








Aggregated Residual Transformations for Deep Neural Networks, arXiv 16.11.
论文链接: https://arxiv.org/abs/1611.05431
blog参考:
http://www.dongzhuoyao.com/aggregated-residual-transformations-for-deep-neural-networks/
mxnet的复现:http://data.dmlc.ml/models/imagenet/resnext/101-layers/
caffe的复现:https://github.com/terrychenism/ResNeXt
=====
这个是全明星阵容的paper,提出了深度模型另一个重要的需要考量的纬度:cardinality。(用简单的方式做不简单的事情)
众所周知,提高模型的performance,最直接的就是从模型的depth和width入手,即加深网络的深度,让网络变得更胖点(宽度,即layer的filter的数目)
但是这会有问题:1)网络越深,越难训练;2)网络越宽,模型复杂度越高,计算量越大,需要显存越多。
那有没有办法,在保持模型现有的复杂度的情况下,提高模型的学习能力?
该论文从这个角度出发,提出了考量模型的另一个纬度:cardinality(即模型split-transform-merge的集合的数目,笔者理解就是一个block里面,branches或者paths的个数)
先看图:

fig1的左图就是今年火爆的resnet的一个block的经典形式,而右图是该论文提出的ResNeXt (suggesting the next dimension) 的一个block。
很显然resnet的cardinality为2(ResNets [13] can be thought of as two-branch networks where one branch is the identity mapping.),而ResNeXt的cardinality设为C(这里不包括identity mapping)。
从图中看,ResNeXt还是很容易看懂的,前提是,ResNeXt做了两个假设:
i) if producing spatial maps of the same size, the blocks share the same hyper-parameters (width and filter sizes),
ii) each time when the spatial map is downsampled by a factor of 2, the width of the blocks is multiplied by a factor of 2. The second rule ensures that the computational complexity, in terms of FLOPs (floating-point operations, in #of multiply-adds), is roughly the same for all blocks.
基于这两个假设(rules),we only need to design a template module, and all modules in a network can be determined accordingly. So these two rules greatly narrow down the design space and allow us to focus on a few key factors. The networks constructed by these rules are in Table 1.
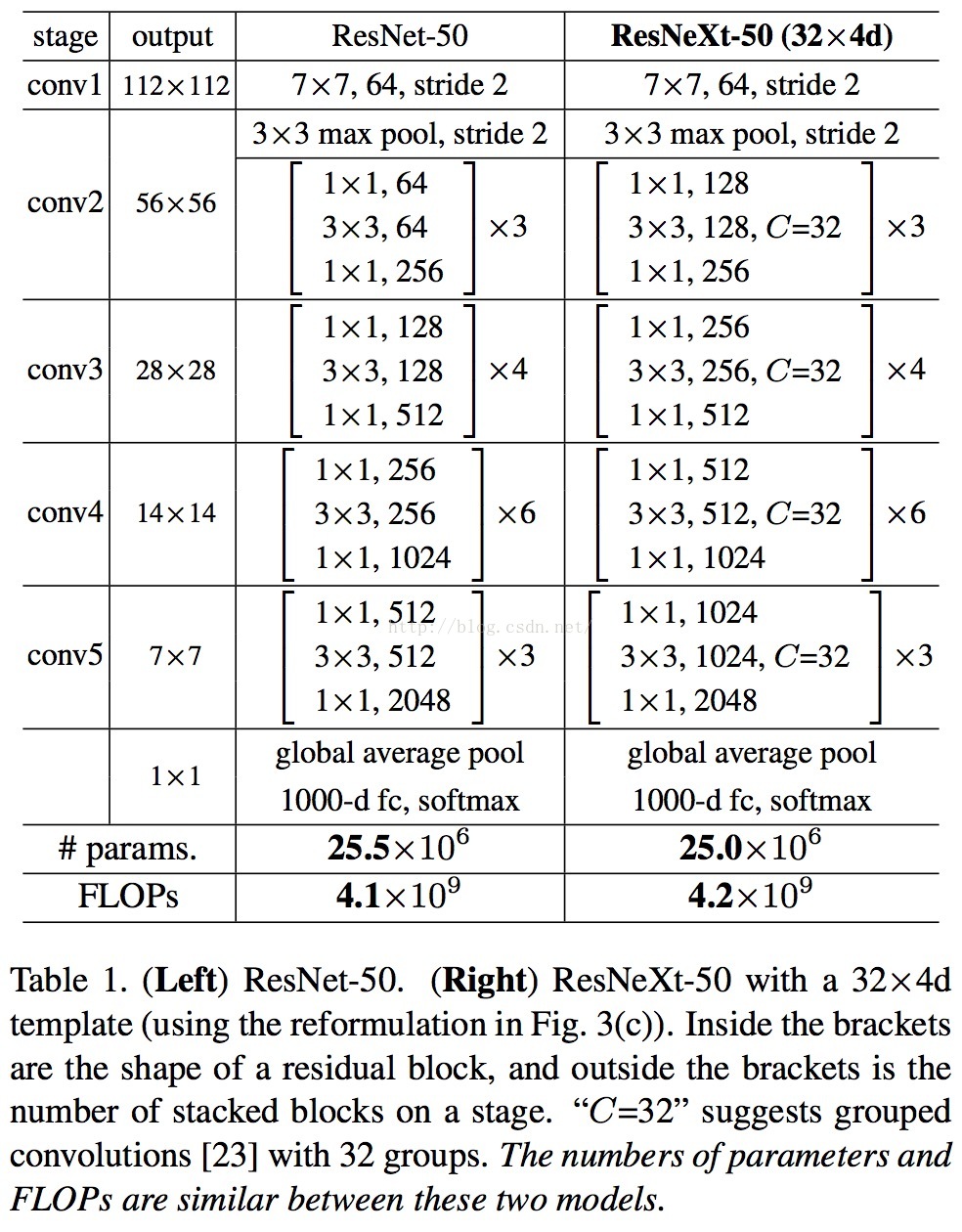
但是有一个问题,如果粗暴地按fig1的右图来设计模型(prototxt文件)时,会很繁琐,而且没有经过优化,使得模型的训练时间变长,
那么怎么优化呢?
骚年还记得12年的Alexnet么,里面的group convolution恰恰可以做这个优化问题,见下图:
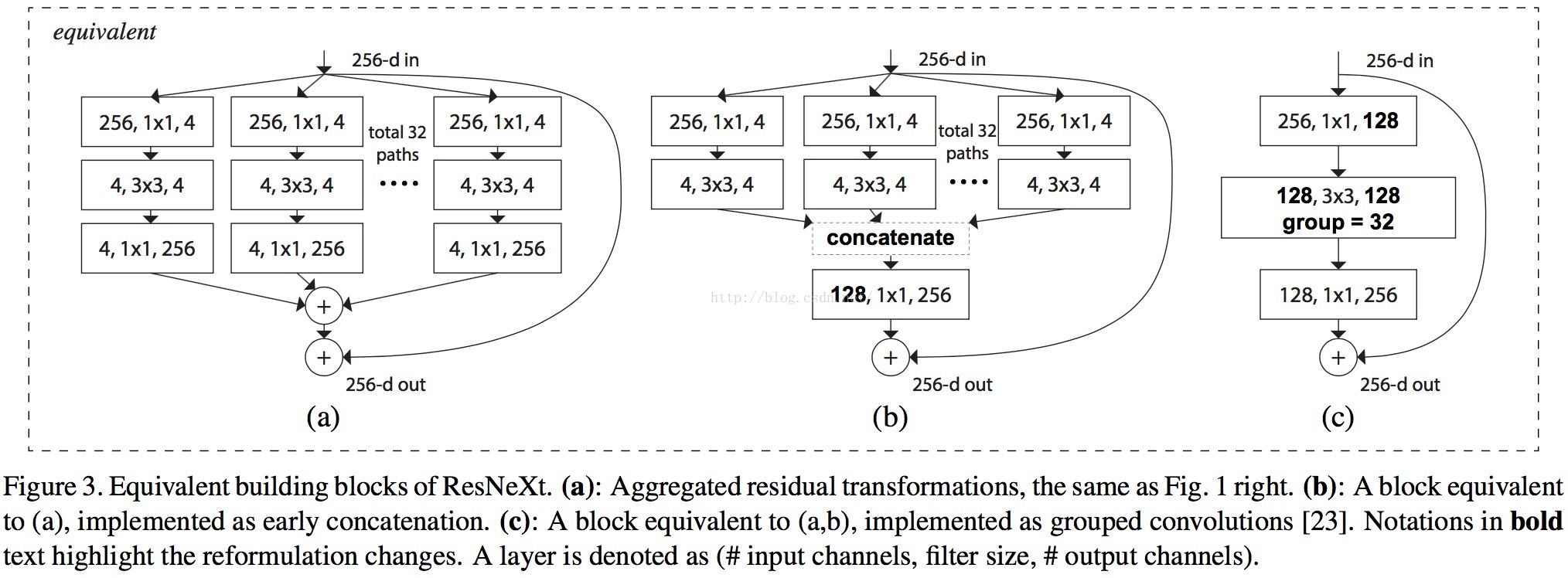
fig3也很容易看懂,关键在于理解group convolution而已。见下面的解释:
In a group conv layer [23], input and output channels are divided intoC groups, and convolutions are separately performed within each group.
是不是顿时觉得在two rules的前提下,ResNeXt非常简单,既没有加深模型的深度,又保持模型相同(差不多)的复杂度。
理解了fig3,就可以理解整个ResNeXt了。
那么它的效果如何?
哈至于ResNeXt的perfomance以及和Resnet做对比的实验等等,笔者在这里就展开详细说了,建议各位看论文去哈,
(论文非常值得深读,比如ResNeXt的cardinality是怎么来的,通用的ResNeXt是怎样的(也就是去掉上面的two rules),和以往的模型有哪些异同,group-convolutioin的好处在哪里,如何在coco上做detection,split-transform-merge的本质是什么? 等等)
最后附上一个论文的截图,关于怎么设caridinality的参数C

=====
如果这篇博文对你有帮助,可否赏笔者喝杯奶茶?
















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









