






现在大数据时代我们的数据都是海量的,如果有大量的数据需要缓存,那么一个缓存机器肯定是不够的,所以采取分布式缓存方式。于是,我们就需要将数据分布在多台机器上该如何決定将哪个数据放到哪个机器上呢?
一、哈希算法
用哈希算法对数据取哈希值,然后对机器个数取模,这个最终值就是应该存储的缓存机器编号。
存在问题:
如果数据增多,需要扩容时所有的数据都要重新计算哈希值,然后重新搬移到正确的机器上。这样缓存中的数据一下子就都失效了。所有的数据请求都会穿透缓存,直接去请求数据库。这样就可能发生雪崩效应,压垮数据库。

二、一致性哈希
一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对机器个数进行取模,而一致性Hash算法是对2^32取模。一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形)。
在计算一致性hash时采用如下步骤:
- 首先求出(节点)的哈希值,并将其配置到0-2^32-1的虚拟圆上。
- 然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
- 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个node上。如果超过2^32仍然找不到,就会保存到第一台机器上。

如下图添加一台机器(node5)时,并没有影响到所有的数据,只有node4之前的节点node2到node5之间的数据受影响。

一致性哈希在节点较少时,容易因为节点分部不均匀而造成数据倾斜问题。(如下图)
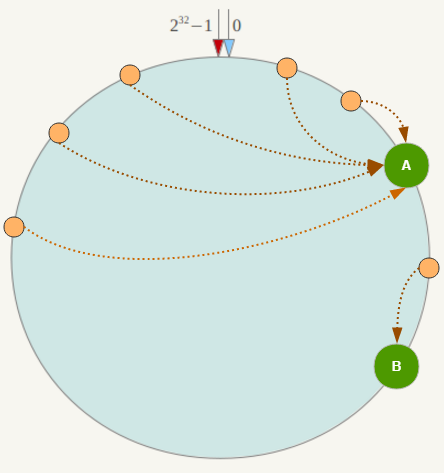
为了解决上面出现的数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个节点计算多个哈希,每个计算结果位置都放置一个此节点,称为虚拟节点。
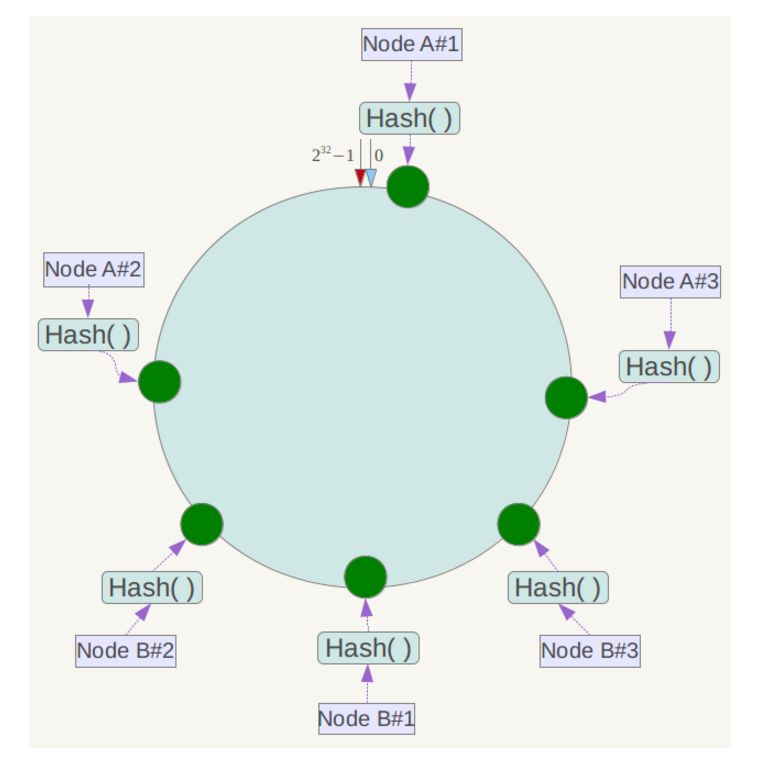
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。















 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









