









 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
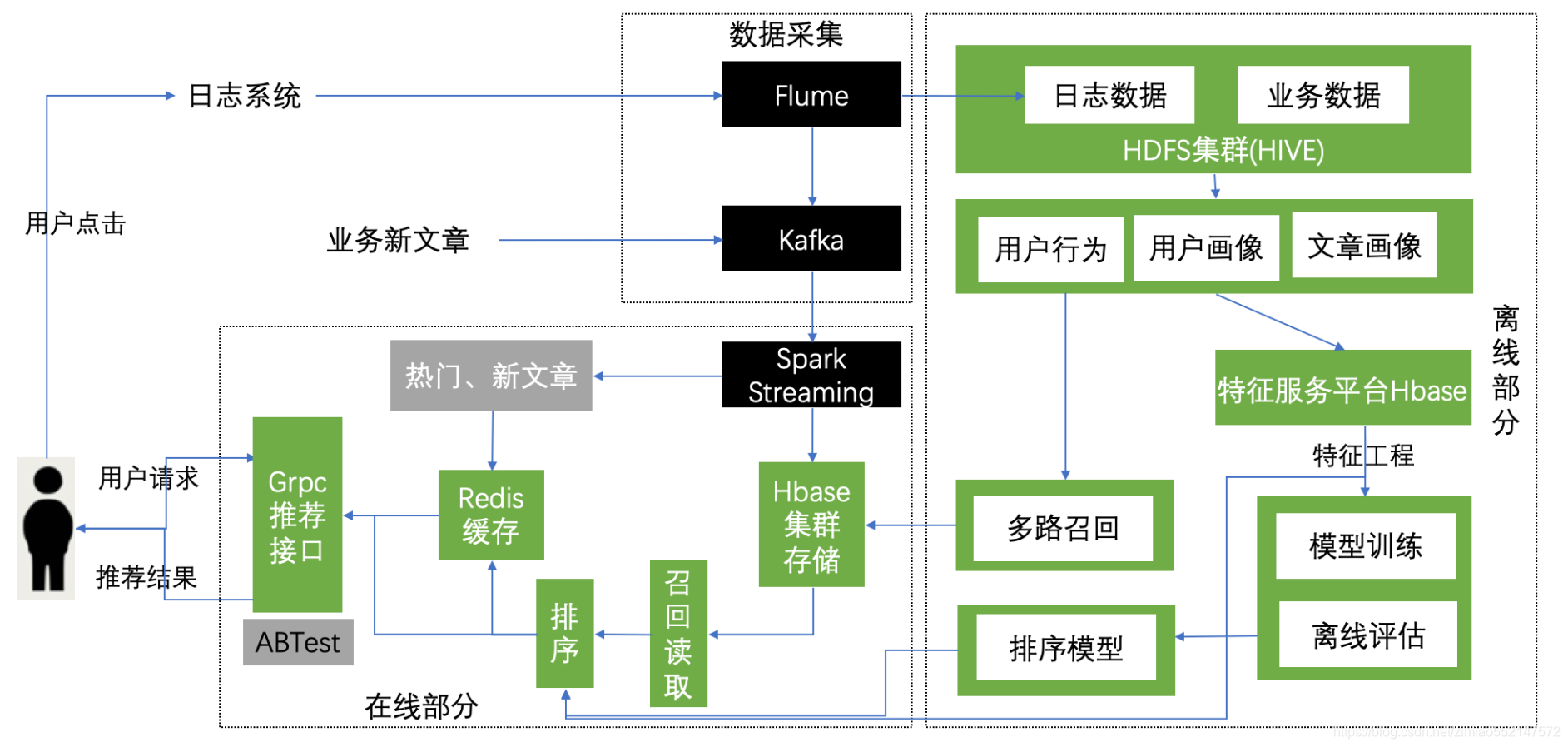
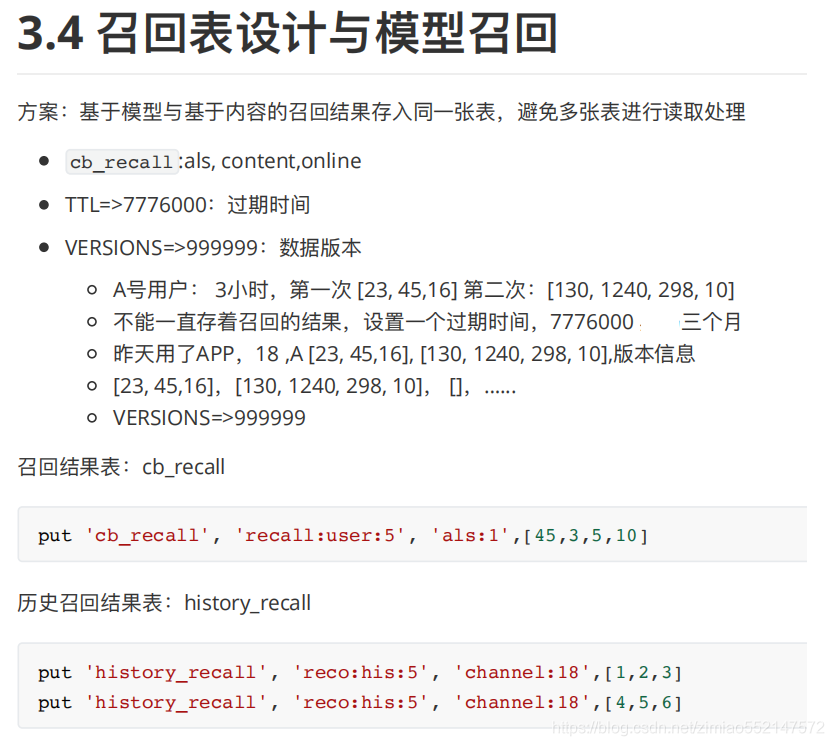
3.4 召回表设计与模型召回
学习目标
- 目标
- 知道ALS模型推荐API使用
- 知道StringIndexer的使用
- 应用
- 应用spark完成离线用户基于模型的协同过滤推荐
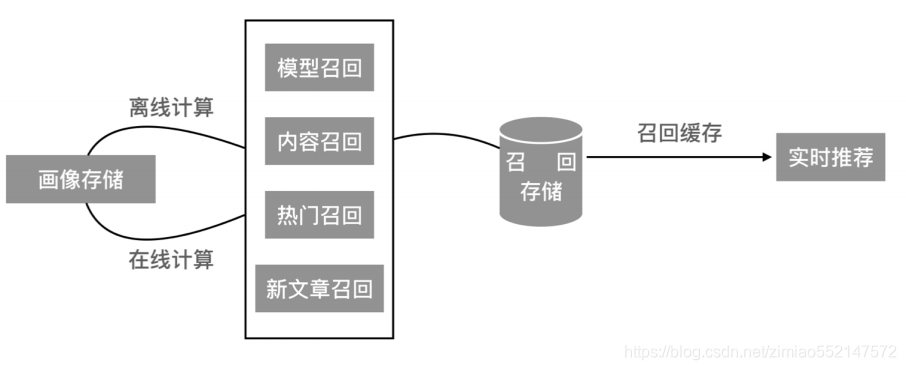
3.4.1 召回表设计
我们的召回方式有很多种,多路召回结果存储模型召回与内容召回的结果需要进行相应频道推荐合并。
- 方案:基于模型与基于内容的召回结果存入同一张表,避免多张表进行读取处理
- 由于HBASE有多个版本数据功能存在的支持
- TTL=>7776000, VERSIONS=>999999
create 'cb_recall', {NAME=>'als', TTL=>7776000, VERSIONS=>999999}
alter 'cb_recall', {NAME=>'content', TTL=>7776000, VERSIONS=>999999}
alter 'cb_recall', {NAME=>'online', TTL=>7776000, VERSIONS=>999999}
# 例子:
put 'cb_recall', 'recall:user:5', 'als:1',[45,3,5,10]
put 'cb_recall', 'recall:user:5', 'als:1',[289,11,65,52,109,8]
put 'cb_recall', 'recall:user:5', 'als:2',[1,2,3,4,5,6,7,8,9,10]
put 'cb_recall', 'recall:user:2', 'content:1',[45,3,5,10,289,11,65,52,109,8]
put 'cb_recall', 'recall:user:2', 'content:2',[1,2,3,4,5,6,7,8,9,10]
hbase(main):084:0> desc 'cb_recall'
Table cb_recall is ENABLED
cb_recall
COLUMN FAMILIES DESCRIPTION
{NAME => 'als', VERSIONS => '999999', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false'
, KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL =>
'7776000 SECONDS (90 DAYS)', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE
_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_
OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'content', VERSIONS => '999999', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'fa
lse', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL
=> '7776000 SECONDS (90 DAYS)', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', C
ACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS
_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'online', VERSIONS => '999999', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'fal
se', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL
=> '7776000 SECONDS (90 DAYS)', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CA
CHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_
ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
3 row(s)
在HIVE用户数据数据库下建立HIVE外部表,若hbase表有修改,则进行HIVE 表删除更新
create external table cb_recall_hbase(
user_id STRING comment "userID",
als map<string, ARRAY<BIGINT>> comment "als recall",
content map<string, ARRAY<BIGINT>> comment "content recall",
online map<string, ARRAY<BIGINT>> comment "online recall")
COMMENT "user recall table"
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,als:,content:,online:")
TBLPROPERTIES ("hbase.table.name" = "cb_recall");
增加一个历史召回结果表
create 'history_recall', {NAME=>'channel', TTL=>7776000, VERSIONS=>999999}
put 'history_recall', 'recall:user:5', 'als:1',[1,2,3]
put 'history_recall', 'recall:user:5', 'als:1',[4,5,6,7]
put 'history_recall', 'recall:user:5', 'als:1',[8,9,10]
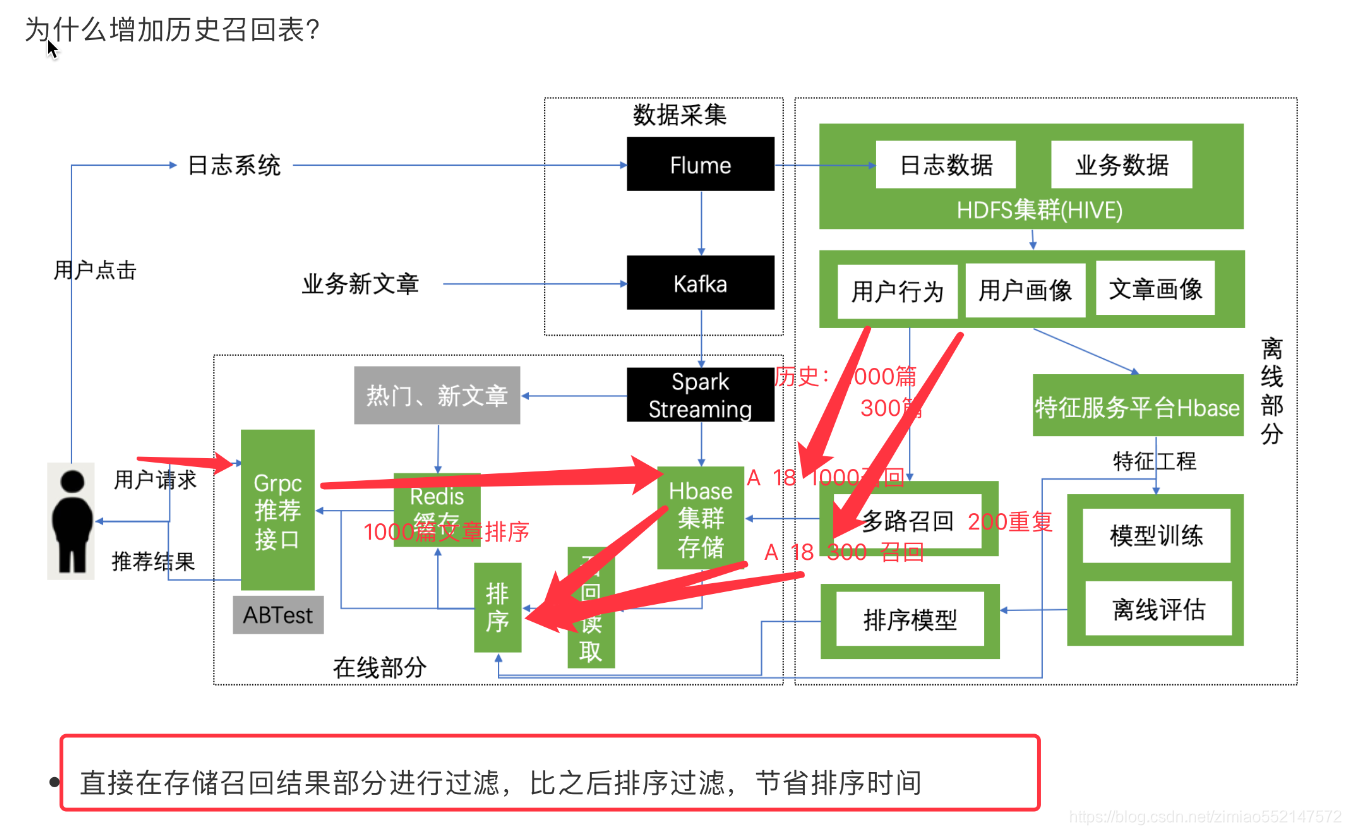
为什么增加历史召回表?
- 直接在存储召回结果部分进行过滤,比之后排序过滤,节省排序时间
3.4.2 基于模型召回集合计算
初始化信息
import os
import sys
# 如果当前代码文件运行测试需要加入修改路径,避免出现后导包问题
BASE_DIR = os.path.dirname(os.path.dirname(os.getcwd()))
sys.path.insert(0, os.path.join(BASE_DIR))
PYSPARK_PYTHON = "/miniconda2/envs/reco_sys/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
from offline import SparkSessionBase
class UpdateRecall(SparkSessionBase):
SPARK_APP_NAME = "updateRecall"
ENABLE_HIVE_SUPPORT = True
def __init__(self):
self.spark = self._create_spark_session()
ur = UpdateRecall()
3.4.2.1 ALS模型推荐实现
- 目标:利用ALS模型召回,推荐文章给用户
ALS模型复习:
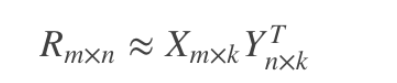
- 步骤:
- 1、数据类型转换,clicked以及用户ID与文章ID处理
- 2、ALS模型训练以及推荐
- 3、推荐结果解析处理
- 4、推荐结果存储
数据类型转换,clicked
ur.spark.sql("use profile")
user_article_click = ur.spark.sql("select * from user_article_basic").\
select(['user_id', 'article_id', 'clicked'])
# 更换类型
def change_types(row):
return row.user_id, row.article_id, int(row.clicked)
user_article_click = user_article_click.rdd.map(change_types).toDF(['user_id', 'article_id', 'clicked'])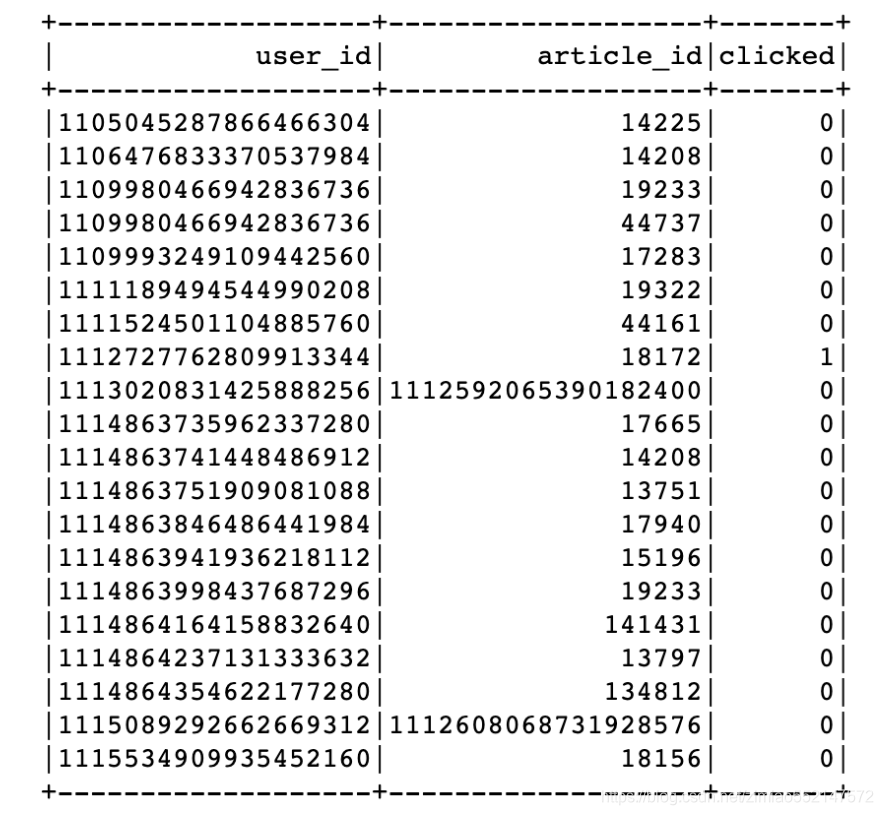
用户ID与文章ID处理,编程ID索引
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
# 用户和文章ID超过ALS最大整数值,需要使用StringIndexer进行转换
user_id_indexer = StringIndexer(inputCol='user_id', outputCol='als_user_id')
article_id_indexer = StringIndexer(inputCol='article_id', outputCol='als_article_id')
pip = Pipeline(stages=[user_id_indexer, article_id_indexer])
pip_fit = pip.fit(user_article_click)
als_user_article_click = pip_fit.transform(user_article_click)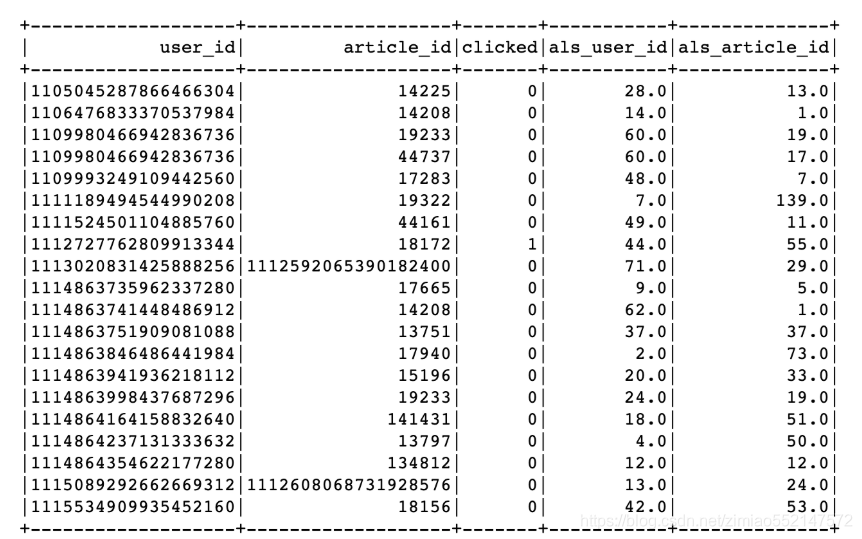
3.4.2.2 ALS 模型训练与推荐
ALS模型需要输出用户ID列,文章ID列以及点击列
from pyspark.ml.recommendation import ALS
# 模型训练和推荐默认每个用户固定文章个数
als = ALS(userCol='als_user_id', itemCol='als_article_id', ratingCol='clicked', checkpointInterval=1)
model = als.fit(als_user_article_click)
recall_res = model.recommendForAllUsers(100)
3.4.2.3 推荐结果处理
通过StringIndexer变换后的下标知道原来的和用户ID
# recall_res得到需要使用StringIndexer变换后的下标
# 保存原来的下表映射关系
refection_user = als_user_article_click.groupBy(['user_id']).max('als_user_id').withColumnRenamed(
'max(als_user_id)', 'als_user_id')
refection_article = als_user_article_click.groupBy(['article_id']).max('als_article_id').withColumnRenamed(
'max(als_article_id)', 'als_article_id')
# Join推荐结果与 refection_user映射关系表
# +-----------+--------------------+-------------------+
# | als_user_id | recommendations | user_id |
# +-----------+--------------------+-------------------+
# | 8 | [[163, 0.91328144]... | 2 |
# | 0 | [[145, 0.653115], ... | 1106476833370537984 |
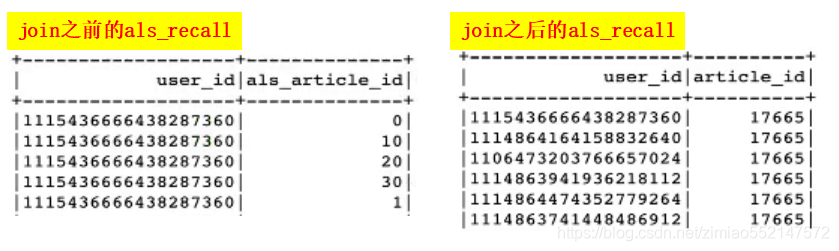
recall_res = recall_res.join(refection_user, on=['als_user_id'], how='left').select(
['als_user_id', 'recommendations', 'user_id'])
对推荐文章ID后处理:得到推荐列表,获取推荐列表中的ID索引
# Join推荐结果与 refection_article映射关系表
# +-----------+-------+----------------+
# | als_user_id | user_id | als_article_id |
# +-----------+-------+----------------+
# | 8 | 2 | [163, 0.91328144] |
# | 8 | 2 | [132, 0.91328144] |
import pyspark.sql.functions as F
recall_res = recall_res.withColumn('als_article_id', F.explode('recommendations')).drop('recommendations')
# +-----------+-------+--------------+
# | als_user_id | user_id | als_article_id |
# +-----------+-------+--------------+
# | 8 | 2 | 163 |
# | 8 | 2 | 132 |
def _article_id(row):
return row.als_user_id, row.user_id, row.als_article_id[0]
进行索引对应文章ID获取
als_recall = recall_res.rdd.map(_article_id).toDF(['als_user_id', 'user_id', 'als_article_id'])
als_recall = als_recall.join(refection_article, on=['als_article_id'], how='left').select(
['user_id', 'article_id'])
# 得到每个用户ID 对应推荐文章
# +-------------------+----------+
# | user_id | article_id |
# +-------------------+----------+
# | 1106476833370537984 | 44075 |
# | 1 | 44075 |
获取每个文章对应的频道,推荐给用户时按照频道存储
ur.spark.sql("use toutiao")
news_article_basic = ur.spark.sql("select article_id, channel_id from news_article_basic")
als_recall = als_recall.join(news_article_basic, on=['article_id'], how='left')
als_recall = als_recall.groupBy(['user_id', 'channel_id']).agg(F.collect_list('article_id')).withColumnRenamed(
'collect_list(article_id)', 'article_list')
als_recall = als_recall.dropna()
3.4.2.4 召回结果存储
- 存储位置,选择HBASE
HBASE表设计:
put 'cb_recall', 'recall:user:5', 'als:1',[45,3,5,10,289,11,65,52,109,8]
put 'cb_recall', 'recall:user:5', 'als:2',[1,2,3,4,5,6,7,8,9,10]
存储代码如下:
def save_offline_recall_hbase(partition):
"""离线模型召回结果存储
"""
import happybase
pool = happybase.ConnectionPool(size=10, host='hadoop-master', port=9090)
for row in partition:
with pool.connection() as conn:
# 获取历史看过的该频道文章
history_table = conn.table('history_recall')
# 多个版本
data = history_table.cells('reco:his:{}'.format(row.user_id).encode(),
'channel:{}'.format(row.channel_id).encode())
history = []
if len(_history_data) > 1:
for l in _history_data:
history.extend(l)
# 过滤reco_article与history
reco_res = list(set(row.article_list) - set(history))
if reco_res:
table = conn.table('cb_recall')
# 默认放在推荐频道
table.put('recall:user:{}'.format(row.user_id).encode(),
{'als:{}'.format(row.channel_id).encode(): str(reco_res).encode()})
# 放入历史推荐过文章
history_table.put("reco:his:{}".format(row.user_id).encode(),
{'channel:{}'.format(row.channel_id): str(reco_res).encode()})
conn.close()
als_recall.foreachPartition(save_offline_recall_hbase)


召回表设计
1.hbase的召回结果cb_recall表:列簇有'als'、'content'、'online'
1.create 'cb_recall', {NAME=>'als', TTL=>7776000, VERSIONS=>999999} 存储模型召回的结果
2.alter 'cb_recall', {NAME=>'content', TTL=>7776000, VERSIONS=>999999} 存储内容召回的结果
3.alter 'cb_recall', {NAME=>'online', TTL=>7776000, VERSIONS=>999999} 存储在线计算的结果
4.热门召回和新文章召回可以存储到redis
5.TTL=>7776000:
设置数据的过期时间,过期之后会自动删除。可以是每隔几小时就更新一次存储的召回结果。
设置过期时间的作用,就是如果用户长期不登录就不需要再存储该召回结果了。7776000代表3个月的过期时间。
6.VERSIONS=>999999:表示多个版本数据功能,代表999999次的版本数据。
作用是:假如给某用户(user)在某个频道(channel_id)推荐了多次召回结果,但是该用户一次都还没去获取的话,那么就需要保存着多次更新的召回结果了。
因为hbase默认是一个key就对应一个value,那么就需要设置VERSIONS=>999999来增加版本信息,那么就可以用于当用户没有那么积极地获取的时候,
hbase就可以在同一个key同一个列簇的情况下,存储多个版本的value(也即保存多次的召回结果)。
因为离线召回部分是定时每隔几小时就更新一次召回结果,那么用户并不是每次都立即获取推荐结果的,因此就涉及到异步存储多次召回结果,
那么也就要设置过期时间。
比如:同一个key(user:5)用户ID为5的用户,同一个列簇(als:1)频道ID为1 会有多个召回结果
put 'cb_recall', 'recall:user:5', 'als:1',[45,3,5,10]
put 'cb_recall', 'recall:user:5', 'als:1',[289,11,65,52,109,8]
2.hbase的历史召回结果history_recall表:
1.历史召回意思就是给这个用户推的召回结果有哪些历史数据。
2.比如多路召回的时候给A用户在18频道推荐了1000个召回数据存储到hbase集群中,那么用户在请求的时候,可以先去redis获取,如获取不到可再去hbase获取1000个召回数据,
那么此时就需要对1000个召回数据进行排序精选出TOP-N再进行推荐给用户。
3.而离线部分的多路召回会每隔一段时间定时就会推出若干个召回数据,此时自动再给A用户在18频道又推荐了500个召回数据,
假如之前一次推送的1000个召回数据和这一次推送的500个召回数据其中有200个是重复相同的召回数据,那么为防止用户在第一次请求获取1000个召回数据进行排序,
第二次请求获取500个召回数据又进行排序,其中多次排序的过程中可能对大量的重复数据进行排序,为避免这种性能浪费可进行优化,
那么优化的方法就是设置历史召回结果history_recall表。那么就可以把第一次历史推荐的1000个召回数据存储到历史召回表中,
那么在离线部分中多路召回下一次定时自动推送500个召回数据的时候,就可以把其中的200个重复数据过滤掉不进行推送,仅推送300个不重复的召回数据到hbase中。
这样下一次用户在请求获取300个召回数据的时候进行排序,就不是对包含200个重复数据的500个召回结果进行排序了,这样就可以优化性能了。
所以每次先对离线部分中多路召回推送的召回数据先进行过滤,再存储到hbase,这样就可以优化排序时候的实时性能。
4.因此创建历史召回结果history_recall表也需要设置TTL(过期时间)和VERSIONS(多个版本信息)。
create 'history_recall', {NAME=>'channel', TTL=>7776000, VERSIONS=>999999}
put 'history_recall', 'reco:his:5', 'channel:1',[1,2,3]
put 'history_recall', 'reco:his:5', 'channel:1',[4,5,6,7]
设置列簇'channel',TTL=>7776000(3个月的过期时间),VERSIONS=>999999(999999次的版本数据)
历史召回history_recall表负责过滤多路召回的结果,并且历史召回表每次也会存储多路召回的数据。
基于模型召回集合计算:ALS模型召回实现

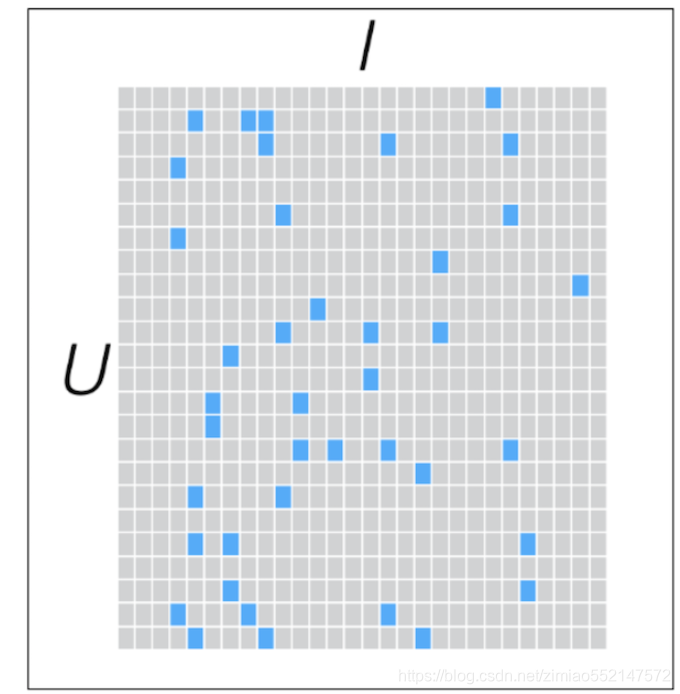
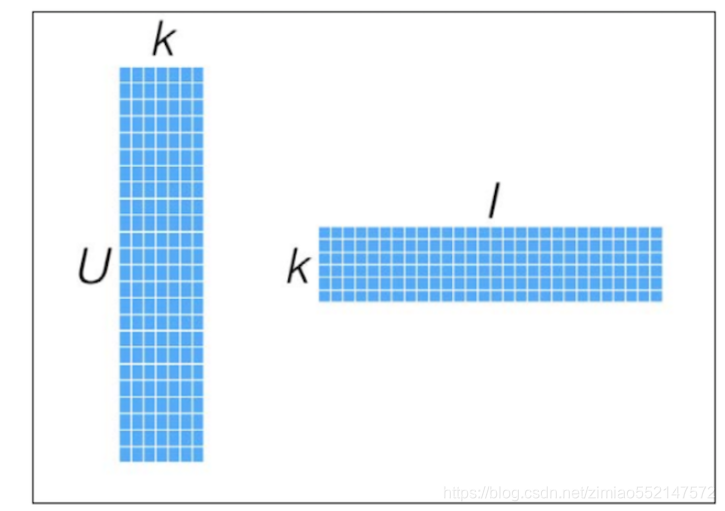
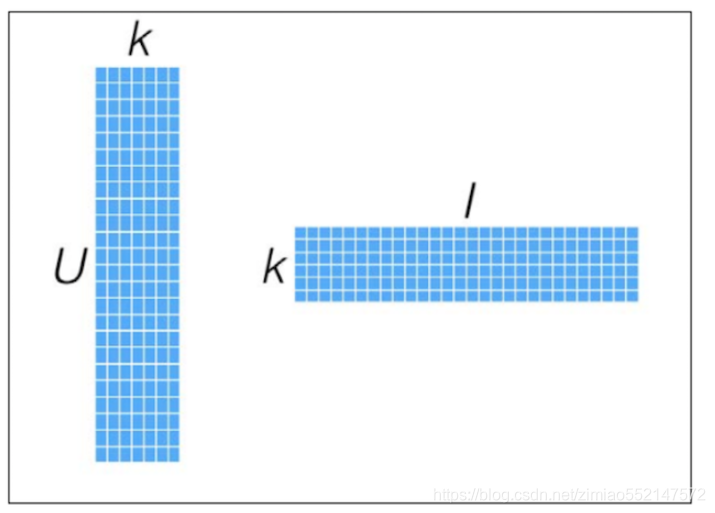
把“用户user-物品item-用户对物品的评分”这个[U,I]矩阵分解成下图中的2个随机参数矩阵X([U,K])和Y([K,I])。
“用户user-物品item-用户对物品的评分”这个[U,I]矩阵为真实评分矩阵。
随机参数矩阵X([U,K])和Y([K,I]),X*Y即[U,K]*[K,I]等于[U,I]为预测评分矩阵。
真实矩阵[U,I]和预测矩阵[U,I]两者并不完全相同,那么就可以根据两个矩阵中对应位置上的每个评分值进行计算损失。
然后还可以根据梯度下降优化算法优化两个随机参数矩阵X([U,K])和Y([K,I])中的值,可以理解为权重值。
那么优化好的矩阵X([U,K])和Y([K,I])进行相乘就可以得出预测评分矩阵,其中的值就可以作为预测评分。
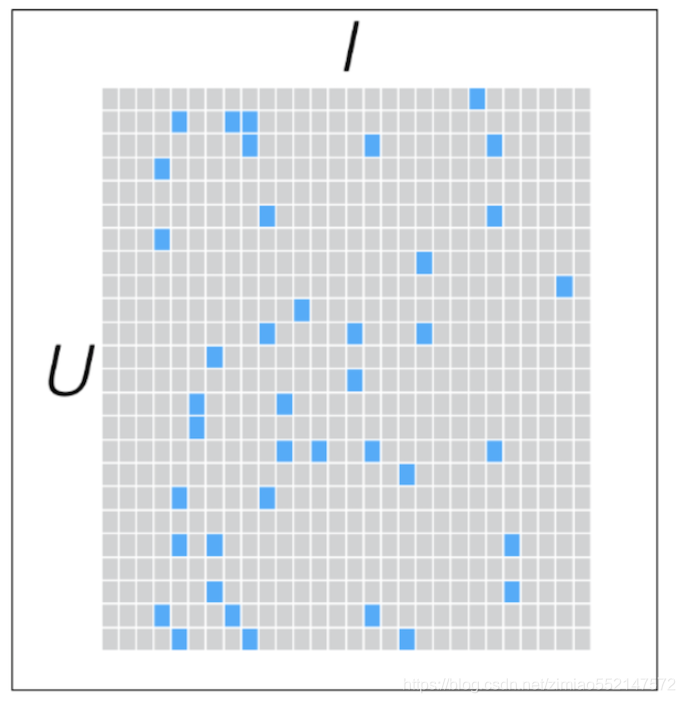
下面为优化好的矩阵X([U,K])和Y([K,I])进行相乘所得出来的预测评分[U,I]矩阵,即“用户user-物品item-用户对物品的预测评分”矩阵。
行为用户user,列为物品item,那么下图中蓝色正方形为用户对物品的真实评分,灰色正方形为用户对物品的预测评分。
比如预测评分矩阵中第一行为用户1对所有物品的预测评分(灰色正方形)和用户对物品的真实评分(蓝色正方形)两者组成,
那么可以对第一行中的用户1对所有物品的预测评分进行排序得出最高的预测评分然后对用户进行推荐。
“用户user-物品item-用户对物品的评分”矩阵的数据来源:
用户对物品的行为日志数据,比如用户对物品的点赞/收藏/点击查看/投币/评论等行为日志数据。
然后根据打分规则对“用户对物品的”每个行为数据进行打分,得到用户对物品的总评分。
ur.spark.sql("use profile")
# 用户ID'user_id', 文章ID'article_id', 点击'clicked'
user_article_click = ur.spark.sql("select * from user_article_basic").select(['user_id', 'article_id', 'clicked'])
# 点击'clicked'字段的布尔值转换为int值
def change_types(row):
return row.user_id, row.article_id, int(row.clicked)
user_article_click = user_article_click.rdd.map(change_types).toDF(['user_id', 'article_id', 'clicked'])

#用户ID'user_id'和文章ID'article_id'要转换为索引值:通过Pipeline(stages=[字段1的StringIndexer, 字段2的StringIndexer])的方式进行索引值的转换
#有N个用户ID/文章ID的话,那么就要StringIndexer索引值化出0到N个的索引值。
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
user_id_indexer = StringIndexer(inputCol='user_id', outputCol='als_user_id')
article_id_indexer = StringIndexer(inputCol='article_id', outputCol='als_article_id')
#通过Pipeline(stages=[字段1的StringIndexer, 字段2的StringIndexer])的方式进行索引值的转换
pip = Pipeline(stages=[user_id_indexer, article_id_indexer])
pip_fit = pip.fit(user_article_click)
als_user_article_click = pip_fit.transform(user_article_click)

# ALS模型需要输出用户列'user_id', 文章列'article_id', 点击列'clicked'
from pyspark.ml.recommendation import ALS
# 模型训练和推荐默认每个用户固定文章个数
# 利用点击数据训练ALS模型。告诉ALS模型用户数据为'userId'列,物品数据为'cateId'列,评分数据为'clicked'点击列。
# checkpointInterval=1:模型训练的时候每迭代1次缓存一次到本地检查点,设置的数值越大模型训练的耗时越短。
# 如果'userId'和'article_id'的原列值的位数都不长的话,也可以直接传入ALS模型训练,
# 但是如果userCol和itemCol的输入字段列值的位数非常长的话,那么便需要把原列值先进行StringIndexer方式转换为索引值再输入进行训练。
als = ALS(userCol='als_user_id', itemCol='als_article_id', ratingCol='clicked', checkpointInterval=1)
model = als.fit(als_user_article_click)
# model.recommendForAllUsers(N) 给所有用户推荐TOP-N个物品
recall_res = model.recommendForAllUsers(100)
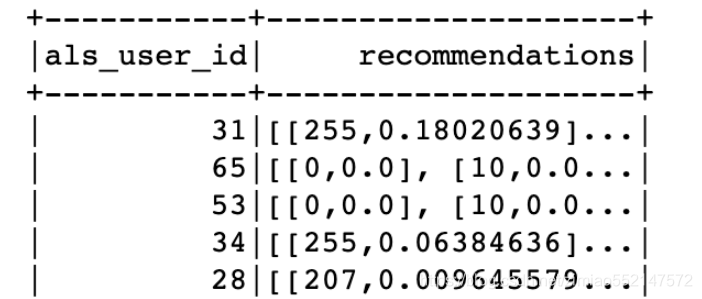
#recall_res预测结果数据:
# 第1列als_user_id:用户ID(user_id)的索引值化
# 第2列recommendations:为二维列表,其中里面每个一维列表里面有两个值,第一个值是als_article_id列值,第二个值是clicked预测值。
# 因为评分值ratingCol='clicked'本身值就是0/1,因此clicked预测值也就便为0到1之间的值

# 需要把索引值化的als_user_id列值对应回user_id原列值。使用max或min都可以。
# 因为使用了max('als_user_id')的关系,内在的'als_user_id'查询出来的列名会变成max('als_user_id'),
# 因此要使用withColumnRenamed('max(als_user_id)', 'als_user_id')重新把max('als_user_id')转换为 'als_user_id'。
# refection_user:包含了'user_id'、'als_user_id'
refection_user = als_user_article_click.groupBy(['user_id']).max('als_user_id').withColumnRenamed('max(als_user_id)', 'als_user_id')
# 需要把索引值化的als_article_id列值对应回article_id原列值。使用max或min都可以。
# 因为使用了max('als_article_id')的关系,内在的'als_article_id'查询出来的列名会变成max('als_article_id'),
# 因此要使用withColumnRenamed('max(als_article_id)', 'als_article_id')重新把max('als_article_id')转换为 'als_article_id'。
# refection_article:包含了'article_id'、'als_article_id'
refection_article = als_user_article_click.groupBy(['article_id']).max('als_article_id').withColumnRenamed('max(als_article_id)', 'als_article_id')
# on=['als_user_id']:recall_res和refection_user之间以'als_user_id'作为连接条件,how='left'表示左连接
recall_res = recall_res.join(refection_user, on=['als_user_id'], how='left').select(['als_user_id', 'recommendations', 'user_id'])

# 对推荐文章ID后处理:得到推荐列表,获取推荐列表中的ID索引
import pyspark.sql.functions as F
# F.explode('recommendations'):把'recommendations'中二维列表中的第1个一维列表数据导出到'als_article_id'字段数据。
# drop('recommendations'):然后把原'recommendations'字段列数据丢弃
recall_res = recall_res.withColumn('als_article_id', F.explode('recommendations')).drop('recommendations')
def _article_id(row):
# row.als_article_id[0]:推荐数据一维列表包含'article_id'文章ID和预测值,从中取出'article_id'文章ID
return row.als_user_id, row.user_id, row.als_article_id[0]
# 'als_article_id'字段数据中推荐数据一维列表包含'article_id'文章ID和预测值
als_recall = recall_res.rdd.map(_article_id).toDF(['als_user_id', 'user_id', 'als_article_id'])
# refection_article:包含了'article_id'、'als_article_id'
# on=['als_article_id']:als_recall和refection_article之间以'als_article_id'作为连接条件。how='left'表示左连接
# als_recall包含了用户ID'user_id'和给该用户推荐的文章ID'article_id'
als_recall = als_recall.join(refection_article, on=['als_article_id'], how='left').select(['user_id', 'article_id'])
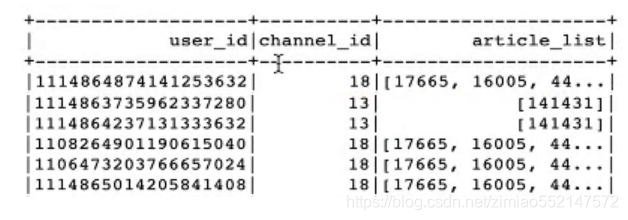
#获取每个'article_id'文章ID对应的频道,推荐给用户时按照频道进行推荐。设置了有18个频道,按每个不同的频道进行推荐不同的文章。
# put 'cb_recall', 'recall:user:5', 'channel:1',[45,3,5,10]:比如按照'user:5'用户对应的'channel:1'频道进行推荐[45,3,5,10]
ur.spark.sql("use toutiao")
#查询'article_id'文章ID 和 对应的channel_id频道ID
news_article_basic = ur.spark.sql("select article_id, channel_id from news_article_basic")
# on=['article_id']表示als_recall和news_article_basic之间以'article_id'作为连接条件。 how='left'表示左连接。
# als_recall包含了用户ID'user_id'、给该用户推荐的文章ID'article_id'、channel_id频道ID
# 查询出来的als_recall中的user_id用户ID对应的channel_id频道ID可能会有若干个的'article_id'文章ID
als_recall = als_recall.join(news_article_basic, on=['article_id'], how='left')

# 因为查询出来的als_recall中的user_id用户ID对应的channel_id频道ID可能会有若干个的'article_id'文章ID,因此可以对'user_id'和'channel_id'一起分组,
# 每个用户对应的每个频道都获取出一个列表包含的多个article_id文章ID
# agg(F.collect_list('article_id')):聚合函数把对应某个用户下的每个频道对应的多个article_id文章ID都封装到一个列表中
# 因为使用了聚合函数所以列名变成了collect_list('article_id'),因此要通过withColumnRenamed('collect_list(article_id)', 'article_list')
# 把'collect_list(article_id)'的列名 变回到'article_list'的列名
als_recall = als_recall.groupBy(['user_id', 'channel_id']).agg(F.collect_list('article_id')).withColumnRenamed('collect_list(article_id)', 'article_list')
# 去掉有空值所在的整行数据
als_recall = als_recall.dropna()
召回结果存储,存储位置选择HBASE
HBASE表设计:
put 'cb_recall', 'recall:user:5', 'als:1',[45,3,5,10,289,11,65,52,109,8]
put 'cb_recall', 'recall:user:5', 'als:2',[1,2,3,4,5,6,7,8,9,10]
存储代码如下:
# ALS的推荐结果存储到hbase中,遍历每个分区,每个分区中是若干行的数据
def save_offline_recall_hbase(partition):
#离线模型召回结果存储
import happybase
pool = happybase.ConnectionPool(size=10, host='hadoop-master', port=9090)
for row in partition:
with pool.connection() as conn:
# 获取用户的某频道下的历史推荐频道文章
history_table = conn.table('history_recall')
# 从'history_recall'历史召回表中查看对应的用户下的某频道中历史的推荐结果,其中可能会包含多个版本的推荐结果信息
# cells可以获取这个key(user_id)对应的列簇(channel_id)下的多个版本的推荐结果信息,因为给该用户的某频道可能推荐了多次推荐数据
_history_data = history_table.cells('reco:his:{}'.format(row.user_id).encode(), 'channel:{}'.format(row.channel_id).encode())
history = []
# 如果该用户对应的频道下有多个版本的推荐结果信息的话,把多个版本的历史推荐结果都拿出来
if len(_history_data) > 1:
for l in _history_data:
history.extend(l)
# 当前频道推荐的结果article_list过滤掉历史推荐的结果history,即可以对当前频道推荐的结果article_list过滤掉历史重复推荐的信息
reco_res = list(set(row.article_list) - set(history))
# 如果过滤之后还有数据的话
if reco_res:
# 实时推荐的表
table = conn.table('cb_recall')
# 默认放在推荐频道
table.put('recall:user:{}'.format(row.user_id).encode(), {'als:{}'.format(row.channel_id).encode(): str(reco_res).encode()})
# 放入历史推荐过文章
history_table.put("reco:his:{}".format(row.user_id).encode(), {'channel:{}'.format(row.channel_id): str(reco_res).encode()})
conn.close()
# ALS的推荐结果存储到hbase中,遍历每个分区,每个分区中是若干行的数据
als_recall.foreachPartition(save_offline_recall_hbase)



















 2836
2836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











