







目录
概述
划分方法、层次、基于密度、基于网格

划分方法
Kmean算法

kmean算法不能保证收敛于与全局最优,收敛结果依赖于初始化中心的选择。实际应用常用不用的初始化中心进行多次Kmean
keam是基于最小化SSE的划分方法
缺陷:
- 需要预设簇数
k
- 不适合非凸形状的簇
- 不适合簇的样本数差别悬殊的情况
- 易受到异常值影响
K中心法
k中心法的典型算法是PAM:Partitioning Around Medoids
详细步骤参考:https://en.wikipedia.org/wiki/K-medoids#Step_1
算法流程:
1 在数据集中随机选择不重复的
2 按就近原则对余下样本进行划分
3 对于簇
i
(其中
3.1 随机选择簇中一个非中心点
orandom
,用
orandom
代替
oi
。现在备选中心点集合为
o1
,
o2
,···,
orandom
,···,
ok
3.2 按就近原则对余下
n−k
个样本进行划分,并计算总体损失,如果整体损失下降,用
orandom
代替
oi
。
4 重复步骤3,直到达到迭代上限或损失不再明显下降
基本思想:最小化代表对象和所有对象的绝对误差L1。其代价函数为对用于簇中心代表对象的平均绝对误差
改进
PAM鲁棒性比Kmean强,但复杂度大大提高,为了适应大规模的数据集,出现改进算法CLEARA(Clustering LARge Application,大型应用聚类)。
CLEARA是对数据集进行随机抽样,然后抽样数据集上进行PAM
层次聚类
层次聚类又称系统聚类,层次聚类的一个关键点在于选择合适的簇间距离度量方式
簇间距离
层次聚类的关键是选择合适的簇间距离计算方式,设簇
M
为
以下是几种常见的簇间距离1
最小距离
递推一下得:
DMJ=mini∈GMj∈GJ(dij)=min{DKJ,DLJ}
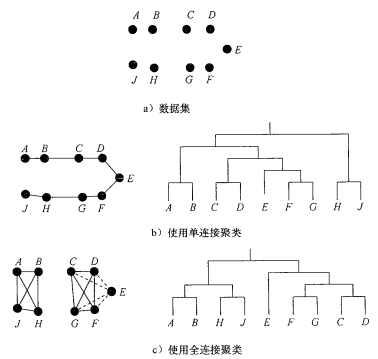
最短距离又称单链接距离,用最短距离的层次聚类又称最小生成树算法,效果如下图
最长距离
DKL=maxi∈GKj∈GL(dij)
递推一下得:
DMJ=maxi∈GMj∈GJ(dij)=max{DKJ,DLJ}
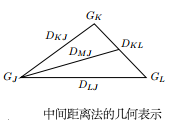
中间距离(median method)
D2KL=1/2D2KJ+1/2D2LJ−1/4D2KL
几何示意图如下:
类平均距离
类平均法有两种定义
定义1
DKL=1nKnL∑dij
递推公式:
DMJ=1nMnL∑dij=nKnMDKJ+nLnMDLJ
定义2
D2KL=1nKnL∑d2ij
递推公式
D2MJ=1nMnL∑d2ij=nKnMD2KJ+nLnMD2LJ
重心法
D2KL=(x¯K−x¯L)T(x¯K−x¯L)
递推公式:
D2MJ=nKnMD2KJ+nLnMD2LJ−nKnLn2MD2KL
重心法对异常值和离群值的鲁棒性高
Ward
WK=∑(xi−x¯K)T(xi−x¯K)
WJ=∑(xi−x¯J)T(xi−x¯J)
WM=∑(xi−x¯M)T(xi−x¯M)
则
D2KL=WM−WK−WJ=nKnLnM(x¯K−x¯L)T(x¯K−x¯L)
递推公式:
D2MJ=nJ+nKnJ+nMD2KJ+nL+nJnJ+nMD2LJ−nJnJ+nMD2KL
Ward和重心法只差一个常数,重心法和类间距离和样本数无关,而Ward的值受样本数大的影响较大,当两个簇的样本数很大时候距离会很大,则不易合并
Ward对异常值敏感
总结
最小距离:擅长处理非椭圆形状的簇;对噪声和离群点敏感
最大距离:对噪声和离群点不敏感;偏好球形簇
Ward:
Ward和重心法只差一个常数,重心法和类间距离和样本数无关,而Ward的值受样本数大的影响较大,当两个簇的样本数很大时候距离会很大,则不易合并
Ward对异常值敏感
基于密度
(略)
基于网格
(略)
聚类评估
聚类评估主要有以下三个内容
1 估计聚类趋势:评估数据分布是否有聚类的意义
2 确定簇数
3 聚类质量评估
聚类趋势
聚类趋势度量指数据集是否有聚类的价值,如果数据集是随机均匀地分布,则聚类的价值很低。
评估指标
Hopkins统计量2
确定簇数
Kmean和PAM等算法都需要设置簇数,下面有一些统计量用于选择类别数K
经验值
一个简单的经验方法是对于n个数据样本的数据集,簇数可以选择为 n/2−−−√
对于层次聚类的簇数确定3
R2
统计量
R2=1−PG/T
其中
PG
为簇数G的总类内离差平方和,
T
为所有变量的总离差平方和。
半偏相关
把类
CK
和
CL
合并为
CM
时,半偏相关系数为
R2=BKL/T
其中 BKL 为合并类导致的内类离差平方和增量。系数越大说明两个类不应该合并
伪F统计量
F=(T−PG)/(G−1)PG/(n−G)
选择伪F统计量较大,而类数较小的聚类结果
伪t统计量
t2=BKL(WK−WL)/(NK+NL−2)
此统计量用于评价类K和L合并的效果,如果值大这说明不应该合并
聚类簇评估4:
非监督评估方法
1 划分聚类评估
在数据挖掘导论中,对于划分方法的评估主要针对基于原型和图两种簇类型进行评估。
基于凝聚和分离的度量
对于原型和图两种不同的簇类型,仅仅是在计算凝聚度和分离度上存在差异,单整体思想是一致的
簇总体有效性度量公式如下
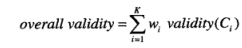
其中validity函数可以是凝聚度或分离度,也可以是两种的组合
轮廓系数5
轮廓系数是综合了凝聚度和分离度的综合指标,该指标不仅能用于度量簇的有效性,还能度量每个样本在聚类结果中的有效性
基于近邻度矩阵
理想的聚类效果同一个簇中的,样本间的相似度为1,而不同簇间的相似度为0。根据这个原则和聚类结果构建一个理想相似度矩阵,该矩阵中通一个簇的一对点相似度为1。然后计算理想和实际相似度矩阵之间的相关系数(注意值计算矩阵的下三角部分)
2 层次聚类评估6
层次聚类簇评估通过共性分类矩阵进行评估,思想和划分聚类基于近邻度的评估方法有点相似,都是计算两个矩阵的下三角的部分的相关系数。
共性分类距离矩阵的计算公式参考《数据挖掘导论,P338》
有监督评估方法
有监督的评估又称外在方法,和有监督的训练方法的评估是十分相似的















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









