







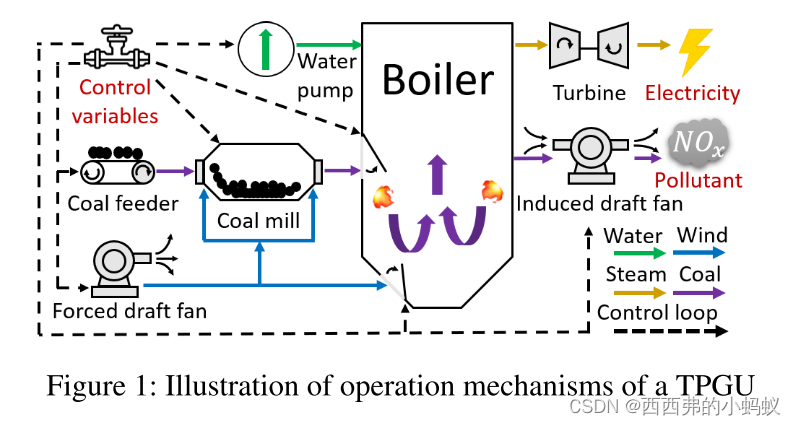
优化火力发电机组的燃烧效率是能源行业的一项具有高度挑战性和关键性的任务。我们开发了一个新的数据驱动的AI系统,即DeepThermal,以优化TPGUs的燃烧控制策略。其核心是一种新的基于模型的离线强化学习(RL)框架,称为MORE,该框架利用TGPU的历史运行数据,通过纯离线训练解决高度复杂的约束马尔可夫决策过程问题。在DeepThermal中,我们首先从离线数据集学习一个数据驱动的燃烧过程模拟器。然后结合真实历史数据和经过精心过滤处理的模拟数据,采用一种新的限制性勘探方案训练MORE的RL agent。DeepThermal已成功应用于中国四家大型燃煤热电厂。实验结果表明,DeepThermal能有效地提高TPGUs的燃烧效率。我们还通过在标准离线RL基准测试中与最先进的算法进行比较,报告了MORE的卓越性能
方法:
本文开发了一个新的数据驱动的人工智能系统DeepThermal(中文名称:深燧),以优化真实世界TPGUs的燃烧效率。DeepThermal构建了一个数据驱动的燃烧过程模拟器,以促进RL训练。DeepThermal的核心是一个新的基于模型的离线强化学习框架,称为MORE,它能够利用记录的数据集和不完美的模拟器来学习安全约束下的策略,并大大超越行为策略。DeepThermal已经成功部署在中国的四个大型燃煤热电厂。真实实验表明,DeepThermal提供的优化控制策略有效提高了TPGUs的燃烧效率。在标准离线强化学习基准上的广泛对比实验也表明,MORE比最先进的离线强化学习算法具有更优越的性能。
框架 :
本文将TPGUs的燃烧优化问题建模为一个约束马尔可夫决策过程(CMDP) (Altman 1999),它在标准MDP中增加了多个安全约束


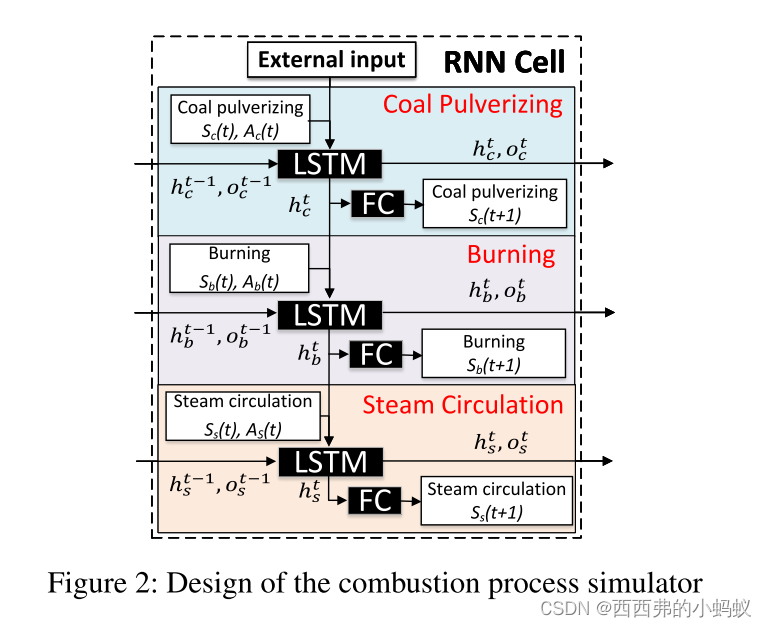

如图2所示,输入状态-动作对被分为3个块来编码它们的物理和层次依赖关系,长短期记忆(LSTM)层用于捕获时间相关性。
模拟器是通过最小化均方来学习的实际和预测状态的误差。为了进一步加强模拟器,应用了以下技术:1)Seq2seq和计划采样:我们使用序列到序列结构和计划采样(Bengio et al. 2015)来提高长期预测精度。2)噪声数据增强:在训练过程中,在状态输入上添加逐渐消失的高斯噪声,这可以被视为一种数据增强的方法。这有助于提高模型的鲁棒性,防止过拟合
MORE: An Improved Model-Based Offline RL Framework
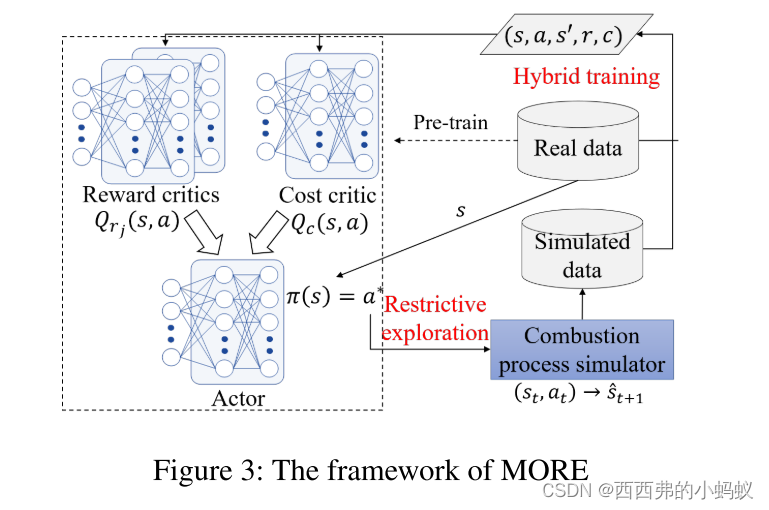
我们介绍了DeepThermal中使用的核心RL算法:基于模型的限制性探索离线RL (MORE)。MORE用一个不完美的模拟器解决了约束下离线政策学习的挑战。
MORE的框架如图3所示。它引入了一个额外的成本临界来建模并强制满足燃烧优化问题的安全约束。MORE使用一种新颖的限制性探索方案,从预测可靠性(通过模型灵敏度衡量)和作为OOD样本的可能性(通过行为数据中的数据密度衡量)的角度,量化了不完美模拟器带来的风险。具体来说,只有在确定输出时,MORE才信任模拟器,并对潜在OOD预测添加奖励惩罚,以进一步指导actor在高密度区域进行探索。最后,更巧妙地结合真实数据和仔细区分的模拟数据,通过混合训练过程来学习安全策略。
1)Restrictive Exploration
设计了一种新的限制性探索策略,从模型和数据角度充分利用模拟器的通用性。关键是只考虑模拟器确定的样本,然后进一步区分模拟样本是否处于数据分布。
2)Hybrid Training
在量化了不完美模拟器带来的风险后,MORE引入了一种混合训练策略,以区分从限制性探索中获得的正负模拟样本的影响。保留正样本的原始形式,以鼓励充分利用模型的泛化能力,但惩罚负样本的奖励,以引导策略学习远离高风险区域。
结论:
开发了DeepThermal,一种数据驱动的人工智能系统,用于优化TPGUs的燃烧控制策略。据作者所知,DeepThermal是第一个离线强化学习应用程序,已部署以解决现实世界的关键任务控制任务。DeepThermal的核心是一个新的基于模型的离线强化学习框架,称为MORE。更多的是在充分利用不完美模型的泛化能力和避免OOD样本的利用误差之间取得平衡。DeepThermal已成功部署在中国四家大型燃煤电厂。真实实验表明,DeepThermal有效提高了TPGUs的燃烧效率。在标准的离线强化学习基准上进行了广泛的比较实验,证明了MORE与最先进的离线强化学习算法相比的优越性能


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









