受益于已有的数千条规则 ; 可以检测常见错误,棘手错误和已知漏洞
- 即时反馈
就像拼写检查器一样,在编码时会检测到并报告问题
- 丰富的文档
精确地指出了问题所在,并为您提供了解决方法的建议

[AlibabaC# Coding Guidelines](https://github.com/alibaba/p3c)
阿里巴巴于10月14号在杭州云栖大会上,正式发布《阿里巴巴Java开发规约》的扫描插件。该插件在扫描代码后,将不符合规约的代码按Blocker/Critical/Major三个等级显示在下方,甚至在IDEA上,该插件还基于Inspection机制提供了实时检测功能,编写代码的同时也能快速发现问题所在。对于历史代码,部分规则实现了批量一键修复的功能。
- Blocker
即系统无法执行、崩溃或严重资源不足、应用模块无法启动或异常退出、无法测试、造成系统不稳定。
严重花屏、内存泄漏、用户数据丢失或破坏、系统崩溃/死机/冻结、模块无法启动或异常退出、严重的数值计算错误、功能设计与需求严重不符、其它导致无法测试的错误, 如服务器500错误
- Critical
即影响系统功能或操作,主要功能存在严重缺陷,但不会影响到系统稳定性。
功能未实现、功能错误、系统刷新错误、数据通讯错误、轻微的数值计算错误、影响功能及界面的错误字或拼写错误、安全性问题
- Major
即界面、性能缺陷、兼容性。操作界面错误(包括数据窗口内列名定义、含义是否一致)、边界条件下错误、提示信息错误(包括未给出信息、信息提示错误等)、长时间操作无进度提示、系统未优化(性能问题)、光标跳转设置不好,鼠标(光标)定位错误、兼容性问题

**不同的代码检查工具原理相同,但侧重点不一样,在实际的项目开发中,可以根据自己的团队及项目情况进行选择及组合,定义自己的团队规范。**
--
# 谜题
程序员在背负期限的压力下,只好追求快速的开发速度,于是为代码制造了混乱,却认为自己因此没法做到更快。
制造混乱只会立刻拖慢你,叫你错过期限。赶上期限的唯一方法、做得快的唯一方法就是始终尽可能保持代码整洁。
# 代码里的命名规则:错误的和正确的对比
编程初学者总是把大量的时间用在学习编程语言,语法,技巧和编程工具的使用上。他们认为,如果掌握了这些技术技巧,他们就能成为不错的程序员。然而,计算机编程的目的并不是关于精通这些技术、工具的,它是关于针对特定领域里的特定问题创造出相应的解决方案,程序员通过相互合作来实现这些。所以,很重要的一点,你需要能精确的用代码表达出你的思想,让其他人通过代码能明白你的意图。
让我们先看看编程大师Robert C. Martin的杰作《[Clean Code](http://t.cn/zHPF56e)》里的一句话:
> *“注释的目的是为了弥补代码自身在表达上的不足。”*
这句话可以简单的理解为**如果你的代码需要注释,最有可能是你的代码写的很烂。**同样,如果在没有注释的情况下你无法用代码完整的表达你对一个问题或一个算法的思路,那这就是一个失败的信号。最终,这意味着你需要用注释来阐明一部分的思想,而这部分在代码里是看不出来的。**好的代码能够让任何人在不需要任何注释的情况下看懂。**好的编码风格能将所有有助于理解这个问题的所有信息都蕴含在代码里。
在编程理论中,有一个概念叫做“自我描述的源代码”。对于一段代码,一种常见的自我描述机制是遵循某种非严格定义的变量、方法、对象命名规则。这样做的主要作用就是使源代码更易读易懂。所以,也就更容易维护和扩展。
**这篇文章里,我将举出一些例子,说明什么是“不好的代码”,什么是“清楚的代码”**
命名要能揭示意图
如何命名,在编程中这永远都是个老大难问题。有些程序员喜欢简化、缩短或加密名称,使得只有他们自己能懂。下面让我们看一些例子:
**不好的代码:**
```c#
int d;
// 天数
int ds;
int dsm;
int faid;
```
“d”可以表示任何东西。作者使用注释来表明他的意图,却没有选择用代码来表示。而“faid”很容易导致误解为ID。
**清楚的代码:**
```C#
int elapsedTimeInDays;
int daysSinceCreation;
int daysSinceModification;
int fileAgeInDays;
```
命名时避免含义引起误解的信息
错误的信息比没有信息更糟糕。有些程序员喜欢“隐藏”一些重要信息,有时候他们也会写出一些让人误解的代码。
**不好的代码:**
```
Customer[] customerList;
Table theTable;
```
变量“customerList”其实不是个list。它是一个普通的array(或客户集合)。除此之外,“theTable”是一个Table类型的对象(你可以用IDE容易的发现它的类型),“the”这个词是个不必要的干扰。
**清楚的代码:**
```
Customer[] customers;
Table customers;
```
命名要有合适的长度
在高级编程语言中,变量名的长度通常不太限制。变量名几乎可以任何长度。虽然如此,这也可能使代码变得闹心。
**不好的代码:**
```
var theCustomersListWithAllCustomersIncludedWithoutFilter;
var list;
```
好的名称应该只含有必要的词汇来表达一个概念。任何不必要的字词都会使名称变长、难于理解。名称越短越好,前提是能在上下文中表达完整的意思(下订单这个场景中,“customersInOrder” 要比 “list” 好)。
**清楚的代码:**
```
var allCustomers;
var customersInOrder;
```
命名时编码规范保持一致,让规范帮助理解代码
所有的编程技术(语言)都有自己的“风格”,叫做编码规范。程序员应该在写代码时遵循这些习惯,因为其他的程序员也知道这些,并按这种风格编写。下面我们看一个没有明显规范的不好的代码例子。下面的这段代码没有遵循很好的已知的“编码规范”(比如PascalCase, camelCase, Hungarian规范)。更糟糕的是,这有一个毫无意义的bool变量“change”。这是个动词(用来描述动作),但这里的bool值是来描述一个状态,所以,这里应该用一个形容词更合适。
**不好的代码:**
```
const int maxcount = 1
bool change = true
public interface Repository
private string NAME
public class personaddress
void getallorders()
```
一段代码,只看它的一部分,你就应该直接明白它是什么类型,只需要看它的命名方法。
例如:你看到了“_name”,你就能知道它是个私有变量。你应该在任何地方都利用这种表示方法,没有例外情况。
**清楚的代码:**
```
const int MAXCOUNT = 1
bool isChanged = true
public interface IRepository
private string _name
public class PersonAddress
void GetAllOrders()
```
命名时相同的概念用相同的词表达
定义概念很难。在软件开发过程中,很多时间都花在分析业务场景、思考正确的定义里面所有的元素。这些概念永远都是让程序员头痛的事。
**不好的代码:**
```
//1.
void LoadSingleData()
void FetchDataFiltered()
Void GetAllData()
//2.
void SetDataToView();
void SetObjectValue(int value)
```
首先:
代码的作者试图表达“get the data”的概念,他使用了多个词“load”,“fetch”,“get”。一个概念只用一个词表达就行了(在同一个场景中)。
第二:
“set”这个词用在了2个概念里:第一是“data loading to view”,第二个是“setting a value of object”。这是两个不同的概念,你应该使用不同的词。
**清楚的代码:**
```
//1.
void GetSingleData()
void GetDataFiltered()
Void GetAllData()
//2.
void LoadDataToView();
void SetObjectValue(int value)
```
命名时使用跟业务领域相关的词
程序员写的所有代码都是跟业务领域场景逻辑相连的。为了让所有关系到这个问题的人都能更好的理解,程序中应该使用在领域环境中有意义的名称。
**不好的代码:**
```
public class EntitiesRelation
{
Entity o1;
Entity o2;
}
```
当在编写针对某个领域的代码时,你应该始终考虑使用领域有联系的名称。在将来,当另外一个人(不仅是程序员,也许是测试人员)接触你的代码时,他能轻松的理解这个业务领域里你的代码是什么意思(不需要业务逻辑知识)。你首先考虑的应该是业务问题,之后才是如何解决。
**清楚的代码:**
```
public class ProductWithCategory
{
Entity product;
Entity category;
}
```
命名时使用在特定环境里有意义的词
代码里名称都有自己的上下文。上下文对于理解一个名称非常重要,因为它能提供额外的信息。让我们来看看一个典型的“地址”上下文:
**不好的代码:**
```
string addressCity;
string addressHomeNumber;
string addressPostCode;
```
在大多数情况中,“Post Code”通常是地址的一部分,很显然,邮政编码不能单独使用(除非你是在开发一个专门处理邮编的应用)。所以,没有必要在“PostCode”的前面加上“address”。更重要的,所以的这些信息都有一个上下文容环境,一个命名空间,一个类。
在面向对象编程中,这里应该用一个“Address”类来表达这个地址信息。
**清楚的代码:**
```
class Address
{
string city;
string homeNumber;
string postCode;
}
```
命名方法总结
概述起来,做为一个程序员,你应该:
- 命名是来表达概念的
- 注意名称长度,名称里只该含有必要的词语
- 编码规范有助于理解代码,你应该使用它
- 名称不要混用
- 名称在业务领域里要有意义,在上下文里有意义
代码质量提升秘籍:从命名到代码架构,让你的代码更易读、易维护
程序员的工作并不仅仅是让代码能够运行,更重要的是确保代码的质量。仅仅满足编译和运行的基本要求,远远不足以成为一名优秀的开发者。合格的程序员需要注重代码的整洁度,通过合理的命名、规范的架构和优雅的设计,使代码更易读、易维护。
好的命名是代码整洁的关键之一。一个恰当的命名能够清晰地传达代码的特征、含义或用途,帮助阅读者迅速把握程序的逻辑。在本篇分享中,我们将探讨一些提升代码命名的有效方法,包括保持清晰准确、避免误导、做出有意义区分、结合上下文简化名称,以及使用可搜索、易读的名称等。
此外,我们还需要遵循包命名规范、类名与方法名规范等原则,以确保代码的整体结构和逻辑清晰。一个混乱的代码库不仅会影响开发效率,还会增加维护成本,甚至可能阻碍项目的进展。
在软件开发过程中,我们时常会遇到需求变更、排期紧张等挑战。然而,这些困难并非借口,优秀的开发者应该时刻保持对代码质量的追求。他们了解代码变坏的风险,并坚持通过持续的努力来保持代码的整洁与优雅。只有这样,我们才能应对变化的需求,提高开发效率,确保项目的成功实施。
代码质量的评判是一个综合性的过程,不能仅仅依据单一维度来评判。例如,如果一段代码的可读性很好,但其在空间和时间复杂度上表现不佳,那么它也不能被视为优秀的代码。好的代码应该具备易拓展和维护的特点,同时保持简洁,专注于做好一件事,避免重复代码的出现。此外,好的代码还应该具备可复用性强和能快速编写单元测试的特点,确保其可读性强且无副作用。
易拓展和维护
在不影响原有代码设计的基础上,能够简便快速地实施功能拓展,是代码质量的重要体现。这要求在设计时预留拓展点,使得新代码能够顺利地融入其中,而无需对大量原始代码进行改动。遵循开闭原则,即对修改关闭、对拓展开放,确保代码的稳定性。
对于长期维护的软件项目而言,我们花费在旧代码上的时间往往超过新项目新代码的时间。因此,代码的可维护性变得至关重要。这意味着代码的层次要清晰、模块划分要精当,以满足高内聚、低耦合的要求。合理的接口设计和面向接口编程,是确保代码可维护性的关键。
同样一段代码,对于资深工程师来说可能易如反掌,而对于新人来说则可能难以理解。因此,易拓展性具有一定的主观性,需要我们不断提升基础技能才能更好地评判。
专注于做好一件事
每个函数、类或模块都应专注于单一功能,这是单一职责原则的要求。避免设计大而全的类或函数,而是应该将它们拆分成更细粒度、功能更单一的类。这样可以使设计意图更加明确,控制语句更加简洁明了。同时,也有助于减少类之间的依赖和耦合度。
然而,需要注意的是,拆分也不能过于细碎,以免破坏内聚性。高手总是能够用最简单的方法来解决复杂问题,这需要我们在设计时充分运用抽象和复用的思想。
是的,单一职责原则(Single Responsibility Principle, SRP)是面向对象设计中的五大原则之一(SOLID原则中的“S”)。它强调每个函数、类或模块应该只有一个职责或功能,即只做一件事,并且做好这件事。
单一职责原则的核心思想:
- **职责分离**:一个类或方法应该只有一个引起它变化的原因。如果一个类承担了多个职责,那么它的职责之间就会耦合在一起,导致代码难以维护、扩展和测试。
- **高内聚低耦合**:通过将职责分离,可以提高代码的内聚性,降低模块之间的耦合性,从而使代码更易于理解和修改。
在C#中的应用:
在C#中,遵循单一职责原则可以通过以下方式实现:
1. **类的单一职责**
一个类应该只负责一个功能领域。例如,一个类负责处理用户信息,另一个类负责处理日志记录,而不是将这两个功能混合在一个类中。
```csharp
// 不推荐:一个类承担多个职责
public class UserManager
{
public void AddUser(User user)
{
// 添加用户逻辑
}
public void Log(string message)
{
// 日志记录逻辑
}
}
// 推荐:将职责分离
public class UserManager
{
public void AddUser(User user)
{
// 添加用户逻辑
}
}
public class Logger
{
public void Log(string message)
{
// 日志记录逻辑
}
}
```
2. **方法的单一职责**
一个方法应该只完成一个具体的任务。如果一个方法过于复杂,承担了多个任务,应该将其拆分为多个小方法。
```csharp
// 不推荐:一个方法承担多个任务
public void ProcessOrder(Order order)
{
ValidateOrder(order);
SaveOrder(order);
SendConfirmationEmail(order);
}
// 推荐:将方法拆分为单一职责
public void ProcessOrder(Order order)
{
ValidateOrder(order);
SaveOrder(order);
NotifyCustomer(order);
}
private void ValidateOrder(Order order)
{
// 验证订单逻辑
}
private void SaveOrder(Order order)
{
// 保存订单逻辑
}
private void NotifyCustomer(Order order)
{
// 发送邮件通知
}
```
3. **模块的单一职责**
在更高层次上,模块或组件也应该遵循单一职责原则。例如,一个模块负责数据访问,另一个模块负责业务逻辑,而不是将两者混合在一起。
```csharp
// 不推荐:模块承担多个职责
public class DataAccess
{
public void SaveData(string data)
{
// 保存数据逻辑
}
public void ProcessData(string data)
{
// 处理数据逻辑
}
}
// 推荐:将模块职责分离
public class DataAccess
{
public void SaveData(string data)
{
// 保存数据逻辑
}
}
public class BusinessLogic
{
public void ProcessData(string data)
{
// 处理数据逻辑
}
}
```
单一职责原则的好处:
1. **易于维护**:代码职责清晰,修改一个功能不会影响其他功能。
2. **易于测试**:每个类或方法只做一件事,测试用例更简单、更专注。
3. **易于扩展**:新增功能时,只需添加新的类或方法,而无需修改现有代码。
4. **降低耦合**:职责分离后,模块之间的依赖减少,系统更灵活。
总结:
在C#开发中,遵循单一职责原则可以帮助你编写出更清晰、更易于维护和扩展的代码。无论是类、方法还是模块,都应该专注于单一职责,避免承担过多的功能。
无重复代码
在软件开发过程中,我们应该努力避免编写重复的代码。通过运用封装、继承、抽象和多态等特性,我们可以将代码封装成模块,隐藏变化的细节并暴露稳定的接口。同时,还需要对业务与非业务的代码逻辑进行分析和抽象,形成通用的框架和工具类等。这样不仅可以提高开发效率,还能确保代码的准确性和可维护性。
能快速写成单元测试
单元测试是确保代码质量的重要手段之一。如果代码的可测试性差或者难以编写单元测试,那么就说明代码的设计可能存在问题。为了避免这种情况的发生,我们在设计时就应该充分考虑单元测试的需求和便利性。例如,避免设计大而全的类或函数,而是将其拆分成更细粒度、功能更单一的模块等。这样可以使每个模块都有明确的输入和输出,从而简化单元测试的过程。
那说明这段代码的设计存在问题,需要进行合理的拆分和优化。
可读性至关重要
软件设计大师Martin Fowler曾言:“任何程序员都能写出计算机能理解的代码,而优秀的程序员则能写出人类也易于理解的代码。”这强调了代码可读性的重要性。可读性不仅涉及编码规范、命名清晰、注释详尽,还包括函数职责的单一性和精简的长度。有数据显示,阅读代码的时间往往是编写代码时间的十余倍,这进一步凸显了可读性在软件开发中的核心地位。
高质量的命名规范
在开发过程中,我们频繁地为变量、方法、参数、类、包等命名。这些命名不仅影响代码的可读性,还直接关系到我们的开发效率和代码质量。因此,我们必须遵循清晰、准确、简洁的命名原则,确保每个名称都能准确反映其功能,让使用者一目了然。
防止模糊和难以理解的代码
在编写代码时,我们要时刻警惕避免使用模糊不清或难以理解的名称。一个好的变量名或方法名应该能够直接展示其作用和功能,让使用者无需过多依赖上下文就能理解其含义。同时,我们也要避免使用所谓的“魔术数字”或“魔数”,这些不明确的命名只会增加代码的复杂性,降低其可读性。
综上所述,我认为可读性是评判代码质量最重要的标准之一。通过遵循良好的命名规范和确保代码的清晰简洁,我们可以写出既易于理解又易于维护的高质量代码。
在代码命名中,我们经常遇到一些让人困惑的情况。比如,索引为何从1开始,而非0?为何要限定在5以内?还有,为何使用与1极为相似的i作为变量名,这无疑增加了误解的可能性。
正确的做法是,使用具有实际含义的命名,以便让阅读者能够一目了然地理解代码的目的。否则,对于维护者来说,理解这样的代码将会是一项极具挑战的任务。
此外,我们还应避免使用生僻字或冗长的命名。例如,UltimateAssociatedSubjectRunBatchServiceImpl这样的类名,不仅让人难以理解其含义,还会阻碍代码的搜索和定位。相反,我们应该尽量使用简洁而富有描述性的命名,如LinkSubjectServiceImpl,这样能够更清晰地表达出该类的业务逻辑。
同时,我们也应避免使用含义模糊或差异较小的命名,以免给他人带来混淆。例如,deleteIndex和deleteIndexEx这两个函数名,由于区别过于细微,往往让人难以区分它们的实际意义。因此,在命名时,我们应该尽量确保名称能够准确反映函数的功能和用途。
综上所述,良好的代码命名规范对于提高代码的可读性和可维护性至关重要。通过遵循清晰、简洁、富有描述性的命名原则,我们可以写出更易于理解、易于维护的高质量代码。
在代码命名中,我们有时会遇到一些令人困惑的情况。例如,`downLoadFiles`与`fileDownload`这两个函数名,尽管只相差一个单词,但其功能却大相径庭。前者负责将文件打包成zip格式,而后者则是将指定文件提供给浏览器进行下载。这样的命名差异对于理解代码的人来说至关重要。
此外,还有一些命名缺乏明确性,如`getActiveOrder()`, `getActiveOrderInfo()`, `getActiveOrderData()`和`getActiveOrders()`等,这些方法名没有清晰地传达出它们各自的功能和用途。对于调用者来说,很难准确判断应该调用哪个方法,从而可能导致误解或不必要的麻烦。
同时,我们也应注意避免使用无意义的命名,如`Order`, `OrderInfo`, `OrderData`等,这些名称虽然相似,但在实际使用中却可能引起混淆。另外,`Variable`和`Table`这类词汇通常不应出现在变量名和表名中,因为它们过于泛泛而谈,缺乏具体性。
综上所述,良好的代码命名规范对于确保代码的可读性和可维护性至关重要。通过遵循清晰、简洁且富有描述性的命名原则,我们可以写出更易于理解、易于维护的高质量代码。
比如,在`Order`类中,我们不必为每个成员变量都添加`order`前缀,直接命名为`createTime`和`num`即可。因为通过`Order`这个上下文,我们可以轻松获取到这些变量的信息。
同样,在命名时,我们要确保名称易于阅读和理解,避免使用生僻字或难以发音的单词。这样,在讨论代码时,就不会出现诸如「那个「treeNewBeeAxibaKula」类是干什么的?」这样的尴尬情况。
此外,良好的命名还应当便于搜索。当我们使用集成开发环境(IDE)时,它能根据我们的命名规范快速定位到想要的类或方法。例如,输入「Hash」时,IDE会智能地列出所有与Hash相关的类,大大提高了编程效率。
在包命名方面,我们应遵循统一的习惯,使用小写字母,并确保点分隔符之间只有一个自然语义的英文单词或多个单词的自然连接。同时,包名的构成也有一定的规范,通常包括前缀、发起者名、项目名和模块名等部分。了解这些常见的前缀及其含义,有助于我们写出更符合规范、易于理解的代码。
个体项目
即由个人发起但并非独自完成的项目,既可以是公开的也可以是私有的,其版权主要归属于发起者。在命名时,我们可以采用“pers.个人名.项目名.模块名”的格式,例如“pers.张三.我的项目.模块一”。这类项目强调的是个人的创意和实现,其版权归属明确。
私有项目
也是个人发起并独自完成的,但它们通常是非公开的,仅供私人使用。这类项目的版权同样归属于个人,命名时可以采用“priv.个人名.项目名.模块名”的方式,例如“priv.李四.我的私有项目.模块二”。
团队项目
它们是由团队共同发起并开发的。这类项目的版权归属于该团队,命名时可以按照“team.团队名.项目名.模块名”的格式进行,例如“team.研发一队.我们的团队项目.模块三”。
公司项目
这类项目的版权由发起公司的所有,命名时可以采取“com.公司名.项目名.模块名”的方式,例如“com.华为公司.华为的项目.模块四”。
在具体的编程实践中,类名的命名也遵循一定的规范。类名通常使用大驼峰命名法,并且应该是名词或名词短语,比如“Customer”和“Account”。接口名的命名则更加灵活,可以使用名词、形容词或形容词短语,如“Cloneable”和“Callable”。
同时,还有一些特定的命名约定需要考虑。例如,抽象类通常以“Abstract”或“Base”开头,如“BaseUserService”;枚举类则以“Enum”作为后缀,如“GenderEnum”。此外,工具类通常以“Utils”作为后缀,异常类以“Exception”结尾。在实现接口时,也有特定的命名方式,如“接口名 + ImpI”或“前缀接口名 + 接口名”。
最后,与领域模型相关的类名也有特定的格式要求。例如,“UserDAO”是正确的命名方式,而“UserDo”和“UserDao”则可能被视为不规范的命名。在设计模式相关的类名中,需要使用对应的设计模式作为后缀,如“ThreadFactory”。这些命名规范有助于提高代码的可读性和可维护性。
Handler,Predicate, Validator
这些类名分别表示处理器、校验器和断言,它们都有配套的方法名,如handle、predicate和validate。
测试类
以Test结尾的类名,例如UserServiceTest,通常用于测试某个类,如UserService。
方法名
方法命名一般采用动词或动词短语,与参数或参数名共同构成动宾短语,例如“addUser”或“updateUser”。这样的命名方式使得函数的功能一目了然。
布尔返回值的方法
这类方法以is、can、should、has等前缀开头,用于判断对象的状态或能力。例如,“isValid”方法可能用于判断一个对象是否处于有效状态,“canRemove”方法则用于判断对象是否能够执行某种动作。
按需执行的方法
这类方法以IfNeeded、might、try等前缀开头,表示在满足特定条件时才执行的方法。例如,“drawIfNeeded”方法可能在需要时才绘制图形,“tryCreate”方法则尝试执行创建操作,失败时可能抛出异常或返回错误码。
用来检查的方法
这类方法通常以ensure等前缀开头,用于在执行某些操作前进行检查。例如,“ensureUserExists”方法可能在创建用户前检查用户是否存在。
检查是否达到预期状态,若未达到则抛出异常或返回错误码。
- `ensureCapacity`
- `validate`
这些方法用于确认对象或系统是否处于正确状态,若不符合预期,则会触发异常或返回相应的错误码。
异步相关方法:
- `blocking`:表示线程阻塞的方法,例如`blockingGetUser`。
- `InBackground`:在后台线程中执行的操作,如`doInBackground`。
- `Async`:异步执行的方法,例如`sendAsync`。
- `Sync`:与异步方法相对应的同步方法,例如`sendSync`。
此外,还有一系列与执行、调度和取消异步任务相关的方法,如`schedule`, `post`, `execute`, `start`, `cancel`, `stop`等,以及与事件回调相关的方法,如`onCompleted`, `beforeUpdate`, `preUpdate`, `willUpdate`, `afterUpdate`, `postUpdate`, `didUpdate`和`should`等。这些方法名清晰地表达了它们的意图和功能,有助于代码的可读性和维护性。
shouldUpdate
# 操作对象生命周期的方法
单词
意义
例
initialize
初始化。也可作为延迟初始化使用
initialize
pause
暂停
onPause ,pause
stop
停止
onStop,stop
abandon
销毁的替代
abandon
destroy
销毁
destroy
dispose
释放资源,同上
dispose
# 与集合操作相关的方法#
单词
意义
例
contains
判断是否包含指定对象
contains
add
添加元素到集合中
addJob, append, insertJob
remove
从集合中移除元素
removeJob
enqueue
将元素添加到队列的末尾
enqueueJob
dequeue
从队列头部移除并返回元素
dequeueJob
push
将元素添加到栈顶
pushJob
pop
从栈顶移除并返回元素
popJob
peek
查看栈顶元素但不移除
peekJob
find
在集合中查找符合条件的元素
findById
# 与数据相关的方法#
单词
意义
例
create
新创建数据对象,如创建账户等操作。createAccount, newAccount。fromConfig
从配置或现有数据中新建数据对象。fromConfig。to或convert,转换数据格式。toString。update或modify,更新现有数据对象的状态。updateAccount。load或retrieve,从数据库或缓存中读取数据。loadAccount, fetchAccount。delete或remove,删除现有数据对象。deleteAccount, removeAccount。save或persist,将数据对象保存到数据库或缓存中。saveAccount, storeAccount。commit或applyChanges,提交并保存对数据对象的更改。commitChange。applyChanges。
applyChange
clear
清除数据或是恢复到初始状态
clearAll
reset
重置数据或是恢复到初始状态
resetAll
接下来,我们来看看一些成对出现的动词及其意义:
- get与set:分别表示获取和设置数据。
- add与remove:用于增加和删除元素。
- create与destroy:创建和销毁对象或资源。
- start与stop:启动和停止某个进程或操作。
- open与close:打开和关闭文件、窗口或连接。
- read与write:读取和写入数据。
- load与save:载入和保存数据。
- backup与restore:进行数据备份和恢复。
此外,还有许多其他动词,如import、export、split、merge等,它们分别表示导入、导出、分割、合并等操作。这些动词涵盖了数据处理、系统操作、软件开发等多个方面的需求,是编程和软件开发中不可或缺的组成部分。
connect 连接
disconnect 断开
send 发送
receive 接收
download 下载
upload 上传
refresh 刷新
synchronize 同步
update 更新
revert 复原
lock 锁定
unlock 解锁
check out 签出
check in 签入
submit 提交
commit 交付
push 推送
pull 拉取
expand 展开
collapse 折叠
begin 开始
end 结束
start 启动
finish 完成
enter 进入
exit 退出
abort 中止
quit 退出
obsolete 废弃
depreciate 淘汰
collect 收集
aggregate 汇总
总结
这些动词的命名目的都是为了使代码与工程师能够进行更流畅的沟通,从而提高代码的可读性和可维护性。一个优秀的代码命名应该能够让人一目了然地理解其含义。各位在工作中是否曾遇到过命名不佳的代码呢?欢迎在留言区分享您的经验和见解。
首先我们可以来看下C++之父Bjarne Stroustrup对于好代码的定义。
> 我喜欢我的代码优雅且高效。 逻辑应该简单明了,这样 bug 就很难隐藏;依赖关系最小化,以便于维护;错误处理应该根据明确的策略完成;性能应该接近最佳,以免诱使人们通过无原则的优化使代码变得混乱。 干净的代码可以很好地完成一件事。
总体来说,优雅的代码具备如下特点:
- 阅读上赏心悦目,修改上得心应手。
- 代码简洁明了,尽量减少冗余和复杂性。
- 模块化,高内聚低耦合,便于维护和扩展。
- 可测试性,需要有UT、E2E保证代码的可修改性。
- 适当的注释和文档,解释代码的意图和实现细节。
现实中的代码
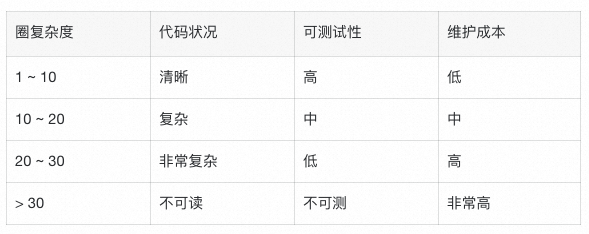
**圈复杂度**
圈复杂度(Cyclomatic Complexity)是一种代码复杂度的度量指标,用于衡量代码中的控制流路径的数量和复杂程度。它通过统计代码中的决策点(如条件语句和循环语句)来计算。
圈复杂度的值可以用于判断代码的复杂程度和测试的覆盖范围。较高的圈复杂度表示代码中存在更多的路径和可能的执行情况,增加了理解、维护和测试代码的难度。
**iLogtail代码复杂度探讨**
iLogtail 作为一款阿里云日志服务(SLS)团队自研的可观测数据采集器,目前已经在 Github 开源,其核心定位是帮助开发者构建统一的数据采集层。不仅仅是在功能、性能上表现突出,代码层面也一直在追求整洁优雅,详见《
跟着iLogtail学习设计模式
》。
iLogtail部分关键模块代码,代码行数跟圈复杂度基本是控制在比较合理的范畴。
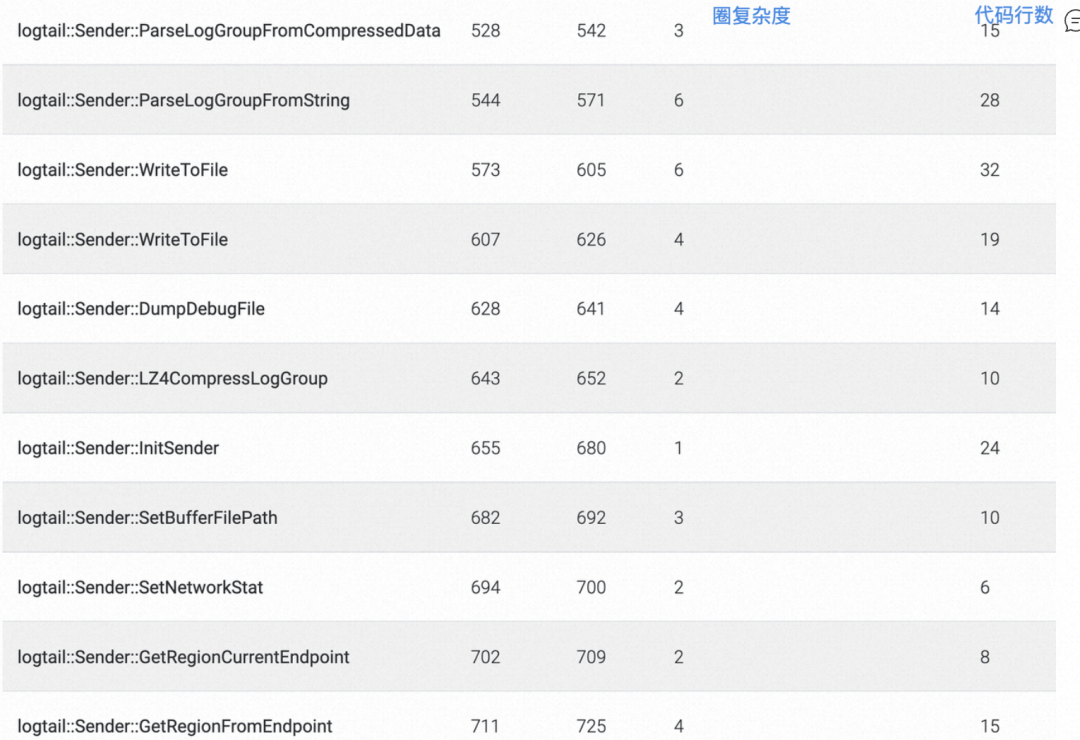
但是也存在少数代码,整体复杂度已经到了极度复杂的程度,严重影响了代码的可扩展性。例如,下图两个函数,563行代码/169圈复杂度 代码[1], 332行代码/71圈复杂度 代码[2]。

备注:以上圈复杂度基于 VSCode 插件 Codalyze [3]获取。
综上我们可以看出,对于一些简单的代码往往是比较容易控制好结构的;但是拥有着比较复杂的业务逻辑的代码,往往会不是那么优雅,而且随着时间的推移,复杂度会变得越来越高。
为什么造成这种局面?主要有以下几个原因:
- 业务逻辑复杂:业务逻辑复杂的代码,如果初期没有很好的设计导致不易扩展;后期又不断引入新的特性,加剧了代码的复杂度。
- 开发阶段时间紧张:为了快速开发使用重复或结构差的代码来实现,以及后面再补的思维。
- 缺乏代码重构:当代码不断变得不易维护时,开发人员没有进行及时意识到代码的坏味道,并进行有效的重构,导致代码越来越复杂。
- 缺乏单元测试和集成测试:导致历史代码没人敢动,只能维持现状。
接下来,我们结合实战手段介绍如何合理地利用重构跟设计模式两种手段避免代码腐化的问题。
重构
重构实际上是对代码的一种调整,目的是在不改变软件可观察行为的前提下,提升代码的扩展性和可理解性,降低维护成本。
**识别代码的坏味道**
就像破窗效应中提到的一样,干净优雅的代码会让开发者心生敬畏;而一旦代码中出现了一些小的问题或坏味道,如果不及时修复,日积月累最终将会导致代码的腐化。
因此,为了保证代码的质量,首先需要对代码中的坏味道有敏锐的识别能力。常见的坏味道:
- 过长函数
- 重复代码
- 过长参数列表
- 过多全局变量
- 霰弹式修改
- 冗余的注释
**重构的方式**
- 微重构
- - 开发新功能时:让新功能更易扩展。一般可以秉承事不过三的原则。
- 阅读一段代码时:让代码读起来更简单。
- Bugfix 和 CodeReview 时:发现旧代码的质量问题,并按计划根治解决。
- 模块级重构
- - 代码已经不堪重负,可维护性极差,严重阻碍开发迭代进度。
- 架构级重构
- - 代码结构已经跟不上架构发展的需求。
**重构从“战胜对老代码的恐惧”开始!**
面对复杂臃肿的老代码,开发者往往心生畏惧。但是只要秉承如下原则,重构也不再可怕。
- 重构前需要对整体有清晰的认识:架构设计梳理、模块间交互、周边交互。进而指导后续的重构过程。
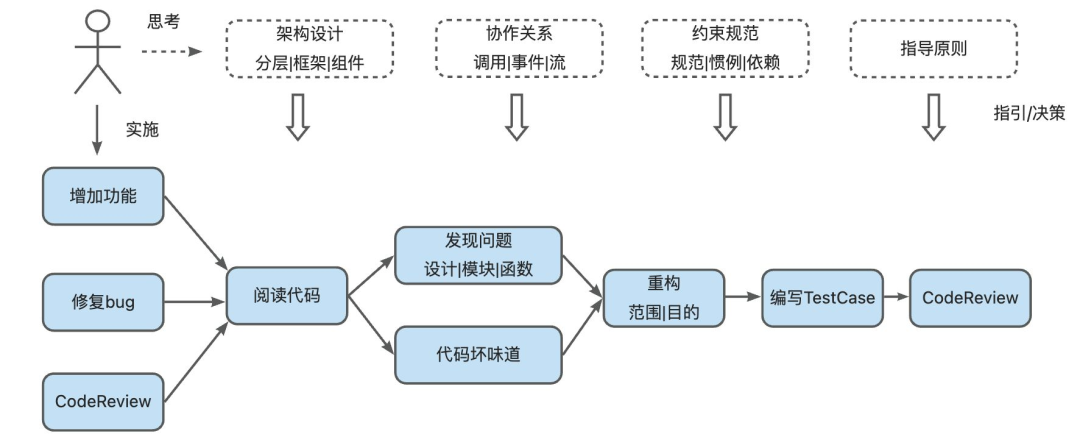
- 最主要的是测试先行,良好的测试体系是进行重构的关键。当然最理想的是测试(UT、E2E、Benchmark等)应该做到首次开发时、做到平时。
- 核心场景梳理,特别是可靠性场景、异常场景的处理以及微小的长尾细节。放过任何一处都可能是一个bug,而且有些微小细节的问题可能暴露的时间会很长。
最后,牢记细致认真是代码重构最重要的素养。
设计模式
**抽象与分层**
众所周知,程序员往往自嘲为码农。但是我认为码农跟程序员还是有本质区别的,这个区别就是抽象思维。码农只会CRUD,单点解决问题,导致只能埋头苦干;而程序员可以通过抽象思维解决,进行产品跟技术实现的归纳总结,一次解决更多通用需求。而软件技术本质上也是一门抽象的艺术。
抽象思维是程序员最重要的思维能力,抽象的过程就是寻找共性、归纳总结、综合分析,提炼出相关概念的过程。
- 抽象是忽略细节的。抽象类是最抽象的,忽略的细节也最多,就像抽象牛,只是几根线条而已。在代码中可以类比到 Abstract Class 或者 Interface。
- 抽象代表了共同性质。类(Class)代表了一组实例(Instance)的共同性质,抽象类(Abstract Class)代表了一组类的共同性质。
- 抽象具有层次性。抽象层次越高,内涵越小,外延越大,也就是说它的涵义越小,泛化能力越强。比如,牛就要比水牛更抽象,因为它可以表达所有的牛,水牛只是牛的一个种类(Class)。
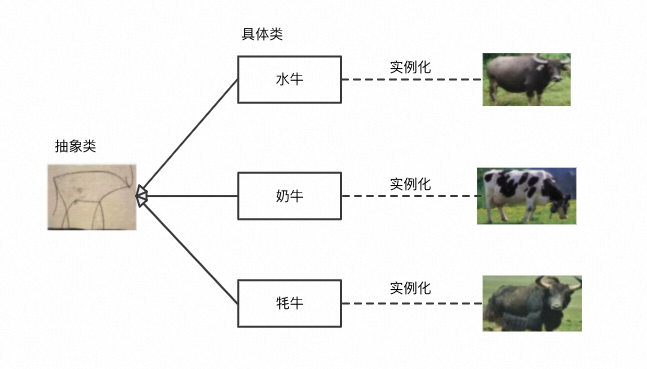
而设计模式是软件开发中抽象化思维的重要经验总结。总体上可以分为三类:
- 创建型模式:这些模式关注于对象的创建和初始化方式,用于解决对象创建的复杂性问题。创建型模式包括单例模式、工厂模式、抽象工厂模式、建造者模式和原型模式等。
- 结构型模式:这些模式关注于对象之间的关系,用于解决对象的组合和属性之间的问题。结构型模式包括适配器模式、桥接模式、组合模式、装饰器模式、外观模式、享元模式和代理模式等。
- 行为型模式:这些模式关注于对象之间的通信、交互和责任分配,用于解决对象之间的复杂交互问题。行为型模式包括责任链模式、命令模式、解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、模板方法模式和访问者模式等。
在《
跟着iLogtail学习设计模式
》一文中,深入阐述了多种设计模式的应用实践,这里不再一一介绍,而是从几个场景问题触发,探讨如何解决。
**场景1:如何避免冗长的if-else**
相信大家都见过如下代码,将处理逻辑的定义、创建、使用直接耦合在一起,代码特别冗长。
```
public class OrderService { public double discount(Order order) { double discount = 0.0; OrderType type = order.getType(); if (type.equals(OrderType.NORMAL)) { // 普通订单 //...省略折扣计算算法代码 } else if (type.equals(OrderType.GROUPON)) { // 团购订单 //...省略折扣计算算法代码 } else if (type.equals(OrderType.PROMOTION)) { // 促销订单 //...省略折扣计算算法代码 } return discount; }}
```
使用**策略模式**避免冗长的if-else/switch分支:将不同类型订单的打折策略设计成策略类,并由工厂类来负责创建策略对象。
```
// 定义策略接口
public interface DiscountStrategy { double calDiscount(Order order);}
// 具体策略实现// 省略NormalDiscountStrategy、GrouponDiscountStrategy、PromotionDiscountStrategy类代码...
// 建立策略工厂
public class DiscountStrategyFactory { private static final Map<OrderType, DiscountStrategy> strategies = new HashMap<>();
static { strategies.put(OrderType.NORMAL, new NormalDiscountStrategy()); strategies.put(OrderType.GROUPON, new GrouponDiscountStrategy()); strategies.put(OrderType.PROMOTION, new PromotionDiscountStrategy()); }
public static DiscountStrategy getDiscountStrategy(OrderType type) { return strategies.get(type); }}
// 策略的使用
public class OrderService { public double discount(Order order) { OrderType type = order.getType(); DiscountStrategy discountStrategy = DiscountStrategyFactory.getDiscountStrategy(type); return discountStrategy.calDiscount(order); }}
```
**场景2:善用组合**
假如有一个几何形状Shape类, 扩展出两个子类: 圆形Circle和 方形Square 。 现在需要引入颜色的因素,该如何实现?

**桥接模式**可将一个大类或一系列紧密相关的类拆分为抽象和实现两个独立的层次结构, 从而能在开发时分别使用。一个类存在两个(或多个)独立变化的维度,可以通过组合的方式,让这两个(或多个)维度可以独立进行扩展。
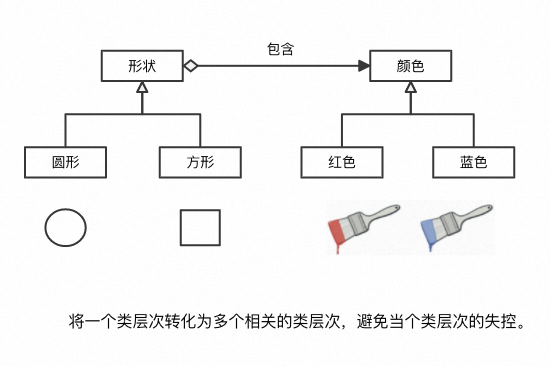
C#中,可以使用**桥接模式**(Bridge Pattern)来将形状(Shape)和颜色(Color)这两个维度分离,使它们可以独立变化。桥接模式的核心思想是通过组合而不是继承来实现解耦。
以下是实现步骤:
---
1. 定义颜色接口
首先,定义一个颜色接口 `IColor`,表示颜色的行为。
```csharp
public interface IColor
{
string ApplyColor();
}
```
---
2. 实现具体颜色类
创建具体的颜色类,实现 `IColor` 接口。
```csharp
public class Red : IColor
{
public string ApplyColor()
{
return "Red";
}
}
public class Blue : IColor
{
public string ApplyColor()
{
return "Blue";
}
}
```
---
3. 定义形状抽象类
在形状抽象类 `Shape` 中,引入颜色接口 `IColor`,并通过构造函数或属性注入颜色。
```csharp
public abstract class Shape
{
protected IColor color;
public Shape(IColor color)
{
this.color = color;
}
public abstract void Draw();
}
```
---
4. 实现具体形状类
创建具体的形状类,继承 `Shape` 并实现 `Draw` 方法。
```csharp
public class Circle : Shape
{
public Circle(IColor color) : base(color) { }
public override void Draw()
{
Console.WriteLine($"Drawing a {color.ApplyColor()} Circle");
}
}
public class Square : Shape
{
public Square(IColor color) : base(color) { }
public override void Draw()
{
Console.WriteLine($"Drawing a {color.ApplyColor()} Square");
}
}
```
---
5. 使用桥接模式
在客户端代码中,可以自由组合形状和颜色。
```csharp
class Program
{
static void Main(string[] args)
{
IColor red = new Red();
IColor blue = new Blue();
Shape redCircle = new Circle(red);
Shape blueSquare = new Square(blue);
redCircle.Draw(); // 输出: Drawing a Red Circle
blueSquare.Draw(); // 输出: Drawing a Blue Square
}
}
```
---
桥接模式的优点
1. **解耦**:将形状和颜色分离,使它们可以独立扩展。
2. **灵活性**:可以动态组合形状和颜色,而不需要修改现有代码。
3. **可扩展性**:添加新的形状或颜色时,只需实现新的类,无需修改现有类。
---
总结
通过桥接模式,你可以轻松地将形状和颜色这两个维度解耦,使系统更加灵活和可扩展。如果需要添加新的形状或颜色,只需实现新的类即可,符合**开闭原则**(Open/Closed Principle)。
**场景3:巧用适配器模式提高系统的可扩展性**
适配器模式将一种类型的接口转换成希望的另一类接口,使得原本接口不兼容对象能够一起配合工作。适配器接受客户端通过适配器接口发起的调用, 并将其转换为适用于被封装服务对象的调用。
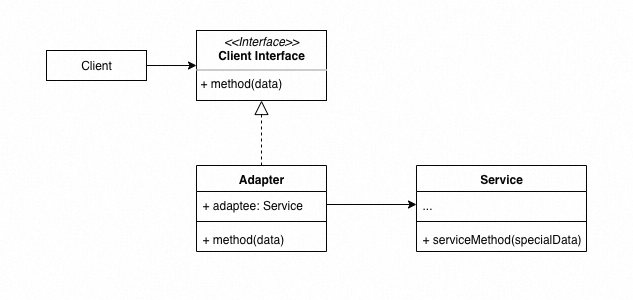
我们的系统当中,往往会依赖各种各样的外部系统,合理地利用适配器模式可以达到如下效果:
- 外部系统的可替代性:当需要把项目中依赖的一个外部系统替换为另一个外部系统的时候(例如日志系统从Elasticsearch切换到SLS),利用适配器模式可以减少对代码的改动及测试复杂度。
- 多外部系统接口统一:某个功能的实现依赖多个外部系统,通过适配器模式,将它们的接口适配为统一的接口定义,然后就可以使用多态的特性来复用代码逻辑。
- 兼容老版本接口:在做版本升级的时候,对于一些要废弃的接口,往往不直接将其删除,而是暂时保留,并且标注为deprecated,并将内部实现逻辑委托为新的接口实现。这样做的好处是,让使用它的项目有个过渡期,而不是强制进行代码修改。
以下是一些优秀的开源C#项目,它们以代码整洁、架构清晰和设计优雅著称,适合学习和参考:
---
1. **eShopOnContainers**
- **简介**:由Microsoft提供的基于微服务架构的示例项目,展示了如何使用.NET Core和Docker构建现代化的分布式应用。
- **特点**:
- 清晰的领域驱动设计(DDD)实现。
- 使用CQRS(命令查询职责分离)和事件驱动架构。
- 包含完整的微服务示例(订单、购物车、支付等)。
- **GitHub地址**:https://github.com/dotnet-architecture/eShopOnContainers
---
2. **CleanArchitecture**
- **简介**:由Steve Smith(Ardalis)提供的整洁架构(Clean Architecture)模板项目。
- **特点**:
- 遵循Robert C. Martin的Clean Architecture原则。
- 清晰的层次结构(核心层、应用层、基础设施层、表现层)。
- 包含单元测试和集成测试。
- **GitHub地址**:https://github.com/ardalis/CleanArchitecture
---
3. **NorthwindTraders**
- **简介**:一个基于领域驱动设计(DDD)的示例项目,展示了如何将DDD应用于实际业务场景。
- **特点**:
- 使用EF Core实现领域模型持久化。
- 清晰的聚合根、实体和值对象设计。
- 包含CQRS和MediatR的实现。
- **GitHub地址**:https://github.com/jasontaylordev/NorthwindTraders
---
4. **AspNetCore-CleanArchitecture**
- **简介**:一个基于ASP.NET Core的整洁架构示例项目。
- **特点**:
- 清晰的层次分离(核心、应用、基础设施、表现层)。
- 使用MediatR实现CQRS。
- 包含JWT身份验证和Swagger文档支持。
- **GitHub地址**:https://github.com/iammukeshm/AspNetCore-CleanArchitecture
---
5. **CAP**
- **简介**:一个分布式事务解决方案,基于事件总线的最终一致性模式。
- **特点**:
- 代码结构清晰,模块化设计。
- 支持多种消息队列(RabbitMQ、Kafka、Azure Service Bus等)。
- 适用于微服务架构。
- **GitHub地址**:https://github.com/dotnetcore/CAP
---
6. **Orleans**
- **简介**:由Microsoft开发的分布式 actor 模型框架,用于构建高并发、分布式应用。
- **特点**:
- 代码整洁,设计优雅。
- 支持水平扩展和容错。
- 适用于游戏服务器、物联网等场景。
- **GitHub地址**:https://github.com/dotnet/orleans
---
7. **MediatR**
- **简介**:一个轻量级的Mediator模式实现,用于解耦应用程序中的请求和响应。
- **特点**:
- 代码简洁,易于理解。
- 支持CQRS和管道行为(Pipeline Behaviors)。
- 广泛应用于整洁架构和领域驱动设计项目。
- **GitHub地址**:https://github.com/jbogard/MediatR
---
8. **Dapper**
- **简介**:一个轻量级的ORM库,专注于高性能的数据库访问。
- **特点**:
- 代码简洁,易于扩展。
- 支持原生SQL查询。
- 适合需要直接控制SQL的场景。
- **GitHub地址**:https://github.com/DapperLib/Dapper
---
9. **FluentValidation**
- **简介**:一个用于构建强类型验证规则的库。
- **特点**:
- 代码整洁,易于使用。
- 支持链式调用和自定义验证规则。
- 广泛应用于ASP.NET Core项目。
- **GitHub地址**:https://github.com/FluentValidation/FluentValidation
---
10. **Serilog**
- **简介**:一个高性能的日志记录库,支持结构化日志。
- **特点**:
- 代码模块化,易于扩展。
- 支持多种日志存储(文件、数据库、Elasticsearch等)。
- 广泛应用于现代.NET应用。
- **GitHub地址**:https://github.com/serilog/serilog
---
11. **MiniProfiler**
- **简介**:一个用于性能分析的轻量级库。
- **特点**:
- 代码简洁,易于集成。
- 支持SQL查询分析和性能监控。
- 广泛应用于Web应用。
- **GitHub地址**:https://github.com/MiniProfiler/dotnet
---
12. **AutoMapper**
- **简介**:一个对象映射库,用于简化对象之间的转换。
- **特点**:
- 代码简洁,易于配置。
- 支持复杂对象映射和自定义转换规则。
- 广泛应用于DTO(数据传输对象)映射。
- **GitHub地址**:https://github.com/AutoMapper/AutoMapper
---
13. **Polly**
- **简介**:一个弹性和瞬态故障处理库。
- **特点**:
- 代码模块化,易于使用。
- 支持重试、熔断、超时等策略。
- 适合处理分布式系统中的故障。
- **GitHub地址**:https://github.com/App-vNext/Polly
---
14. **NodaTime**
- **简介**:一个用于处理日期和时间的库,替代.NET内置的`DateTime`。
- **特点**:
- 代码设计优雅,功能强大。
- 支持时区、日历系统等高级功能。
- 广泛应用于需要精确时间处理的场景。
- **GitHub地址**:https://github.com/nodatime/nodatime
---
15. **LanguageExt**
- **简介**:一个函数式编程库,为C#提供了函数式编程的特性。
- **特点**:
- 代码设计优雅,功能丰富。
- 支持不可变数据、Option、Either等函数式概念。
- 适合需要函数式编程风格的项目。
- **GitHub地址**:https://github.com/louthy/language-ext
---
总结
以上项目涵盖了从架构设计、领域驱动设计、微服务、工具库到函数式编程的多个方面。通过学习和参考这些项目的代码,你可以更好地理解如何编写整洁、可维护的C#代码。
一、[命名规则](https://zhida.zhihu.com/search?content_id=250260935&content_type=Article&match_order=1&q=%E5%91%BD%E5%90%8D%E8%A7%84%E5%88%99&zhida_source=entity)
| 类别 | 命名规则 | 示例 |
| ------------ | ------------------------------------------------------------ | ----------------------------------------------------- |
| 变量命名 | - 使用小写字母,单词间使用驼峰式命名 - 变量名应简洁且具有描述性 | playerHealth, scoreValue |
| 常量命名 | - 使用大写字母,单词间使用下划线连接 - 常量名应为描述性名词 | MAX_SPEED, DEFAULT_COLOR |
| 函数命名 | - 使用动词,驼峰式命名 - 函数名应描述其功能和行为 | initializeGame(), loadData() |
| 类命名 | - 使用名词,首字母大写(Pascal Case) - 类名应表示某个实体或概念 | PlayerController, GameManager |
| 接口命名 | - 以I开头,后接名词(Pascal Case) - 接口应描述行为或能力 | IUserData, INetworkService |
| 枚举命名 | - 使用名词复数形式(Pascal Case) - 枚举表示一组相关常量 | GameStates, ErrorCodes |
| 参数命名 | - 使用描述性名称 - 参数名应该简洁且清晰,避免使用单字母参数 | userId, fileName |
| 命名空间命名 | - 使用公司或项目名作为前缀 - 按模块或功能进行划分 | MyCompany.MyProject.UI, MyCompany.MyProject.GameLogic |
二、[命名约定](https://zhida.zhihu.com/search?content_id=250260935&content_type=Article&match_order=1&q=%E5%91%BD%E5%90%8D%E7%BA%A6%E5%AE%9A&zhida_source=entity)实例
| 命名类型 | 命名规范 | 示例 |
| ------------ | ---------------------------- | ----------------------------------------- |
| 变量命名 | - 小写字母,驼峰式命名 | playerScore, enemyHealth |
| 常量命名 | - 大写字母,单词间用下划线 | MAX_HEALTH, DEFAULT_SPEED |
| 函数命名 | - 动词,描述性命名 | startGame(), loadLevel() |
| 类命名 | - 名词,首字母大写(Pascal) | Player, GameManager |
| 接口命名 | - 以I开头,首字母大写 | IUserAuthentication, IDataService |
| 枚举命名 | - 名词复数,首字母大写 | GameStates, WeaponTypes |
| 参数命名 | - 描述性名称 | filePath, userAge |
| 命名空间命名 | - 公司或项目名前缀,功能划分 | MyCompany.GameEngine, MyCompany.Utilities |
三、[命名原则](https://zhida.zhihu.com/search?content_id=250260935&content_type=Article&match_order=1&q=%E5%91%BD%E5%90%8D%E5%8E%9F%E5%88%99&zhida_source=entity)
| 原则 | 描述 |
| ------------------ | ------------------------------------------------------------ |
| 简洁明了 | 变量、函数和类名应简洁而富有描述性,避免冗长。 |
| 避免缩写 | 除非是通用缩写(如 URL, ID),否则避免使用缩写。 |
| 一致性 | 在整个项目中保持命名规则的一致性。 |
| 避免使用数字 | 除非数字是必需的(如版本号),否则尽量避免在命名中使用数字。 |
| 避免使用单字母变量 | 除非用于循环或数学公式中的常见情况,避免使用单字母变量(如i, j)。 |
| 避免多义性 | 使用清晰的命名,避免在不同上下文中使用相同的名称,导致歧义。 |
四、[命名示例](https://zhida.zhihu.com/search?content_id=250260935&content_type=Article&match_order=1&q=%E5%91%BD%E5%90%8D%E7%A4%BA%E4%BE%8B&zhida_source=entity)
| 命名类别 | 示例 | 不推荐的示例 |
| ------------ | ------------------------------------------------ | ----------------------------------- |
| 变量命名 | playerHealth, enemyScore, playerName | pH, eS, nameOfPlayer |
| 常量命名 | MAX_SPEED, PI, DEFAULT_FONT_SIZE | maxSpeed, piValue, fontSizeDefault |
| 函数命名 | calculateTotal(), initializeGame(), loadAssets() | calcTotal(), initGame(), load() |
| 类命名 | PlayerController, InventoryManager, GameSettings | playercontroller, inventorymanager |
| 接口命名 | IUserData, IDatabaseService, INetworkHandler | userDataInterface, databaseService |
| 枚举命名 | GameStates, LogLevels, WeaponTypes | game_state, log_level, weapon_types |
| 命名空间命名 | MyCompany.GameEngine, MyCompany.Utilities | company.game, utils.tools |
在《代码整洁之道》(*Clean Code*)一书中,Robert C. Martin 强调了**对象**和**数据结构**的区别,并提出了如何编写整洁代码的建议。在C#中,遵循这些原则可以帮助我们编写更清晰、更易维护的代码。
---
对象和数据结构的核心区别
1. **对象**:
- 封装数据和行为。
- 隐藏实现细节,暴露抽象的接口。
- 适合处理复杂的业务逻辑。
2. **数据结构**:
- 只暴露数据,不包含行为。
- 数据通常是公开的,行为由外部函数处理。
- 适合处理简单的数据传递。
---
整洁代码的原则
1. **单一职责原则**:每个类或方法只做一件事。
2. **开闭原则**:对扩展开放,对修改关闭。
3. **里氏代换原则**:子类可以替换父类。
4. **接口隔离原则**:接口应该小而专。
5. **依赖倒置原则**:依赖于抽象,而不是具体实现。
---
示例:对象 vs 数据结构
1. 使用对象(面向对象编程)
对象封装了数据和行为,适合处理复杂的业务逻辑。
```csharp
// 对象:封装数据和行为
public class Circle
{
public double Radius { get; private set; }
public Circle(double radius)
{
if (radius <= 0)
throw new ArgumentException("Radius must be positive.");
Radius = radius;
}
public double CalculateArea()
{
return Math.PI * Radius * Radius;
}
}
// 使用
var circle = new Circle(5);
double area = circle.CalculateArea(); // 调用对象的行为
```
**优点**:
- 封装了数据和行为,隐藏了实现细节。
- 易于扩展和维护。
- 符合面向对象的设计原则。
---
2. 使用数据结构(过程式编程)
数据结构只包含数据,行为由外部函数处理。
```csharp
// 数据结构:只包含数据
public struct CircleData
{
public double Radius;
}
// 外部函数:操作数据结构
public static class CircleOperations
{
public static double CalculateArea(CircleData circle)
{
if (circle.Radius <= 0)
throw new ArgumentException("Radius must be positive.");
return Math.PI * circle.Radius * circle.Radius;
}
}
// 使用
var circleData = new CircleData { Radius = 5 };
double area = CircleOperations.CalculateArea(circleData); // 外部函数操作数据
```
**优点**:
- 数据与行为分离,适合处理简单的数据。
- 数据结构可以被多个函数复用。
- 适合处理纯数据场景,如数据传输对象(DTO)。
---
如何选择对象 vs 数据结构?
1. **使用对象**:
- 当数据和行为密切相关时。
- 当需要封装复杂逻辑时。
- 当需要支持多态和继承时。
2. **使用数据结构**:
- 当数据是简单的、不需要复杂行为时。
- 当需要将数据与行为分离时。
- 当处理纯数据场景时,如 DTO、数据库记录等。
---
整洁代码的最佳实践
1. 使用对象时的最佳实践
- **封装数据**:使用私有字段和公共属性控制数据的访问。
- **单一职责**:每个类只负责一件事。
- **避免暴露内部细节**:通过方法暴露行为,而不是直接暴露数据。
```csharp
public class Employee
{
public string Name { get; private set; }
public decimal Salary { get; private set; }
public Employee(string name, decimal salary)
{
Name = name;
Salary = salary;
}
public void ApplyRaise(decimal percentage)
{
if (percentage <= 0)
throw new ArgumentException("Percentage must be positive.");
Salary *= (1 + percentage / 100);
}
}
```
---
2. 使用数据结构时的最佳实践
- **保持简单**:数据结构只包含数据,不包含行为。
- **使用不可变数据结构**:避免数据被意外修改。
- **分离行为**:将行为放在外部函数中。
```csharp
public struct Point
{
public int X { get; }
public int Y { get; }
public Point(int x, int y)
{
X = x;
Y = y;
}
}
public static class Geometry
{
public static double CalculateDistance(Point p1, Point p2)
{
return Math.Sqrt(Math.Pow(p2.X - p1.X, 2) + Math.Pow(p2.Y - p1.Y, 2));
}
}
```
---
结合对象和数据结构
在实际开发中,对象和数据结构可以结合使用。例如,使用对象封装核心业务逻辑,使用数据结构处理数据传输。
```csharp
// 对象:封装核心逻辑
public class Circle
{
public double Radius { get; private set; }
public Circle(double radius)
{
if (radius <= 0)
throw new ArgumentException("Radius must be positive.");
Radius = radius;
}
public double CalculateArea()
{
return Math.PI * Radius * Radius;
}
}
// 数据结构:用于数据传输
public struct CircleData
{
public double Radius;
}
// 使用
var circle = new Circle(5);
var circleData = new CircleData { Radius = circle.Radius };
// 将数据结构转换为对象
var newCircle = new Circle(circleData.Radius);
```
---
总结
- **对象** 适合封装数据和行为,处理复杂的业务逻辑。
- **数据结构** 适合处理简单的、纯数据的场景。
- 遵循整洁代码的原则(如单一职责、开闭原则等),可以提高代码的可读性、可维护性和可扩展性。
- 在实际开发中,根据需求灵活选择对象或数据结构,甚至结合两者使用。
# C#并发编程
C#提供了强大的并发编程支持,包括异步编程模型、并行库和线程安全集合等。以下是编写整洁、高效C#并发代码的核心原则和实践。
1. 异步编程最佳实践
1.1 使用async/await模式
```csharp
// 良好的异步方法示例
public async Task<string> DownloadContentAsync(string url)
{
using (var client = new HttpClient())
{
return await client.GetStringAsync(url);
}
}
```
1.2 避免async void
```csharp
// 错误做法
public async void BadMethod() { ... }
// 正确做法 - 返回Task
public async Task GoodMethod() { ... }
```
2. 线程安全实践
2.1 不可变类型
```csharp
// 线程安全的不可变类
public sealed class ImmutableData
{
public int Value { get; }
public string Name { get; }
public ImmutableData(int value, string name)
{
Value = value;
Name = name;
}
}
```
2.2 同步控制
```csharp
// 使用lock关键字
private readonly object _lockObj = new object();
private int _counter;
public void Increment()
{
lock (_lockObj)
{
_counter++;
}
}
```
3. 并发集合
3.1 使用System.Collections.Concurrent
```csharp
// 线程安全集合示例
var concurrentDict = new ConcurrentDictionary<string, int>();
concurrentDict.TryAdd("key", 1);
var blockingCollection = new BlockingCollection<int>();
blockingCollection.Add(42);
```
3.2 生产者-消费者模式实现
```csharp
BlockingCollection<WorkItem> _workQueue = new BlockingCollection<WorkItem>();
// 生产者
_workQueue.Add(new WorkItem(...));
// 消费者
foreach (var item in _workQueue.GetConsumingEnumerable())
{
ProcessItem(item);
}
```
4. 并行编程
4.1 Parallel类
```csharp
// 并行处理数据
Parallel.For(0, 100, i =>
{
DoWork(i);
});
// 并行LINQ
var results = from item in data.AsParallel()
where item.IsValid
select item.Process();
```
4.2 Task Parallel Library (TPL)
```csharp
// 创建并运行任务
var task = Task.Run(() => ComputeSomething());
// 任务延续
task.ContinueWith(t =>
{
Console.WriteLine($"Result: {t.Result}");
}, TaskScheduler.FromCurrentSynchronizationContext());
```
5. 避免常见陷阱
5.1 死锁预防
```csharp
// 使用超时防止死锁
if (Monitor.TryEnter(_lockObj, TimeSpan.FromSeconds(30)))
{
try
{
// 临界区代码
}
finally
{
Monitor.Exit(_lockObj);
}
}
```
5.2 异步上下文问题
```csharp
// 在UI线程外捕获上下文
async Task LoadDataAsync()
{
// 在UI线程启动
var data = await GetDataAsync().ConfigureAwait(false);
// 现在在线程池线程
// 需要返回UI线程更新UI
await Dispatcher.InvokeAsync(() => UpdateUI(data));
}
```
6. 测试并发代码
6.1 单元测试异步代码
```csharp
[TestMethod]
public async Task TestDownloadAsync()
{
var service = new DownloadService();
string result = await service.DownloadContentAsync("http://example.com");
Assert.IsNotNull(result);
}
```
6.2 压力测试
```csharp
[TestMethod]
public void TestConcurrentAccess()
{
var counter = new ThreadSafeCounter();
Parallel.For(0, 1000, i => counter.Increment());
Assert.AreEqual(1000, counter.Value);
}
```
7. 代码组织建议
7.1 文档化并发行为
```csharp
/// <summary>
/// 线程安全缓存实现。
/// 注意:GetOrAdd操作不是原子的,必要时外部同步。
/// </summary>
public class ThreadSafeCache
{
// 实现...
}
```
7.2 使用CancellationToken
```csharp
public async Task LongRunningOperationAsync(CancellationToken cancellationToken)
{
while (!cancellationToken.IsCancellationRequested)
{
await Task.Delay(1000, cancellationToken);
// 执行工作
}
}
```
8. 高级模式
8.1 数据流(TDF)
```csharp
var bufferBlock = new BufferBlock<int>();
var actionBlock = new ActionBlock<int>(n =>
Console.WriteLine(n));
bufferBlock.LinkTo(actionBlock);
bufferBlock.Post(42);
bufferBlock.Complete();
```
8.2 异步流(C# 8.0+)
```csharp
public async IAsyncEnumerable<int> GenerateSequenceAsync()
{
for (int i = 0; i < 20; i++)
{
await Task.Delay(100);
yield return i;
}
}
// 消费
await foreach (var number in GenerateSequenceAsync())
{
Console.WriteLine(number);
}
```
记住C#并发编程的核心原则:
1. 首选异步而非原始线程
2. 使用高级抽象(TPL, 并发集合)而非低级同步
3. 最小化共享状态
4. 明确文档化并发行为
5. 合理处理取消和超时
你想了解《代码整洁之道》(*Clean Code*)的原则如何在C#中应用于避免死锁。我会结合《代码整洁之道》的思想,讲解死锁在C#中的表现,并提供具体的代码示例和解决方案。
# C#中的死锁
《代码整洁之道》强调代码的可读性、简洁性和可维护性。在C#的并发编程中,这些原则可以帮助我们避免死锁问题,比如通过清晰的锁命名、避免过度复杂的同步逻辑、以及将并发代码的责任分离。
C#中的死锁
在C#中,死锁通常发生在使用`lock`语句(基于`Monitor`)或其他同步机制(如`Mutex`或`Semaphore`)时,多个线程互相等待对方释放资源。以下是一个典型的死锁场景:
死锁示例
```csharp
class Program
{
static object lock1 = new object();
static object lock2 = new object();
static void Main()
{
Thread thread1 = new Thread(() =>
{
lock (lock1)
{
Console.WriteLine("Thread 1: Locked lock1");
Thread.Sleep(100); // 模拟工作
lock (lock2)
{
Console.WriteLine("Thread 1: Locked lock2");
}
}
});
Thread thread2 = new Thread(() =>
{
lock (lock2)
{
Console.WriteLine("Thread 2: Locked lock2");
Thread.Sleep(100); // 模拟工作
lock (lock1)
{
Console.WriteLine("Thread 2: Locked lock1");
}
}
});
thread1.Start();
thread2.Start();
thread1.Join();
thread2.Join();
}
}
```
运行这段代码,可能会因为`thread1`持有`lock1`并等待`lock2`,而`thread2`持有`lock2`并等待`lock1`,导致死锁。
结合《代码整洁之道》改进代码
以下是基于《代码整洁之道》原则改进的建议和C#实现:
1. **固定锁顺序(避免循环等待)**
确保所有线程以相同的顺序获取锁,这是避免死锁的经典方法。代码应清晰表达这一意图。
```csharp
class ResourceManager
{
private readonly object _primaryLock = new object();
private readonly object _secondaryLock = new object();
public void AccessResources()
{
// 始终先锁_primaryLock,再锁_secondaryLock
lock (_primaryLock)
{
Console.WriteLine("Locked primary resource");
lock (_secondaryLock)
{
Console.WriteLine("Locked secondary resource");
// 操作资源
}
}
}
}
```
- **整洁之道原则**:命名清晰(`_primaryLock`和`_secondaryLock`表明锁的优先级),逻辑简单。
2. **减少锁范围(短小函数)**
将锁的范围尽量缩小,避免在锁内执行过多逻辑。
```csharp
class Account
{
private readonly object _balanceLock = new object();
private decimal _balance;
public void Transfer(Account target, decimal amount)
{
Account first = this.GetHashCode() < target.GetHashCode() ? this : target;
Account second = this.GetHashCode() < target.GetHashCode() ? target : this;
lock (first._balanceLock)
{
lock (second._balanceLock)
{
Withdraw(amount);
target.Deposit(amount);
}
}
}
private void Withdraw(decimal amount)
{
_balance -= amount; // 简单操作,无需锁
}
private void Deposit(decimal amount)
{
_balance += amount; // 简单操作,无需锁
}
}
```
- **整洁之道原则**:函数职责单一(`Withdraw`和`Deposit`独立),锁范围最小化。
3. **使用高级并发工具**
C#提供了`Task`和`async/await`,结合`SemaphoreSlim`等工具,可以减少手动锁的使用,从而降低死锁风险。
```csharp
class AsyncResourceManager
{
private readonly SemaphoreSlim _semaphore = new SemaphoreSlim(1, 1);
public async Task AccessResourceAsync()
{
await _semaphore.WaitAsync();
try
{
Console.WriteLine("Resource accessed");
await Task.Delay(100); // 模拟异步工作
}
finally
{
_semaphore.Release();
}
}
}
```
- **整洁之道原则**:代码简洁,避免嵌套锁,异常安全(`finally`确保释放)。
4. **超时机制**
使用`Monitor.TryEnter`代替`lock`,设置超时以避免无限等待。
```cosharp
class SafeResourceAccessor
{
private readonly object _resourceLock = new object();
public bool TryAccessResource()
{
if (Monitor.TryEnter(_resourceLock, TimeSpan.FromSeconds(1)))
{
try
{
Console.WriteLine("Resource accessed");
Thread.Sleep(100); // 模拟工作
return true;
}
finally
{
Monitor.Exit(_resourceLock);
}
}
Console.WriteLine("Failed to acquire lock");
return false;
}
}
```
- **整洁之道原则**:健壮性(超时避免死锁),意图清晰。
总结
在C#中结合《代码整洁之道》处理死锁,核心是:
- 使用有意义的命名和简单的结构。
- 遵循锁顺序或最小化锁使用。
- 优先考虑现代并发工具(如`async/await`和`SemaphoreSlim`)。
- 通过短小函数和单一职责减少复杂性。
如果你有具体的C#代码想分析,或者想深入某个场景(比如ASP.NET中的死锁),请告诉我,我可以进一步帮你优化!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









