







按目标分类:识别一个词是由成人还是儿童说的
可用性分类:为学习标记的录音,标记的未标记录音
可能的特征:F0音高 F1共振峰
语音识别的基本方程:
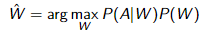
声学模型 P(A|W) 估计声学 A 和单词序列 W 之间的匹配。前端将声学信号转换为一系列特征向量(例如 MFCCs),因此,声学模型计算的概率现在可以写成,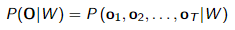 这可以解释为声音和单词之间的距离。
这可以解释为声音和单词之间的距离。
训练模型以将声学信号映射到分类任务的目标值。例如,可以自动检测儿童说话。在这种情况下,声学模型需要计算两个概率,P(O|′child′) 和 P(O|′adult′) ,然后通过比较这些概率并选择具有最高概率的标签来执行检测(=识别)操作。使用链式法则,我们可以写出 (M =’ child’):
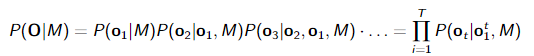 链式法则允许将概率项拆分为概率的乘积,每帧一个概率。然而,对于每一帧,我们将之前的帧作为条件变量(即’|'右侧的部分)。对于许多应用程序都会假定,帧是独立的。
链式法则允许将概率项拆分为概率的乘积,每帧一个概率。然而,对于每一帧,我们将之前的帧作为条件变量(即’|'右侧的部分)。对于许多应用程序都会假定,帧是独立的。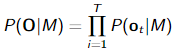 这公式意味着对于每一帧都会计算一个分数(概率)。
这公式意味着对于每一帧都会计算一个分数(概率)。
高斯混合模型
高斯模型参数的学习比较复杂,需要期望最大化 Expectation Maximisation (E-M)算法。
高斯混合模型生成数据的方法有:
- 根据混合权重随机选择混合成分.
wi ≡ P(gt = i)
其中 gt 是所选高斯模型在时间 t 的索引
- 第 i 个高斯分布的样本,受其均值和(协)方差的影响
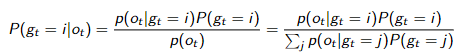
此过程表明涉及另一个随机事件——选择高斯分布——无法通过简单观察 ot 立即恢复。但是,如果给定一个观察值,则可以在任何给定时间点计算某个高斯分布的概率,从而选择最有可能产生样本的高斯分布。
逐帧训练
- 统一初始化混合权重,随机初始化均值和方差
- 对于训练示例(和所有训练示例)中的每个观察点,使用上面方程找到最可能的高斯分量 gt。计算分配给每个高斯 i 的观测值数,即 Ni。收集观测值并分配给每个高斯分布。
- 根据分配给每个高斯分布的向量计算新的均值和方差
- 使用计数计算新的权重(N = Ni的求和)Wi = Ni / N
- 重复直至likelihood变小
soft assignment 软分配
- 将每个观察值分配给最可能的高斯分布(期望值)
- 重新计算模型参数(最大化)
Li (t) = P(gt = i | ot ) 这些值给出了每个高斯对当前观察 ot 的贡献程度的印象
最大化期望算法 训练 高斯混合模型
-
统一初始化混合权重,随机初始化均值和方差。
-
对于训练样例(和所有训练样例)中的每个观察点,以及每个高斯 i 计算 Li (t)
-
使用以下恒等式计算新的均值和方差
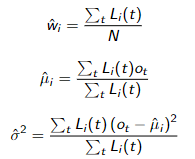
-
重复直至likelihood变小
GMM语音模型
波形通常被转换成一系列特征,或者说特征向量。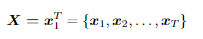

变成上图的样子,其中每个矩形代表一个 d 维特征向量。当然可以考虑计算整个序列的可能性,但是序列长度通常变化很大。因此会利用frame的独立假设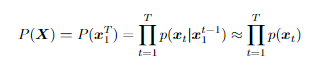 。近似是必要的,因为语音中的帧独立性是不现实的。在大多数情况下,特征向量是某种形式的频谱切片表示(频谱图中的切片),例如由 MFCC 特征组成。可以观察到频谱图的变化是平滑的,这清楚地表明了依赖性。
。近似是必要的,因为语音中的帧独立性是不现实的。在大多数情况下,特征向量是某种形式的频谱切片表示(频谱图中的切片),例如由 MFCC 特征组成。可以观察到频谱图的变化是平滑的,这清楚地表明了依赖性。
假设 frame 从正态(高斯)分布或更好的分布族派生的可能性。生成样本的随机过程从从一组固定的 M 高斯分布中选择一个高斯分布开始。选择过程受概率支配 P (gt = j) = P (g = j) = wj. 这个概率表示第j个高斯分布在t时刻被选为高斯分布的概率,即gt。这当然是与时间无关的,分配一个先验值或权重 wj 。现在根据其参数化从该高斯中选择一个样本,即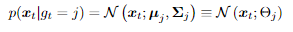 。这里均值是向量值,协方差矩阵必须是实对称正定矩阵eal symmetric positive denitematrix。这意味着需要估计大量参数,因此需要大量训练数据。再然后根据协方差的对角线假设,这意味着所有维度都是独立的。(但是在语音这块很难证明)
。这里均值是向量值,协方差矩阵必须是实对称正定矩阵eal symmetric positive denitematrix。这意味着需要估计大量参数,因此需要大量训练数据。再然后根据协方差的对角线假设,这意味着所有维度都是独立的。(但是在语音这块很难证明)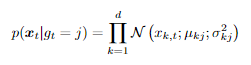
然而,这个问题在一定程度上被混合模型解决了,可以用二维图来说明。从教科书上可以看出,二维正态分布的等高线是椭圆。椭圆的角度由协方差矩阵的非对角线元素确定。自然地,对角协方差矩阵没有非对角元素,因此椭圆的轴与坐标对齐。可以考虑用对角协方差分布的总和来近似完全协方差
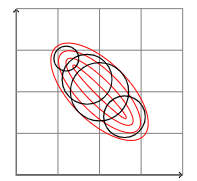
模型拟合
在对语音建模时,假设混合分量的数量 M 是已知的。然而在实践中,应该进行实验以找到合适的数量。这是在独立测试集上为手头任务产生最佳性能的数字。可以通过计算数据的总似然性来简单地计算模型对数据的适应程度。假设我们总共有 K 个话语,每个话语的长度为 Tk。那么总的可能性简单地由下式给出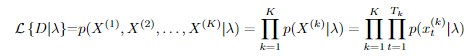 。D可能是训练集或测试集。增加混合成分的数量虽然可以保证增加训练集的可能性(至少假设适当的训练策略),但是这会过拟合。
。D可能是训练集或测试集。增加混合成分的数量虽然可以保证增加训练集的可能性(至少假设适当的训练策略),但是这会过拟合。
计算成本
计算数据的可能性需要大量小数的乘积,从而很快导致数字超出计算机的浮动点精度范围。对于许多情况,一个简单的解决方案是在对数域中进行所有计算(自然对数在实践中最方便)。数据的对数似然由下式给出。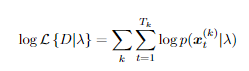
对于典型的语音表示,每帧(特征向量)的典型对数似然值范围从 -60 到 -80。在没有数字问题的情况下,对这些值求和要容易得多。不幸的是,GMM 贡献的计算不容易简化。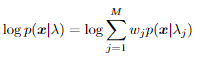
虽然取正态分布的对数导致简单的计算,即二次形式,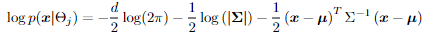
用GMM 进行分类
分类是为数据分配标签的任务,标签是从有限集合中选择的。在语音的情况下,可以对不同的数据部分执行此类标记。可以为每一帧(特征向量)或语音片段分配一个标签,例如音素、单词或完整的话语。
一种简单而标准的方法是为每个class训练一个 GMM。让我们假设 L 个标签可用。然后可以获得每个标签的 GMM,即 λl l = 1 。 . . L.给定一段语音X 然后配最可能的标签,这是简单应用了朴素贝叶斯规则。如果我们能够忽略先验,则分类任务(找到 X 的标签 c)可以简单地写为下面的公式。利用了这样一个事实:即在对数域中找到最大值是等效的,并且一个类由该 λl 类的模型表示。
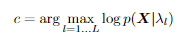
一些总结
高斯混合模型GMM 是一种简单但功能强大的生成模型,可用于语音处理,以描述帧级别的语音生成。
GMM 是假设所有抽取的样本都是相同分布的(i.i.d)。但是语音被认为是一系列高度相互关联的数据点。因此,GMM 仅在特定情况下使用,生成模型旨在提供生成具有与真实样本中发现的分布相似的分布的数据的途径。给定模型参数 λ ,观察结果来自 高斯加权和组成的分布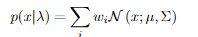















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









