







github库的DALLE2基于OPENAI和pytorch实现
以前学习强化学习的时候接触过一点点OPENAI但是没怎么深入学习
有用到CLIP模型和Unet模型
好 然后并不知道CLIP模型是个啥hhh所以先挖坑吧先去学一手CLIP模型
CLIP
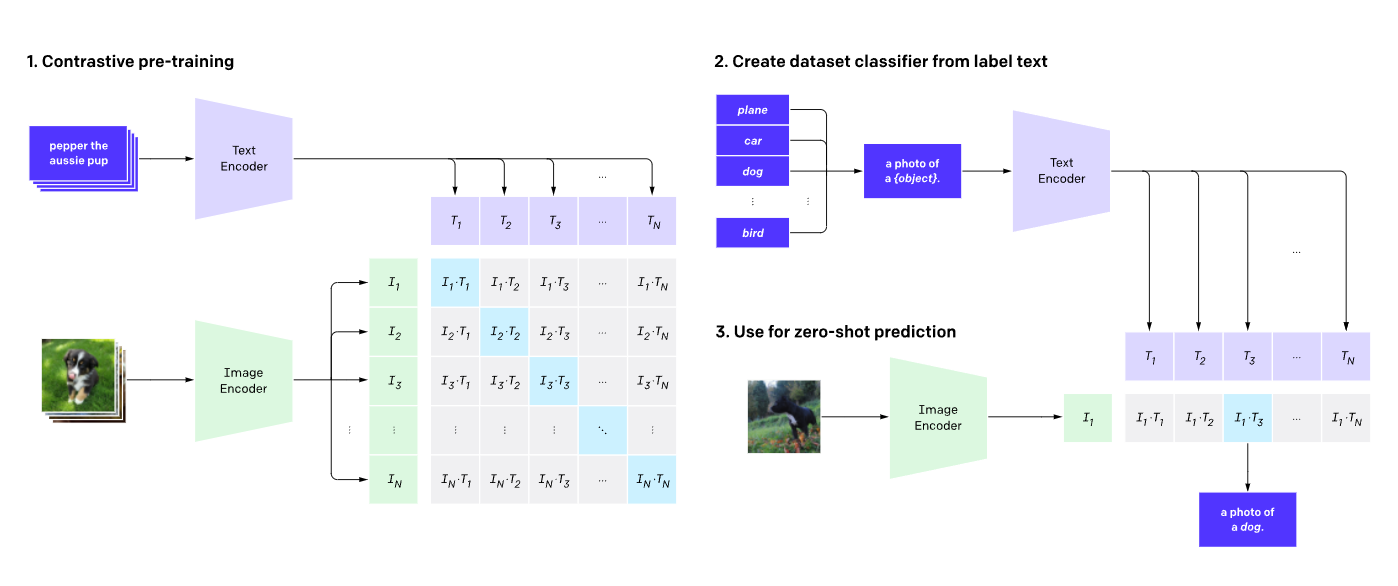
CLIP也是OpenAI的模型。
预训练了一个图像编码器和一个文本编码器,以预测图像与数据集中的文本配对。
图像和文本的向量被用来构建相似度矩阵
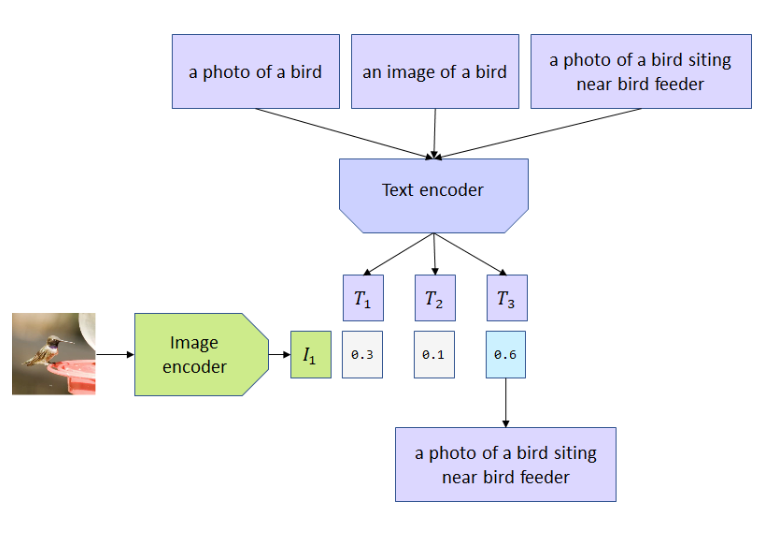
然后CLIP对不同的文字描述十分敏感
虽然CLIP有个很厉害的OCR系统,但是对预训练数据集中未涵盖的图像的泛化能力也很差。一般在识别常见物体方面表现良好,更复杂的任务上则不佳。
CLIP能够快速连接文本和图像,还能同时完成图像分类任务和图像生成任务。Dalle一代好像就是用了CLIP造的生成模型。
;另一篇博文介绍了许多CLIP的用例包含,对于图片内容的审核,图片搜索,图片相似度(!这个居然能识别不同的水印),对象追踪(视频里的对象追踪),对图像自动生成内容描述,甚至还能修复损坏的图像(比如运用了高斯模糊或者高斯噪声)
就感觉下来CLIP还挺厉害的…

















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









