







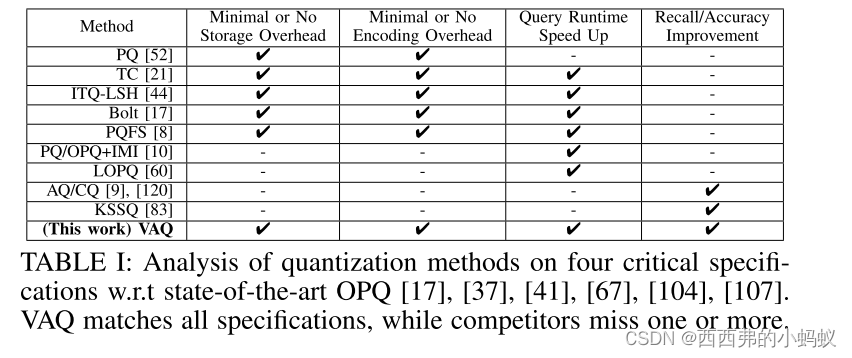
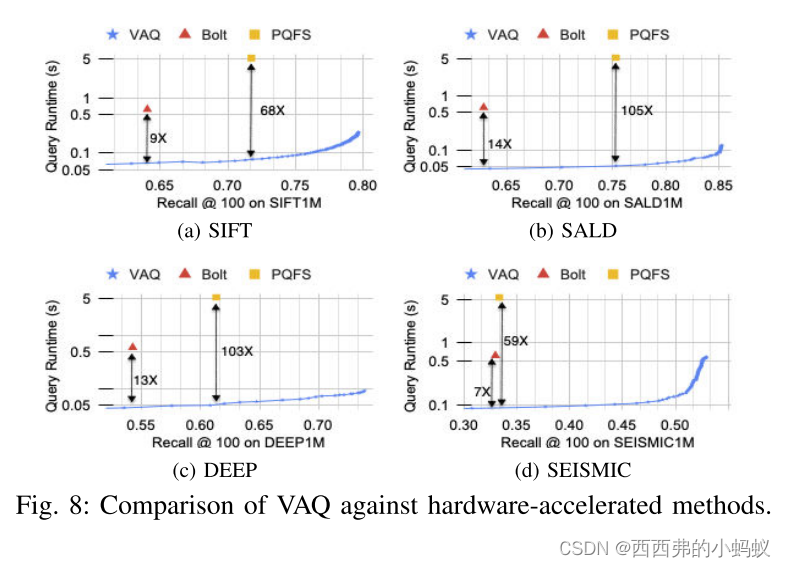
随着高维数据的爆炸性增长,最近邻搜索中出现了很有前途的近似方法。其中,量化方法因其快速的查询响应和较低的编码和存储成本而受到关注。量化方法将数据维度分解为不重叠的子空间,并对每个子空间使用不同的字典进行编码。这种最先进的方法在试图平衡子空间的相对重要性的同时,在子空间之间均匀地分配字典大小。不幸的是,不可能总是达到统一的平衡,并且可能导致不令人满意的性能。类似地,硬件加速的量化方法可能会牺牲准确性来加快查询的执行。我们提出了一种方差感知量化(VAQ)方法,通过智能地根据子空间调整字典大小来编码数据,以缓解这些显著的缺陷。VAQ利用内在的降维特性来导出子空间,只部分地平衡子空间的重要性。然后,VAQ通过求解一个约束优化问题,将字典大小按比例分配给每个子空间的重要性。此外,VAQ通过一种硬件无关的算法解决方案跳过数据和子空间,从而加速了查询执行。为了证明VAQ的鲁棒性,对量化、哈希和索引方法进行了广泛的评估,使用五个大规模基准数据集。VAQ在准确性方面明显优于最强的哈希和量化方法,同时实现了高达5倍的加速。与最快但精度较低的硬件加速方法相比,VAQ实现了高达14倍的speedup@recall性能。重要的是,使用100多个数据集进行的严格统计比较表明,即使预算只有一半,VAQ也明显优于竞争方法。值得注意的是,VAQ的简单数据跳跃解决方案实现了与基于索引的方法相竞争或更好的性能,突出了对量化方法新索引的需求。
面临挑战:
量化方法的性能严重依赖于维护一个大的字典来将数据样本映射到最近的字典项。然而,为所有维度构建一个大字典是不可行的。乘积量化(PQ)[52]通过将原始数据维度分解为不重叠的子空间来解决这一重要问题。
挑战:首先,PQ不知道每个子空间的相对重要性,并且在子空间中均匀分配字典大小,这可能会影响搜索精度。其次,对于大型数据库来说,扫描编码向量的代价变得非常昂贵。
方法:
设计了一种量化方法来提高搜索精度和运行时性能。本文提出方差感知量化(VAQ),一种新方法,通过根据子空间的重要性智能地将字典大小适应于子空间来编码数据。VAQ度量重要性,即每个子空间解释原始数据的总方差的数量。为了学习如何自适应地编码数据,VAQ分为三个步骤。首先,VAQ算法利用数据的降维特性有效推导出非均匀子空间,部分平衡了子空间的重要性;其次,给定一个比特预算,VAQ在一些约束条件下,通过优化一个目标函数来最大化所有子空间和每个子空间的方差,从而确定每个子空间字典的项数。通过这种形式,VAQ可以灵活而轻松地集成约束,以捕获不同的应用程序需求。最后,VAQ通过将子空间映射到相应的字典项来构造大小可变的字典并对数据进行编码。
为了加快查询性能,VAQ引入了一个两步的硬件无关算法解决方案。首先,对编码数据进行聚类划分,缓存其到相应簇质心的距离,并对每个簇中的编码数据按照离相应簇质心最近到最远的顺序进行维护;在查询过程中,VAQ只访问与查询最近的聚类,并利用欧氏距离的三角不等式性质,避免了扫描不能属于最近邻居的编码数据。对于通过第一个过滤器的编码数据,当增量计算的距离超过目前为止最好的距离时,VAQ还使用早期放弃来查找所有子空间的索引。VAQ设法跳过对大多数数据样本的访问,并对子空间的子集进行查找。
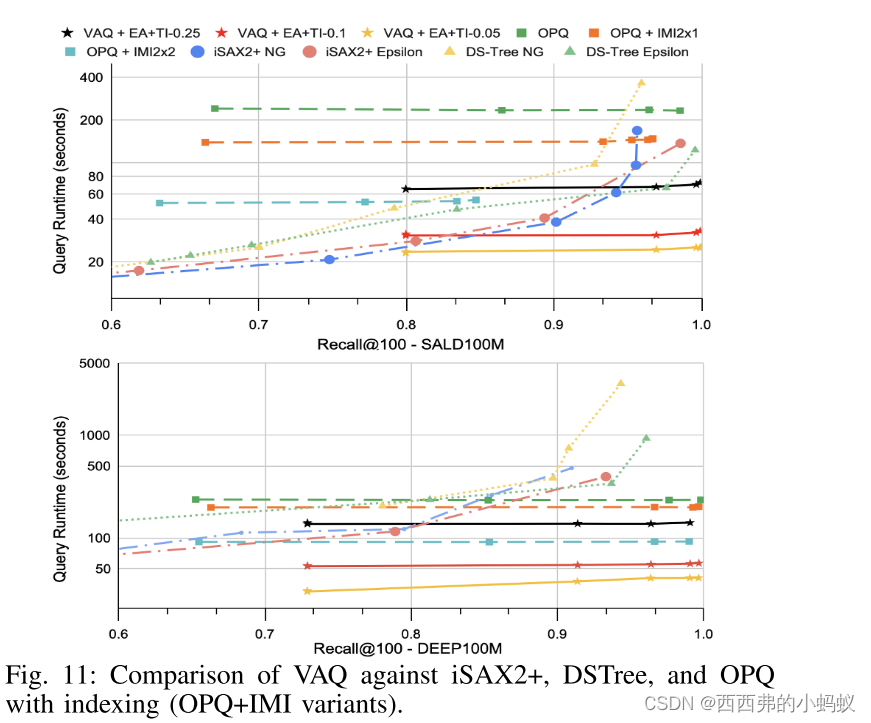
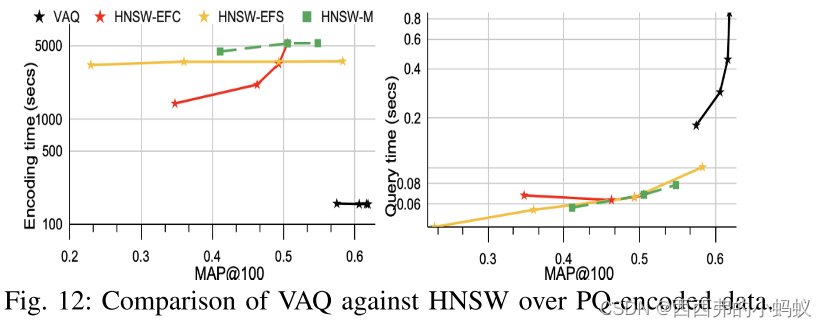
我们进行了综合评估,以证明VAQ的有效性。具体来说,我们将VAQ与最先进的量化、哈希和索引方法进行比较。VAQ在准确性方面明显优于最强的哈希和量化方法,同时实现了高达5倍的加速
小结:Exact and Approximate Similarity Search 1)Searching with Hashing Methods 2) LSH or data-independent methods 3) L2H or data-dependent methods
Searching with Quantization Methods 1)Vector Quantization (VQ) 2)Product Quantization (PQ) 3)Optimized Product Quantization (OPQ)

框架
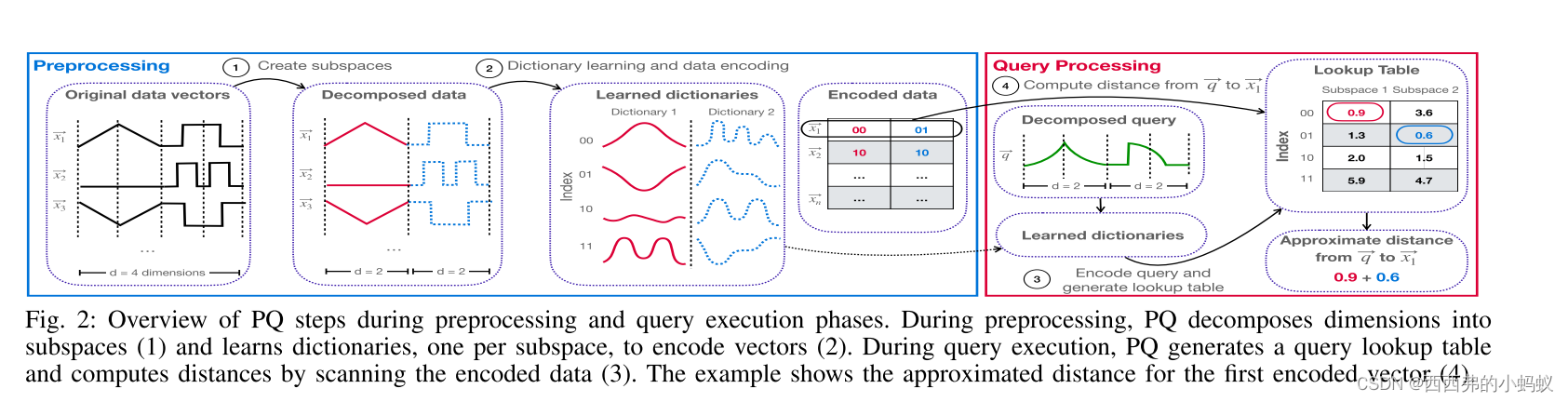
本文的目标是自动化派生子空间的过程,并根据PQ方法的重要性为子空间分配比特预算。本文提出了VAQ,一种新的数据驱动量化方法,用于自适应编码数据并加速查询执行。
VARIANCE-AWARE QUANTIZATION
对于VAQ,我们首先关注如何有效地度量维度的重要性,以及如何分解大小不等的非重叠子空间(第III-B节)。只部分平衡子空间的重要性(即在子空间中传播重要性),并解决一个约束优化问题,通过最大化子空间的整体重要性自适应地为子空间分配比特,而不忽略每个子空间的重要性(第三- c节)。解决了这两个基本问题后,VAQ的进展与其他PQ方法类似,但有两个显著的差异。首先,VAQ构造大小可变的字典来编码数据(第III-D节)。其次,VAQ通过两种硬件无关的数据跳过解决方案(Section III-E)加速了查询执行。

Preserving Subspace Importance Ordering:
形成的子空间在内部按照初始降序排列。然而,相邻子空间的某些方差很少会乱序(即,具有许多次要维度的子空间的方差排名高于具有较少重要维度的子空间)。
我们通过从相邻(向右)子空间移动维数来解决这个问题,直到顺序保持不变,从第一个子空间开始。维的移动保证了子空间的重要性排序,这对于我们在下一节介绍的位分配解决方案以及查询加速的子空间跳过策略至关重要。To efficiently compute and rank variances per dimensions,
we exploit the intrinsic properties of PCA

Adaptive Bit Allocation for Subspaces(实现最大信息bit的分配)
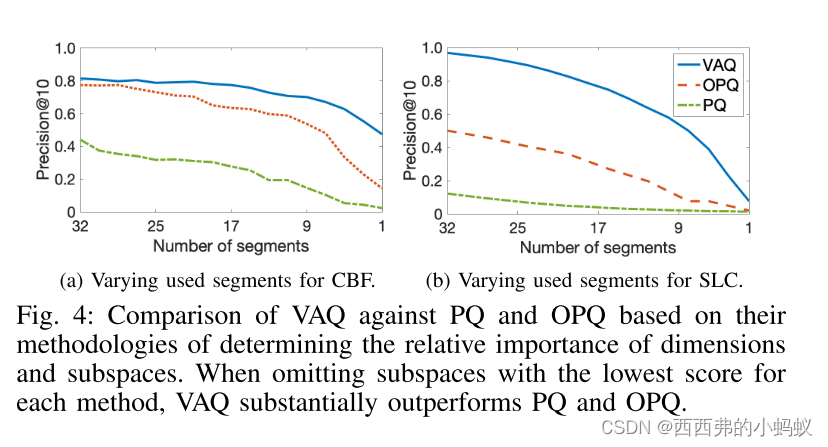
对于VAQ,我们建议最大化所有子空间(P1)和每个子空间(P2)的总体信息量。通过在所有子空间(P1)中分配位,我们实现了最小的搜索精度损失 。把更多的比特分配给信息更丰富的子空间(P2),我们更准确地捕获了这些子空间中解释的方差。

提出了一个约束优化问题的求解方法。为了避免只将比特分配到少数几个重要的子空间,我们对比特分配变量引入了一些线性约束

Variable-sized Dictionaries for Data Encoding


VAQ为每个子空间构造可变大小的字典。VAQ分两步对数据进行编码。首先,VAQ使用k-means为每个子空间构造字典(类似于PQ和OPQ)。具体来说,kmeans的质心总结了子空间中k个分区的基本模式,因此,作为该子空间的字典项。其次,给定字典,VAQ通过寻找数据样本对应字典中最近的字典项(使用欧氏距离),对数据样本的每个子空间进行编码;编码后的数据由所有子空间中最近的字典项的索引连接而成。
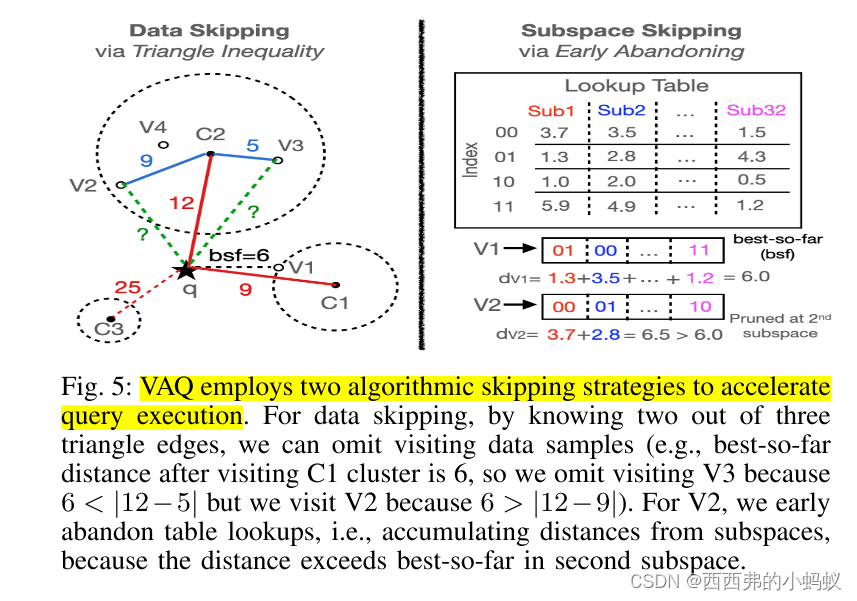
采用两种跳跃方式加速检索
Data Skipping
Subspace Skipping
EXPERIMENTAL SETTINGS


















 4344
4344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









