









一, 线性回归(linear regression)
引入:
房价预测(以英尺计算)
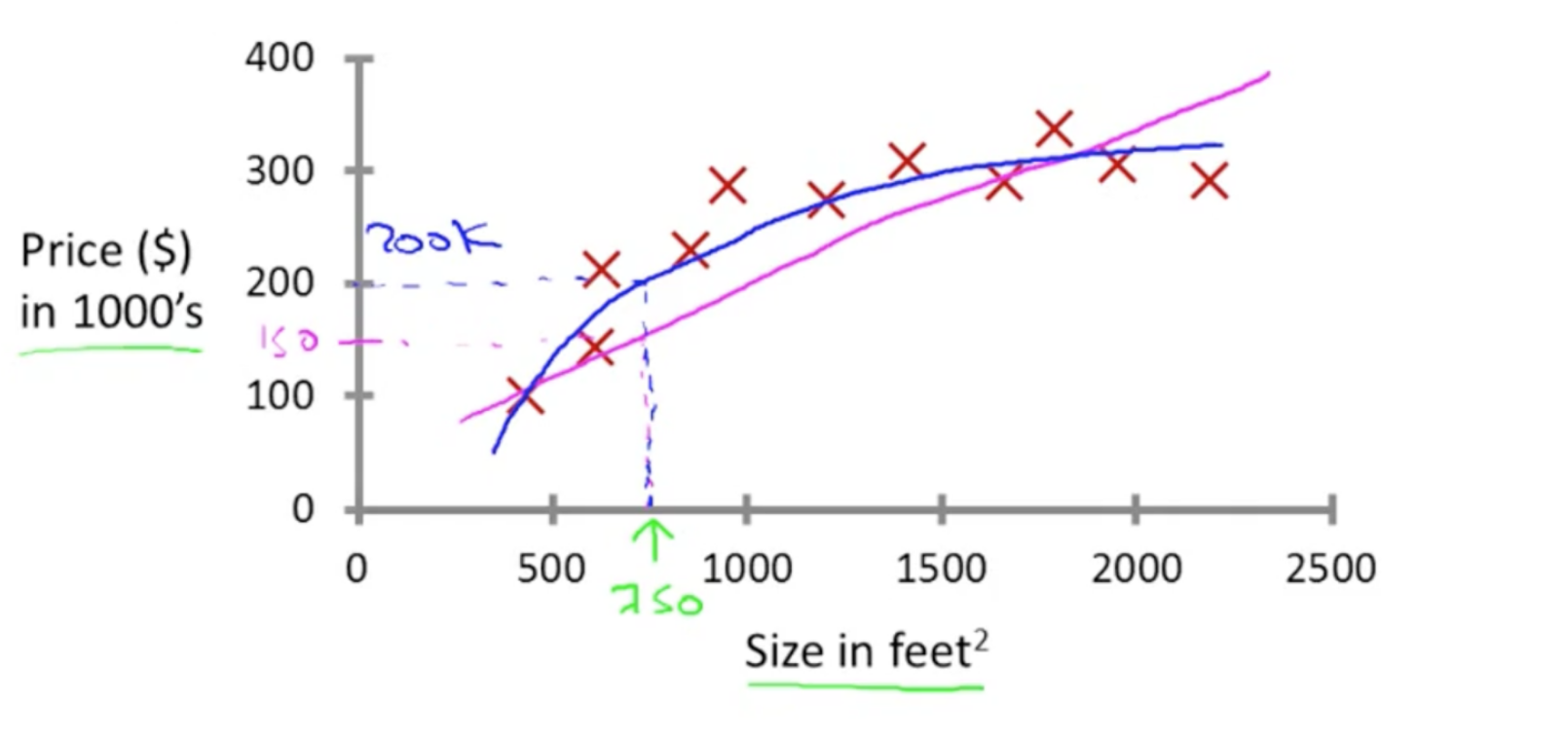
表达式
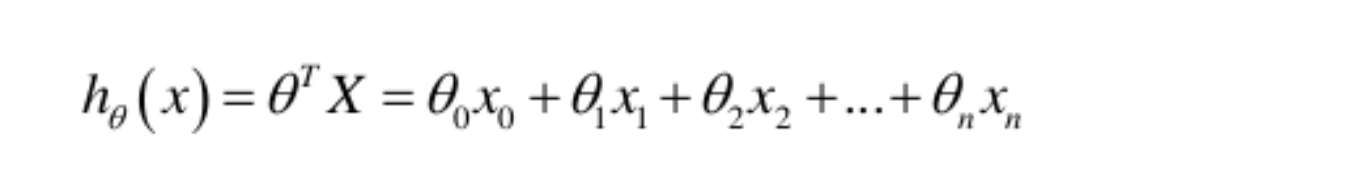
衡量好坏的标准:代价函数
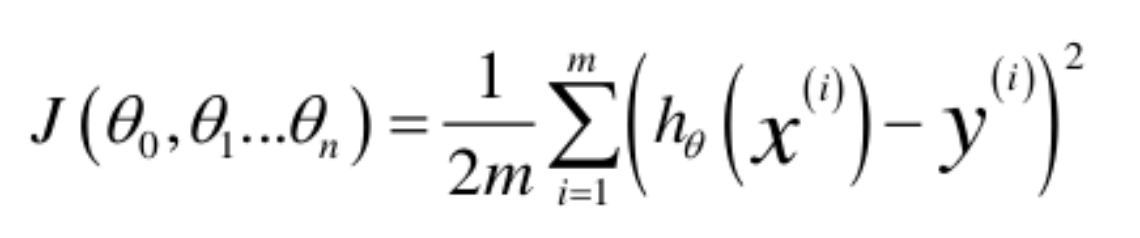
去往何方?
值域目前是无穷大,假如我想解决分类问题,应该如何才能把值域控制在一个较小的区间范围之内呢?
试想如下案例:
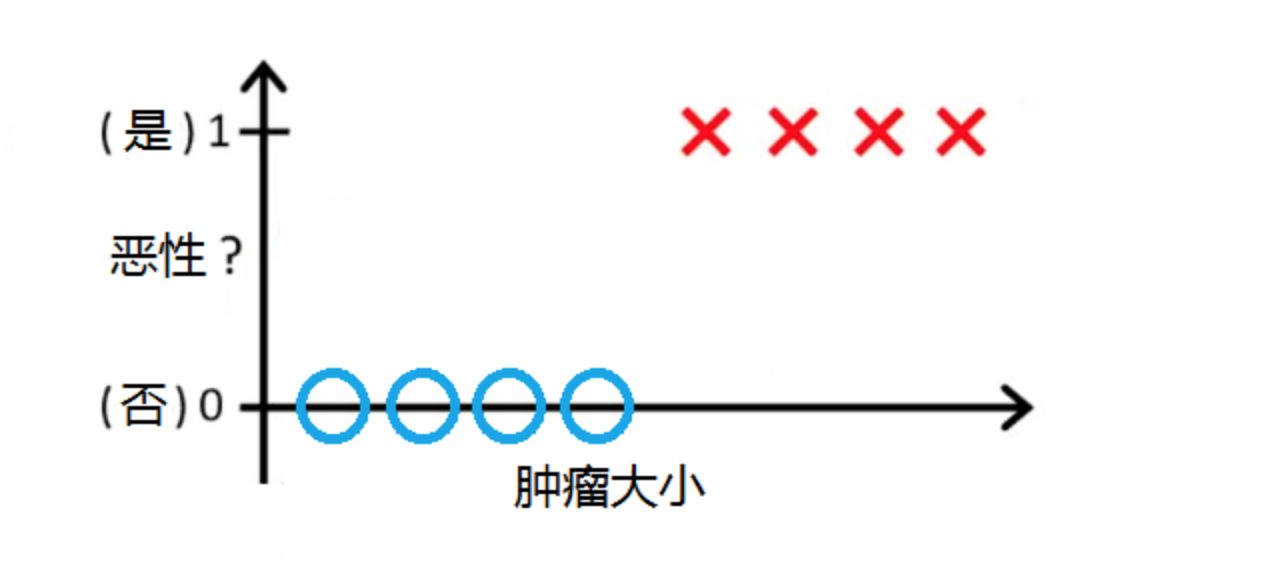
二,逻辑斯蒂回归模型(logistics regression)
(logistic regression)是统计学习中经典的分类方法.(属于对数线性模型)
表达式:

sigmoid:
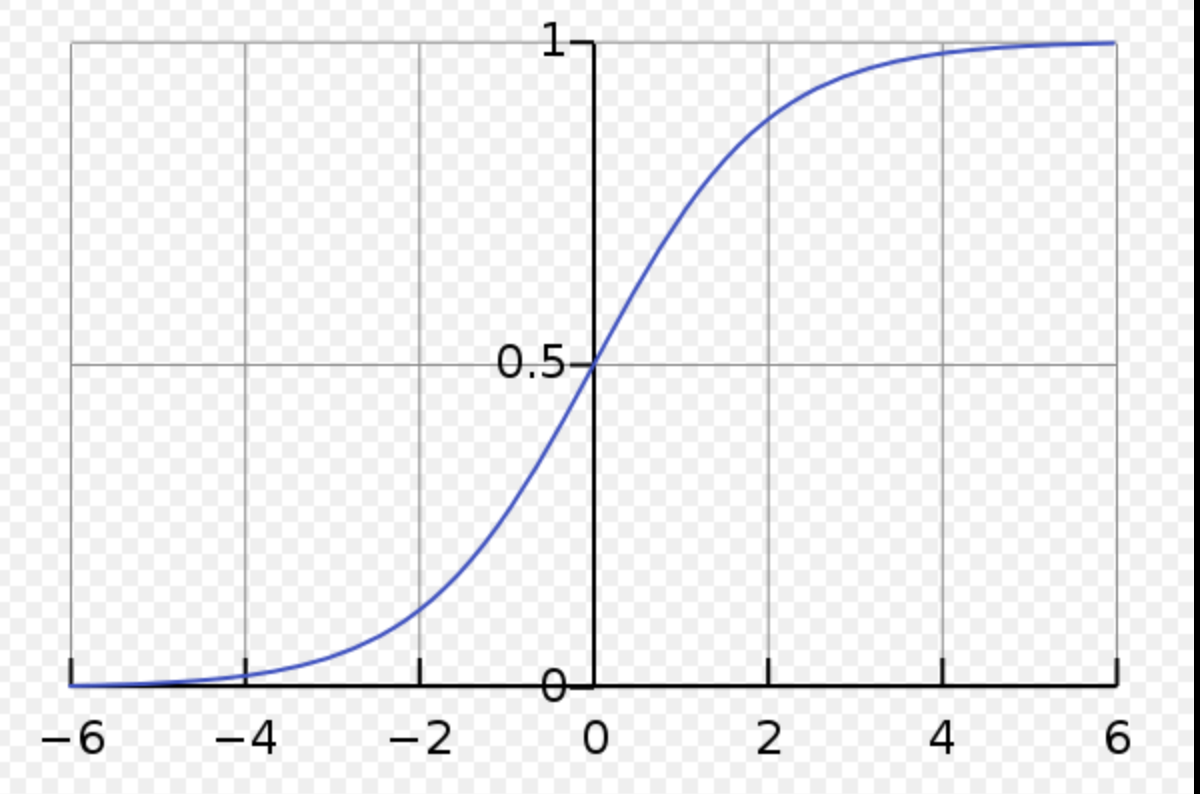
优点:
1. 是逻辑回归的算法已经比较成熟,预测较为准确;
2. 该模型求出的系数易于理解,便于解释,不属于黑盒模型,尤其在银行业,80%的预测是使用逻辑回归;
3. 其结果是概率值,可以做ranking model;
4. 训练比较快;
缺点:
1. 分类较多的y都不是很适用;
2. 对于自变量的多重共线性比较敏感,所以需要利用因子分析或聚类分析来选择代表性的自变量;
3. 其预测结果呈现S型,两端概率变化小,中间概率变化大比较敏感,导致很多区间的变量的变化对目标概率的影响没有区分度,无法确定阈值;
应用:广告行业的点击率预估:LR作为CTR预估的一个经典模型
把被点击的样本当成正例,把未点击的样本当成负例,那么样本的ctr实际上就是样本为正例的概率,LR可以输出样本为正例的概率,所以可以用来解决这类问题
实战例子:
plot_iris_logistic.py

三,支持向量机.
它是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,SVM的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也定价于正则化的合页损失函数的最小化问题,SVM的学习算法是求解凸二次规划的最优化算法.
I,线性可分支持向量机(或硬间隔支持向量机)
构造它的条件是:训练数据线性可分,其学习策略是最大间隔法,可表示为凸二次规划问题,其原始最优化问题是:
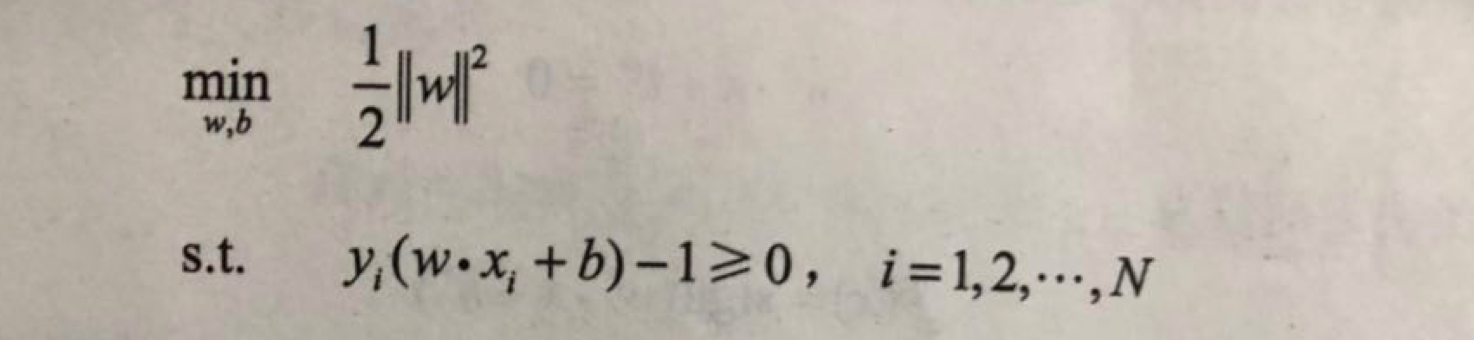
求得最优化问题的解为w,b,得到线性可分支持向量机,分离超平面是:
w*x+b=0
分类决策函数是:
f(x)=sign(w*x+b)
线性可分支持向量机的最优解存在且唯一,位于间隔边界上的实例点为支持向量,最优分离超平面由支持向量完全决定.
二次规划问题的对偶问题是:
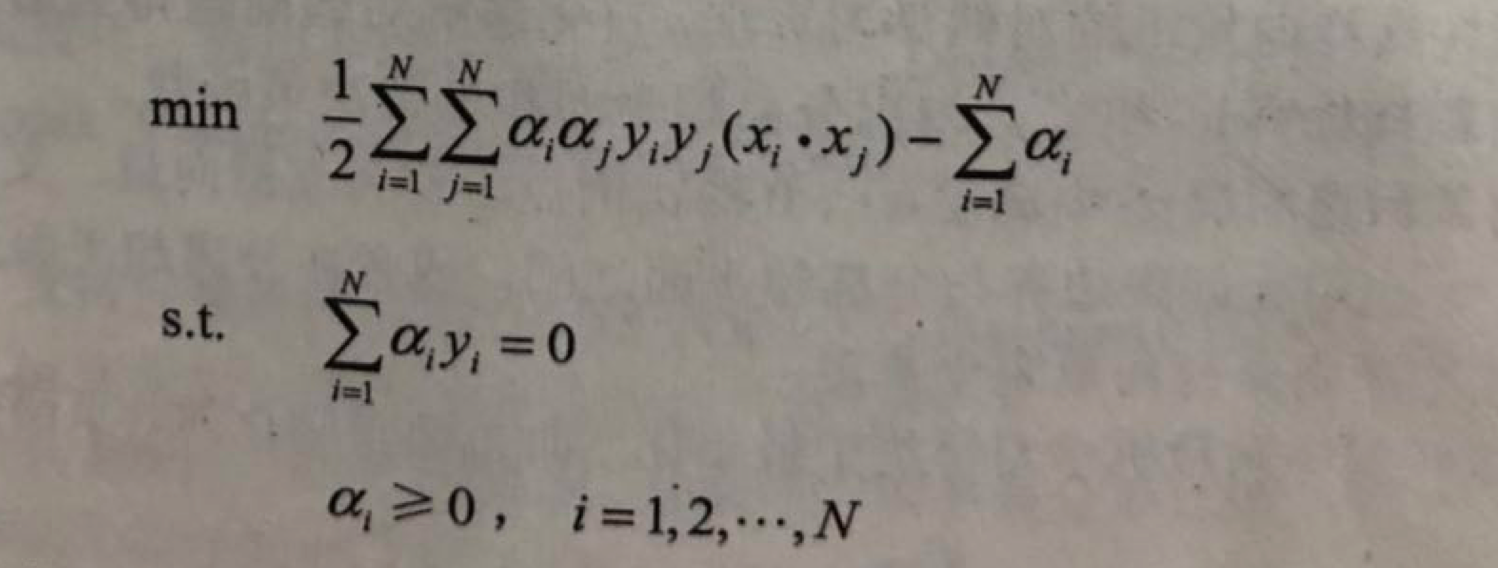
通常,通过求解对偶问题学习线性可分支持向量机,即首先求解对偶问题的最优值a,然后求最优值w和b,得出分离超平面和分类决策函数.
II,线性支持向量机(或软间隔支持向量机)
ps:现实中训练数据是线性可分的情形较少,训练数据往往是近似线性可分的.
对于噪声或者例外,通过引入松弛变量ζ,使其"可分",得到线性支持向量机学习的凸二次规划问题,其原始最优化问题是:
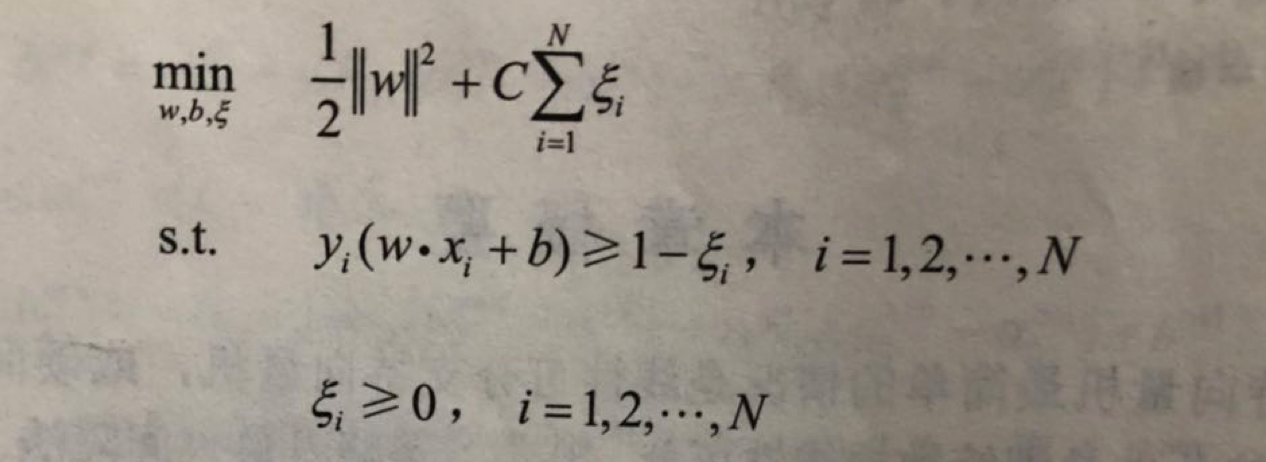
求解原始最优化问题的解 w,b,得到线性支持向量机,其分离超平面为:
w*x+b=0
分类决策函数为:f(x)=sign(w*x+b)
线性支持向量机的解w唯一但 b 不一定唯一.
其对偶问题是:
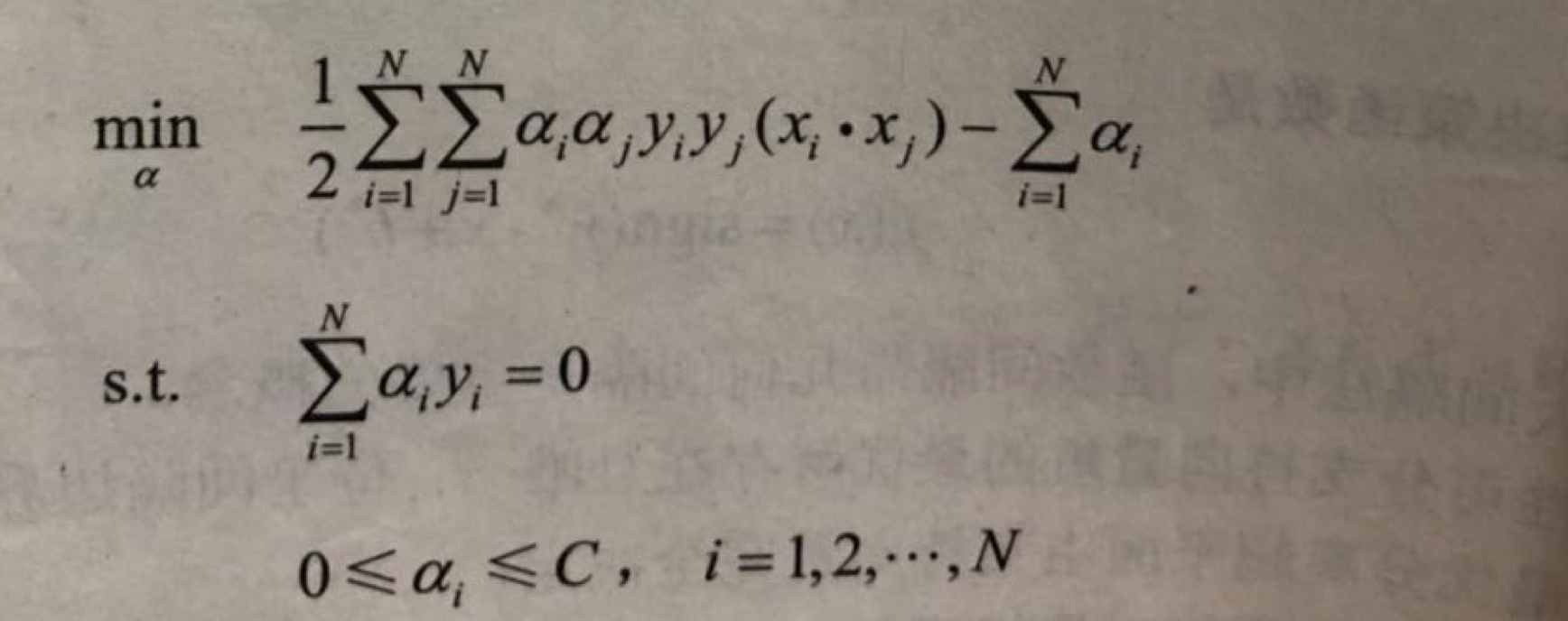
线性支持向量机的对偶学习算法.首先求解对偶问题得到最优解a,然后求原始问题最优解w,b,得出分离超平面和分类决策函数.
线性支持向量机学习等价于最小化二阶范数正则化的合页函数.
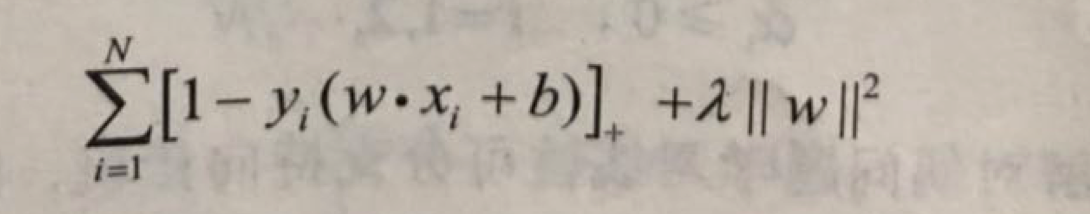
III,非线性支持向量机
对于输入空间中的非线性分类问题,可以通过非线性变换将它转化为某个高维特征空间中的线性分类问题.在高维特征空间学习线性支持向量机.由于在线性支持向量机学习的对偶问题里,目标函数和分类决策函数都只涉及实例与实例之间的內积,所以不需要显示的指定非线性变换,而是用核函数来替换当中的內积,核函数表示,通过一个非线性转换后的两个实例间的內积.具体的,k(x,z)是一个核函数或正定核,意味着存在一个从输入空间x到特征空间h的映射Φ(x):x->h,对于任意x,z∈ x,有
k(x,z)=Φ(x)*Φ(z)
对称函数k(x,z)为正定核的充要条件如下:对任意xi∈ X,i=1,2,...,m ,任意正整数m,对称函数k(x,z)对应的Gram矩阵是半正定的.
所以,在线性支持向量机学习的对偶问题中,用核函数k(x,z)替代內积,求解得到的就是非线性支持向量机
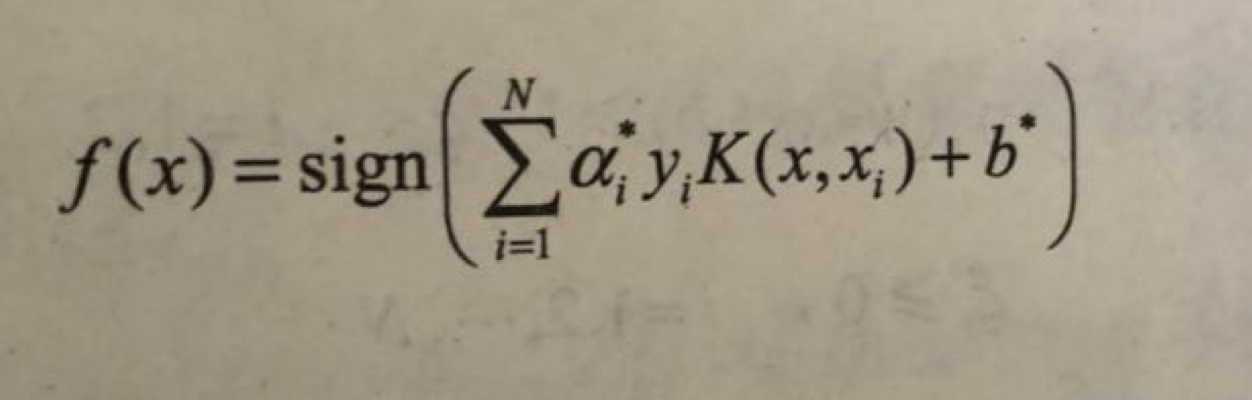















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









