






目录
特征点检测:Harris / SIFT / SURF / ORB
-
双目立体视觉
双目立体视觉基于视差原理并利用成像设备从不同的位置获取被测物体的左右两幅图像,然后根据三角测量原理计算空间点在二维图像的位置偏差,最后再利用位置偏差进行三维重建来获取被测物体的三维几何信息。
简短概述:相机标定-极线矫正-立体匹配- 三维恢复-后续可以进行下游任务视频分析(运动检测、运动跟踪、规则判断、报警处理)。
-
特征点检测:Harris / SIFT / SURF / ORB
-Harris角点:以该点为中心的窗口内的像素灰度在任意方向上都出现了较大的变化。
-SIFT尺度不变特征。sift算法:通过高斯微分函数来识别潜在的对尺度和选择不变的点。具体过程:构建尺度空间,检测极值点,获得尺度不变性—特征点过滤并进行精确定位,剔除不稳定的特征点—在特征点处提取特征描述符,为特征点分配方向值—生成特征描述子,利用特征描述符寻找匹配点—计算变换参数。
SIFT定位算法关键步骤的说明 - ☆Ronny丶 - 博客园 (cnblogs.com)
(52条消息) 图像特征匹配方法——SIFT算法原理及实现_Eating Lee的博客-CSDN博客_sift特征匹配算法Python-OpenCV实现:https://www.jianshu.com/p/65a56a2f63e3
import cv2 def sift_kp(image): gray_image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY) sift = cv2.xfeatures2d_SIFT.create()#实例化sift kp,des = sift.detectAndCompute(image, None)#利用sift.detectAndCompute()检测灰度图image关键点并计算 kp_image = cv2.drawKeypoints(image, kp, None)#将关键点检测结果绘制在图像上 return kp_image,kp,des image = cv2.imread('dog.jpg') kp_image, _, des = sift_kp(image) print(image.shape, des.shape) cv2.namedWindow('dog',cv2.WINDOW_NORMAL) cv2.imshow('dog', kp_image) if cv2.waitKey(0) == 27: cv2.destroyAllWindows()-SURF算法是SIFT算法的改进。SIFT特征与SURF特征的比较:
[构建图像金字塔] SIFT特征利用不同尺寸的图像与高斯差分滤波器卷积;SURF特征利用原图片与不同尺寸的方框滤波器做卷积,易于并行。
[特征描述子] 关键点邻域内划分为d*d子区域,每个子区域内计算8个方向的直方图,有4×4×8=128维描述子;SURF每个子区域计算采样点的haar小波响应,记录
,有4×4×4=64维描述子。
[特征点检测方法] SIFT特征先进行非极大抑制,再去除低对比度的点,再通过Hessian矩阵去除边缘响应过大的点;SURF特征先利用Hessian矩阵确定候选点,然后进行非极大抑制。
[特征点主方向] SIFT特征在正方形区域内统计梯度幅值的直方图,直方图最大值对应主方向,可以有多个主方向;SURF特征在圆形区域内计算各个扇形范围内x、y方向的haar小波响应,模最大的扇形方向作为主方向。
-
滤波器
Sobel算子是一种典型的用于边缘检测的线性滤波器,它基于两个简单的3*3内核
-
相机标定
四个坐标系:世界坐标系、相机坐标系、 图像坐标系、像素坐标系。
根据像素坐标系与世界坐标系的关系,建立相机成像的几何模型,求解其中的相机参数(内参、外参、畸变参数)的过程就称之为相机标定。
-标定过程:
- 通过调整标定物或摄像机的方向,为标定物拍摄一些不同方向的照片。
- 在图片中检测特征点(Harris角点)。
- 根据角点位置信息及图像中的坐标,求解 Homographic矩阵
- 估算理想无畸变的情况下,五个内参和六个外参。
- 应用最小二乘法估算实际存在径向畸变下的畸变系数。
- 极大似然法,优化估计,提升估计精度。
参考来自:
-
全景拼接
-原理:图像被投影到同一平面上,在拼接平面实现全景融合。
-主要过程:
- 提取AB两张图片的sift特征点,对两张图片的特征点进行匹配;
- 匹配后,仍有很多错误点, RANSAC的改进算法进行特征点对的筛选,筛选后的特征点基本能够一一对应;
- 使用DLT算法,将特征点对进行透视变换矩阵的估计。即以A图为基准,算B图到A图的全局变换H。
- 为提高配准的精度,Apap将B图切割成无数多个小方块,使用Moving DLT方法,逐个计算B图每个小网格与A图的局部变换H 。
- 将B图每个网格内的点按对应的H做局部变换,与A图融合。
缺点:非常依赖于特征点对。若图像高频信息较少,特征点对过少,配准将完全失效,并且对大尺度的图像进行配准,其效果也不是很好,一切都决定于特征点对的数量。
-
立体匹配入门:
视差:等于同名点对在左视图的列坐标减去在右视图上的列坐标,是像素单位。在极线校正后的像对里使用。
深度:等于像素在该视图相机坐标系下Z 坐标,是空间单位。任意图像都可获取深度图。
视差图:校正后图像对所有像素视差值的可视化。可视化的好处: 图像可以看作是有序的,因此邻域检索、视差滤波等将会变得非常方便
深度图:单视图所有像素的深度值的可视化,是空间单位,比如毫米。意义:是以更少的存储空间、有序的表达图像匹配的三维成果
点云:点云指三维空间的三维点集合,坐标属性(X , Y , Z ),法线属性(N x , N y , N z )(可选),颜色属性(R , G , B)(可选)。
分为两大域:传统的匹配算法、深度学习匹配算法。
- 传统匹配:SAD、BM、SGBM
- 深度学习匹配:一般基于特征点。
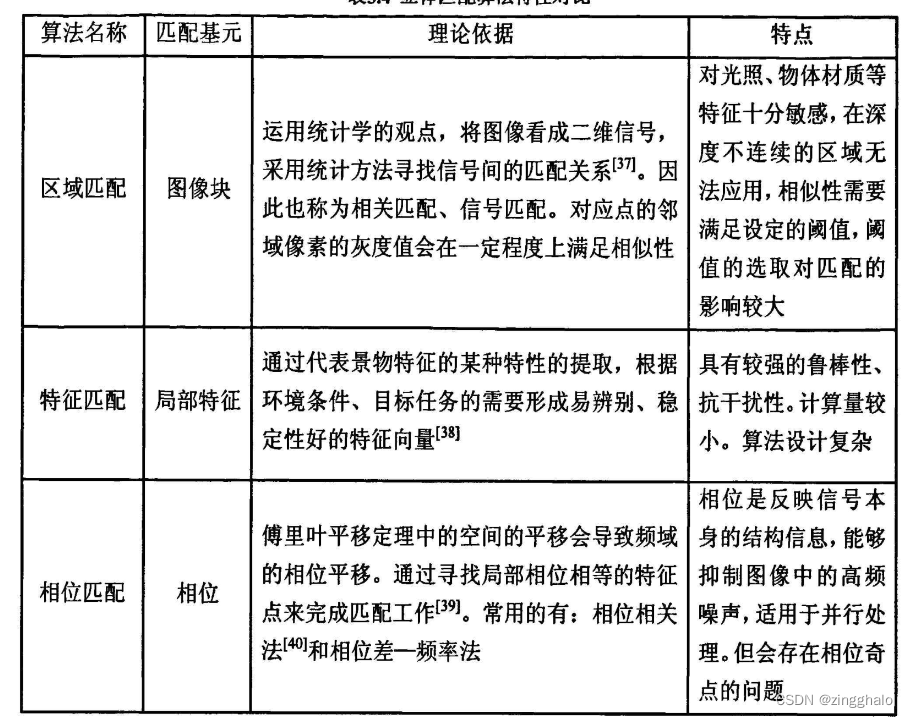
分为三大类:区域匹配、特征匹配、相位匹配。
视差图是立体匹配算法的产出,而深度图则是立体匹配到点云生成的中间桥梁。且两者可通过公式转换。 另外,深度图可以用来计算相机坐标系下的点云。
一般思路:以一个像素为中心去取一个固定大小的窗口(称为特征窗口),然后把比较两个像素的匹配程度转换为比较两个像素其特征窗口的图像块相似性,这样能更加准确地衡量两个像素在图像上表现出来的差异。
错误匹配:指像素在代价聚合后得到的视差值并不是真实的最小的视差值。这种错误匹配的现象在实际中并不少见,图像的噪声、遮挡、弱纹理和重复纹理都会导致这一 现象产生。因此,为了提高匹配的精度,必须要对错误的匹配进行剔除。视差不好的原因:代价聚合时匹配代价计算的不都准确,导致出现了错误的视差,而造成这种现象的原因往往是由影像噪声、遮挡、弱纹理或重复纹理等产生的。
难点:当空间三维场景经过透视投影(Perspective Projection)变换为二维图像时,同一景物在不同视点的摄像机图像平面上的成像会发生不同程度的扭曲和变形,而且场景中的光照条件、被测对象的几何形状和表面特性、噪声干扰和畸变、摄像机特性等诸多因素的影响都被集中体现在单一的图像灰度值中。
有效性依赖于:选择正确的匹配特征、寻找特征间的本质属性、建立能正确匹配所选择特征的稳定算法。
发展方向:建立更有效的双目体视模型能更充分地反映立体视觉不确定性的本质属性,为匹配提供更多的约束信息,降低立体匹配的难度。
视差优化目的:
- 提高精度
- 剔除错误
- 弱纹理区优化
- 填补空洞
可使用的视差优化方法:
- 错误匹配的剔除方法:目前最常用的是左右一致性法,它是根据匹配的唯一性约束条件指定的。匹配的 唯一性指出对于左图像的某一像素点,在右图像上至多只有一个像素点与之一一对应。左右一致法就是将左右图像的对应点的视差值进行比较,若两个视差值小于一定的阈值, 则认为匹配成功,否则认为该视差不满足唯一性将被剔除。除了左右一致性法外,常用的匹配剔除方法还有剔除小连通区和唯一性检测等方法。连通区是指连通区内的视差与其邻域的视差之差小于一定的阈值,剔除小连通区是指剔 除视差图中很小的连通区,因为这种连通区通常是由于误匹配造成的;唯一性检测是指 对每个像素,计算其最小代价值和次小代价值,如果它们的差小于一定的阈值,说明匹配不是很准确,应该剔除。每种剔除错误匹配方法,都有其无法识别的情况,在实际应用中,可以将几种方法结合使用。
- 子像素优化:在视差计算中,得到的视差图都是整像素的,无法满足精度要求,为了提高视差精度,可以采用子像素优化技术,使用二次曲线内插的方法获得子像素。具体做法是首先将像素点的所有视差标注出来,然后找到最优视差点,接着确定该点周围两个视差点, 按照 3 点确定一条二次曲线的原理,得到过这 3 点的抛物线,该抛物线的顶点就是最优 子像素。
- 滤波:在计算像素的视差值时,都是基于小窗口进行的,容易产生噪声,因此可以使用中值滤波和均值滤波等图像滤波方式对视差图进行滤波,如果要保持较好的边缘精度,也可以考虑使用双边滤波。
立体匹配的基本约束条件
立体匹配技术是双目立体视觉中的重要技术,研究人员提出了许多实用的算法,其中也提出许多基本的约束条件。将这些约束条件运用到匹配算法中,就可以有效降低匹配的难度,提高立体匹配的速度和精度。常用的约束条件如下:
(1) 极线约束。极线约束是最常用的约束条件。极线约束是指在左图像中的一点,它在右图像上的 对应匹配点必定在某一条直线上,这条直线就是极线。使用极线约束就可以让图像的搜索范围由二维下降至一维,只需要在一条直线上进行搜索,这就可以大大减少搜索的复杂度,并提高了匹配的精度。
(2) 相似性约束。在进行立体匹配时,点、线、块等元素一定具有相同或相似的属性。
(3) 唯一性约束。对于待匹配图像,在原图像中至多对应一个点。一幅图像上的每个点只能与另一幅 图像上的唯一一个点一一对应,这样图像上的点至多有一个视差值。
(4) 左右一致性约束。若左图像上的一点 P,其在右图像上的对应点为 Q,则右图像上的点 Q 在左图像上的对应点应该是点 P,如果这两点不是一一对应的,则匹配会不满足唯一性条件,说明匹配失败。在进行立体匹配时,运用基本约束条件对匹配结果进行检验,可以有效排除很多误匹配的点,减小搜索范围,降低立体匹配计算的复杂度,提高立体匹配的速度和精度, 获得最好的匹配效果。
参考来自:
-
基于深度学习的立体匹配
本文使用了3D卷积的概念去获得更多的上下文信息,并采用回归的方法去预测视差值,不再使用传统的成本聚合,视差计算,视差优化的方法,利用一个端到端的网络直接生成最终的视差图。利用问题(对象)的几何知识,形成一个使用深度特征表示的匹配代价卷。我们通过对这一匹配代价卷应用3D卷积来结合环境(上下文)信息。利用本文提出的一种可微分的柔性argmin操作可以对匹配代价卷回归得到视差值。而且不用再给图块设置标签,直接将预测结果与真实视差图进行比对,再将误差反向传播即可,后来的许多网络都采用了这一思路。比如后来PSMNet只是在此基础上使用了金字塔池化模块,后面的3D卷积做成堆叠的沙漏型。
-
传统双目立体视觉匹配算法:
一般地,是否是全局立体匹配看是否构建了全局能量优化函数。(又称是否有代价优化)
立体匹配可划分为四个步骤:匹配代价计算、代价聚合/代价优化、视差计算和视差优化。
代价函数:AD、BT、SAD-BT(52条消息) 【算法】OpenCV-SGBM算法及源码的简明分析_JinSu_的博客-CSDN博客_sgbm算法
- 近处视差大,图像深度小,远处视差小,图片深度大,表现为在视差图中近处物体,轮廓更加清晰。
- SADWindowsize过小时,视差图的噪声较多;随着SADWindowsize的增大,视图越平滑,但当SADWindowsize过大时,视差图中的空洞现象会增加;
半全局立体匹配算法
半全局匹配算法是一种实用的计算视差图的匹配算法,其较好的中和了局部匹配和全局匹配的优缺点,在保持视差图效果相差不大的前提下,极大地提高了算法的效率,实现了更好的精度和效率的权衡,已广泛应用在现实中。
(1) 代价匹配。代价匹配是待匹配点与候选匹配点之间的相似度的衡量。按照匹配度量方式可以分为互相关性度量方法和差值度量方法。互相关性度量越大,两个点间的相似度就越高, 两个像素点为对应匹配点的概率就越大,不然两个像素点就越不可能是对应匹配点;同样,差值度量越小,像素点的相似度越高,差值度量越大,像素点的相似度越小。
在搜索匹配点之前,对每个像素都会指定一个视差范围 D,将搜索范围局限在 D 内, 并会使用一个大小为 W×H×D(W, H 为图像的尺寸)的矩阵来记录每个像素与视差范围内的像素的匹配代价值。该矩阵存储了所有的匹配代价值,可以有效减少重复的计算, 提高计算效率。匹配代价计算的方法有很多,如灰度绝对值差,灰度绝对值差之和,归一化系数, 互信息和 Census 变换等。不同的匹配代价计算算法都有其独特的优点,对数据的表现也各不相同,其中,最常用的方法是互信息和 Census 变换。
(2) 代价聚合。在初始代价匹配中,其计算范围只限于局部窗口中,只考虑了局部的相关性,对噪声非常敏感。为了得到更优的匹配,必须进行代价聚合操作。在代价聚合中,半全局匹配算法采用了全局能量最优策略。该方法设定一个全局能量函数,通过对其进行不断的优化,使该函数逐渐取到最小值,从而保证每个像素是最优匹配。该函数的定义如下:
该函数分为三部分,第一部分是主要部分,主要是对上一步的代价进行求和;第二,三部分是为了保证匹配满足连续性约束,若像素在一定范围内视差变化过大,说明匹配出错概率较大,需要进行惩罚,避免这种情况出现。其中,第二部分 是针对视差变化较小的情况,因而其惩罚的参数 P1 的值较小;第三部分是针对相邻像素视差变化较大的情况,因此,需要加大惩罚,P2 的值一般会比较大。
对邻域内不同的视差变化给予不一样的惩罚,有助于更好地应对各种不同的边缘情况。但由于视差大于 1 的范围很大,如果仅仅使用一个常数项对大视差变化进行惩罚往 往不够,因此,P2 的值需要动态调整,其调整公式如下:
通常,能量函数的最优化很难求得最优解,为了高效解决这个问题,半全局匹配算法提出了路径代价聚合的方法,只在固定的路径上计算匹配代价。对于某一像素,在其邻域内存在多条到达该像素的路径。该方法首先就某一条路径对匹配代价进行计算,然后对所有路径的匹配代价求和得到代价聚合值。
(3) 视差计算。在半全局匹配算法中,视差计算的操作较为简单,其采用赢家通吃的算法,即对每个像素来说,其代表的最优视差为最小代价聚合值。在此步骤中,对每个像素都进行了 视差计算,因而可以得到以原图一样大小的视差图,代表了图像的匹配关系。
(4) 视差优化。在视差计算步骤中,仅仅只是对代价聚合值进行选择,如果代价聚合不准确,会直接影响匹配结果,因此需要进行视差优化步骤,按照匹配的基本约束条件,对错误匹配 进行剔除并提高视差精度。视差优化常用的操作有剔除错误匹配,提高视差精度以及抑制噪声等。
参考:
-
SAD方法:
import os
import time
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
from skimage import data,filters,img_as_ubyte
LeftRawImage = cv.imread("./img/left.png")
RightRawImage = cv.imread("./img/right.png")
# convert the images to grayscale
LeftRawImage = cv.cvtColor(LeftRawImage, cv.COLOR_BGR2GRAY)
RightRawImage = cv.cvtColor(RightRawImage, cv.COLOR_BGR2GRAY)
##加sobel滤波效果会更好
#1.导入库直接处理
def sobel_filter(image):
edges = filters.sobel(image)
# 浮点型转成uint8型
edges = img_as_ubyte(edges)
return edges
#2.根据原理写出来 两种效果差不多
def sobel_filter(image):
height, width = image.shape
out_image = numpy.zeros((height, width))
table_x = numpy.array(([-1, -2, -1], [0, 0, 0], [1, 2, 1]))
table_y = numpy.array(([-1, 0, 1], [-2, 0, 2], [-1, 0, 1]))
for y in range(2, width-2):
for x in range(2, height-2):
cx, cy = 0, 0
for offset_y in range(0, 3):
for offset_x in range(0, 3):
pix = image[x + offset_x -
1, y + offset_y - 1]
if offset_x != 1:
cx += pix * table_x[offset_x, offset_y]
if offset_y != 1:
cy += pix * table_y[offset_x, offset_y]
out_pix = math.sqrt(cx ** 2 + cy ** 2)
out_image[x, y] = out_pix if out_pix > 0 else 0
numpy.putmask(out_image, out_image > 255, 255)
return out_image
LeftRawImage = sobel_filter(LeftRawImage)
RightRawImage = sobel_filter(RightRawImage)
##
def sad(left,right):
m,n,w,depth=720,1280,21,160
imgn,imgm=np.zeros((m,n)),np.zeros((m,n))
k_set,j_set=-160,210
# for i in range(int((1+w)/2),int((m-(1+w)/2)+1)):
# a = 1
# for j in range(int((1+w)/2+depth-1),int(n-(1+w)/2+1)):
# print(1,j)
for i in range(int((1+w)/2),int((m-(1+w)/2)+1)+1):
for j in range(int((1+w)/2+depth-1),int(n-(1+w)/2+1)+1):
tmp=[]
lwin=left[int(i-((1+w)/2-1))-1:int(i+((1+w)/2-1)),int(j-((1+w)/2-1))-1:int(j+((1+w)/2-1))]
for k in range(0,-depth,-1):
rwin=right[int(i-((1+w)/2-1))-1:int(i+((1+w)/2-1)),int(j-((1+w)/2-1)+k)-1:int(j+((1+w)/2-1)+k)]
diff=np.sum(cv.absdiff(lwin,rwin))
tmp.append(diff)
if k==k_set and j==j_set:
print('do')
junk=min(tmp)
index=tmp.index(junk)+1
imgn[i-1,j-1],imgm[i-1,j-1]=index-1,junk
return imgn
Disparity_image=sad(LeftRawImage,RightRawImage)
cv.imshow('视图差',Disparity_image)
cv.waitKey()
cv.imwrite('./res/img_sgd.jpg', Disparity_image)-
BM方法:
import numpy as np
import cv2
from matplotlib import pyplot as plt
imgL=cv2.imread("./img/left.png",0)
imgR=cv2.imread("./img/right.png",0)
# disparity range tuning
window_size = 3
min_disp = 0
num_disp = 320 - min_disp
stereo = cv2.StereoBM_create(
numDisparities=160, blockSize=21)
stereo.setPreFilterType(cv2.STEREO_BM_PREFILTER_NORMALIZED_RESPONSE)#使用归一化滤波
#stereo.setPreFilterType(cv2.STEREO_BM_PREFILTER_XSOBEL)
stereo.setPreFilterSize(17) #奇数
stereo.setPreFilterCap(31)
# stereo.setTextureThreshold(10)
# stereo.setMinDisparity(0)
# stereo.setSpeckleWindowSize(100)
# stereo.setSpeckleRange(64)
# stereo.setUniquenessRatio(0)
disparity = stereo.compute(imgL, imgR).astype(np.float32) / 16.0
plt.imshow(disparity, 'gray')
cv2.imwrite('./res/img_bm.jpg', disparity)
plt.show()-
SGBM方法:
与SAD的区别:
SGBM和SGM区别的地方在于匹配代价的计算:SGBM采用的是SAD-BT,而SGM采用的是MI。
过程:
- 预处理:使用sobel算子对源图像进行处理,并将经sobel算子处理后的图像映射为新图像,并得到图像的梯度信息用于后续的计算代价。
- 代价计算:使用采样方法对经预处理得到的图像梯度信息计算梯度代价、使用采样方法对源图像计算SAD代价。
- 动态规划:默认四条路经,并对路径规划的参数P1,P2进行设置(包括P1、P2、cn(图像通道数量)以及SADWindowsize(SAD窗口大小)的设置)。
- 后处理:包括唯一性检测、亚像素插值、左右一致性检测、连通区域的检测。
SGBM 立体匹配算法(源自Heiko Hirschmuller的《Stereo Processing by Semi-global Matching and Mutual Information》),可以获得比 BM 算法物体轮廓更清晰的视差图(但低纹理区域容易出现横/斜纹路,在 GCstate->fullDP 选项使能时可消减这种异常纹路,但对应区域视差变为0,且运行速度会有所下降),速度比 BM 稍慢, 352*288的帧处理速度大约是 5 帧/秒;
import numpy as np
import cv2
from matplotlib import pyplot as plt
imgL=cv2.imread("./img/left.png",0)
imgR=cv2.imread("./img/right.png",0)
# disparity range tuning
window_size = 3
min_disp = 0
num_disp = 320 - min_disp
stereo = cv2.StereoSGBM_create(
minDisparity=0,
numDisparities=160, # max_disp has to be dividable by 16 f. E. HH 192, 256
blockSize=21,
P1=8 * 3 * window_size ** 2,
# wsize default 3; 5; 7 for SGBM reduced size image; 15 for SGBM full size image (1300px and above); 5 Works nicely
P2=32 * 3 * window_size ** 2,
disp12MaxDiff=1,
uniquenessRatio=15,
speckleWindowSize=0,
speckleRange=2,
preFilterCap=63,
mode=cv2.STEREO_SGBM_MODE_SGBM_3WAY
)#各参数详解:https://blog.csdn.net/jackiesimpson/article/details/80099277
disparity = stereo.compute(imgL, imgR).astype(np.float32) / 16.0
plt.imshow(disparity, 'gray')
cv2.imwrite('./res/img_sgbm.jpg', disparity)
plt.show()-
代码报错及技巧
-
python报错:
- -报错:RuntimeWarning: overflow encountered in ubyte_scalars
像素加减运算溢出异常
解决:将像素强制为整型再计算就不会溢出了
- -nohup时报错,out.txt显示以下错误:
qt.qpa.xcb: could not connect to display qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "" even though it was found. This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem. Available platform plugins are xcb.在打开mobaxterm运行(或者nohup)时都没有报错,cv2.show()能展示,cv.imwrite()可以正常存储。
解决:linux解决加载Qt xcb plugins失败 - 倚剑天下 - 博客园 (cnblogs.com)
(44条消息) 关于qt缺少xcb问题终极解决办法_我爱下午茶的博客-CSDN博客_xcb
- TypeError: write() argument must be str, not bytes
使用二进制写入模式(‘wb’)来开启待操作文件,而不能像原来pyhon2那样,采用字符写入模式(‘w’)。
with open('./featurescore1/params.pkl', 'w') as f: cPickle.dump((random_seed, gamma, max_depth, lambd, subsample, colsample_bytree, min_child_weight), f) 改成 with open('./featurescore1/params.pkl', 'wb') as f: cPickle.dump((random_seed, gamma, max_depth, lambd, subsample, colsample_bytree, min_child_weight), f)lib/python3.7/site-packages/torch/nn/functional.py:3704: UserWarning: nn.functional.upsample is deprecated. Use nn.functional.interpolate instead.
warnings.warn("nn.functional.upsample is deprecated. Use nn.functional.interpolate instead.")解决:pytorch版本问题,python3.5 支持 upsample 函数,python3.7 不支持 upsample 函数。
“align_corners=True”应添加到高于 0.4 的 Pytorch 版本的上采样函数中。
假如我们忽略这个警告,会导致实验效果降低,简单来说,这个警告一定要改。
import torch.nn.functional as F F.upsample(output_branch1, (output_skip.size()[2],output_skip.size()[3]),mode='bilinear') 改成 F.upsample(output_branch1, (output_skip.size()[2],output_skip.size()[3]),mode='bilinear', align_corners=True) 或者 F.interpolate(output_branch1, (output_skip.size()[2],output_skip.size()[3]),mode='bilinear', align_corners=True)
- AttributeError: partially initialized module 'lightgbm' has no attribute 'Dataset' (most likely due to a circular import)
解决:检查是否存在文件和函数同名,例如把该py文件存为lightgbm,然后pycharm就错误识别成这个文件调用这个文件,py文件换个名字就好了。
-
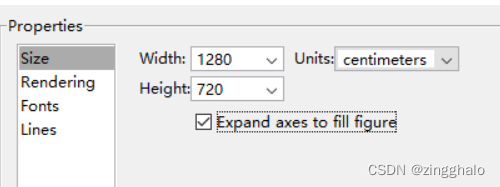
Matlab中高清figure图版导出方法
弹出figure后 file—expert setup—properties 设置如下:
-
像素减法:
-subtract()做图像减法同样遵循“饱和运算”规则,直接计算结果小于0时被截断到0。和符号+计算一样,如果2个图像直接用运算符-进行计算,实际是按照numpy数组计算,最终是对256求模计算后的结果;absdiff()能从绝对值差异的角度反映2个图像之间的差异。图像和标量加减运算时,多通道的标量值用一个4元组表示。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









