







Efficient and Effective Similar Subtrajectory Search with Deep Reinforcement Learning
摘要:相似轨迹搜索是一个基本问题,在过去的20年里已经得到了很好的研究。然而,类似的子轨迹搜索(SimSub)问题,目标是返回轨迹的一部分(即子轨迹),这是与查询轨迹最相似的,尽管它可以以一种更细粒度的方式捕获轨迹相似性,并且许多应用都以子轨迹作为分析的基本单元,但它在很大程度上被忽视了。在本文中,我们研究了SimSub问题,并开发了一套算法,包括精确算法和近似算法。在这些近似算法中,有两种基于深度强化学习的近似算法在有效性和效率上优于基于非学习的近似算法。在真实轨迹数据集上进行了实验,验证了所提算法的有效性和效率。
一.形式化定义:
1.轨迹。轨迹T的形式是时间戳的位置点序列(称为点),即T =< p1, p2,…, pn >,其中点PI = (xi, yi, ti)表示时刻ti的位置为(xi, yi)。轨迹T的大小,用|t |表示,对应于T的点数。
2. 相似Subtrajectory搜索 :Given a data trajectory T =< p1, p2, ..., pn > and a query trajectory Tq =< q1, q2, ..., qm >, the similar subtrajectory search (SimSub) problem is to find a subtrajectory of T, denoted by T[i∗, j∗] (1 ≤ i∗ ≤ j∗ ≤ n), which is the most similar to Tq according to a trajectory similarity measurement Θ(·, ·), i.e., [i∗, j∗] = arg max1≤i≤j≤n Θ(T[i, j], Tq).
二.算法
1. 非机器学习算法:
这一部分中,我们介绍了三种算法,即精确算法ExactS,近似算法SizeS,以及基于分割的算法PSS, POS和POS-D。ExactS算法基于穷尽的搜索,具有最高的复杂性,而SizeS算法受到了子序列匹配研究的启发,并提供了一个可调参数来控制效率和有效性之间的权衡,而基于分割的算法是基于分割数据轨迹的思想来构建子轨迹作为解的候选并运行最快。
1.1ExactS
ExactS算法列举数据轨迹T中所有可能的子轨迹T[i, j] (1 ij n),计算每个T[i, j]与Tq之间的相似度,即Θ(T[i, j], Tq),然后返回相似度最大的一个子轨迹。为了提高效率,ExactS尽可能以增量方式计算子轨迹和Tq之间的相似度,如下所示。它涉及n次迭代,在第i次迭代中,它按照结束点的升序计算从第i点开始的每个子轨迹与查询轨迹之间的相似性,即,首先计算Θ(T[i, i], Tq)(从头开始),然后计算Θ(T[i, i + 1], Tq),…, Θ(T[i, n], Tq)依次递增。在此过程中,它维护到目前为止所遍历的子轨迹中与查询最相似的子轨迹。可以验证的是,在n次迭代之后,它将遍历所有可能的子轨迹。考虑ExactS的时间复杂度。由于有n次迭代,每次迭代计算Θ(T[i, i], Tq)的时间复杂度为Φini,计算Θ(T[i, i + 1], Tq)的时间复杂度Φini,…, Θ(T[i, n], Tq)为O(n ·Φinc)。我们知道总的时间复杂度是O(n·(Φini + n·Φinc))。
我们注意到,对于某些特定的相似性度量,可能存在一些算法具有比ExactS更好的时间复杂度。例如Spring算法,它能找到一个数据时间序列与查询时间序列最相似的子序列,适用于SimSub问题,其时间复杂度为O(nm)。Spring的主要概念是一个动态规划过程,计算时间序列和查询数据之间的DTW距离, 后者用虚构的点,可以与任意点的数据时间序列与距离等于0(以覆盖所有可能的后缀的数据时间序列)。然而,Spring是为特定的相似性DTW而设计的,而ExactS是为抽象的DTW而设计的,可以实例化为任何相似性。
1.2.The SizeS Algorithm
ExactS探索了所有可能的n(n+1) /2个子轨迹,其中许多可能与查询轨迹非常不同,可以忽略。例如,根据已有的一些子序列匹配研究,我们可以将注意力限制在那些与查询的子轨迹大小相似的子轨迹上,以提高效率。具体来说,我们枚举所有大小在[m -ξ,m+ξ]范围内的子轨迹,其中ξ ∈[0, n- m]是一个预定义参数,用于控制算法的效率和有效性之间的权衡。对于从同一点出发的子轨迹与查询轨迹之间的相似度,我们再次采用增量计算策略。我们称该算法为SizeS,并对其时间复杂度O(Φini+(m−ξ−1)·Φinc+2ξ·Φinc)。总而言之,与ExactS相比,SizeS取得了更好的效率,但代价是其有效性。此外,SizeS还需要探索O(ξ·n)子轨迹,这限制了其仅适用于小数据集和中等数据集。不幸的是,size可能返回一个解决方案,这个方案比最好的方案差得多
1.3 Splitting-based Algorithms
ExactS算法的代价很高,因为它探索了O(n)个子轨迹。由于SizeS算法探索的是O(ξ·n)子轨迹.因此,提高效率的一个直观想法是探索更少的子轨迹。接下来,我们设计了一系列三种近似算法,它们都具有将数据轨迹分解为若干子轨迹并返回与查询轨迹最相似的一个子轨迹的思想。这些算法在使用不同的启发式来决定在哪里分割数据轨迹方面各不相同。使用这种分割策略,将被探索的子轨迹的数量以n为限,在实践中远远小于n。我们将这些算法描述如下
(1) Prefix-Suffix Search (PSS)
PSS算法是一种贪心算法,它维护一个变量Tbest来存储与查询轨迹最相似的子轨迹。具体来说,它按照p1, p2,…的顺序扫描数据轨迹T的点.当它扫描pi。如果T在点pi分割,它计算将要形成的两个子轨迹之间的相似度,比如T[h, i]和T[i, n],以及查询轨迹Tq,Ph是一个点后面的点,如果这种情况存在的话,最后一次分裂已经完成了,否则ph是第一个点p1。我们将计算后缀T[i, n]与查询轨迹之间的相似度的部分,替换为它们的反向版本之间的相似度。因为正向序列和反向序列,在DTW和Frechet等相似度测量中是相等的,而在t2vec等相似度测量中是正相关的。如果这两个相似点中的任何一个大于最佳的相似性,它在pi处执行拆分操作,并相应地更新Tbest;否则,它继续扫描下一个点pi+1。最后,它返回Tbest。
(2) Prefix-Only Search (POS).
(3) Prefix-Only Search with Delay (POS-D).
虽然这些基于分割的算法,包括PSS、POS和POS- d,在实践中返回了相当好的解决方案,但它们可能返回的解决方案比理论上的最佳解决方案差得多。
2. 基于强化学习的算法
基于分割的算法的有效性取决于数据轨迹分割过程的质量。为了找到高质量的解决方案,它需要在适当的点执行分割操作,以便形成一些类似于查询轨迹的子轨迹,然后进行探索。基于分割的三种算法:PSS、POS和POS- d,使用手工设计的启发式方法,用于决定是否在特定点执行分割操作。这种将轨迹分解为子轨迹的过程是一个典型的序列决策过程。具体来说,它顺序扫描这些点,对于每个点,它决定是否在该点上执行分割操作。在本文中,我们提出将此过程建模为马尔可夫决策过程(MDP),采用deep-Qnetwork (DQN)学习MDP的最优策略,然后开发一种称为基于强化学习的搜索(RLS)算法,对应于一种基于分割的算法,该算法使用学习到的策略来分割数据轨迹和一种RLS的扩充版本,称为RLS- skip,具有更好的效率
1.1 Trajectory Splitting as a MDP
MDP由四个组成部分组成,即状态、动作、转换和奖励,其中(1)状态捕获代理进行决策时所考虑的环境;(二)行为是代理人可能作出的决定;(3)过渡是指一旦采取行动,状态就从一种状态转变到另一种状态;(4)与转变相关的奖励,与一些反馈相对应,这些反馈表明导致转变的行为的质量。我们将分割数据轨迹的过程建模为MDP,如下所示。
(1)状态。我们用s表示状态。假设它当前扫描点pt。Ph表示一个点之后的点,如果有则发生最后一次分割操作,p1表示没有。我们将当前环境的状态定义为一个三元组(Θbest, Θpre, Θsuf),Θbest is the largest similarity between a subtrajectory found so far and the query trajectory Tq, Θpre is Θ(T[h, t], Tq) and Θsuf is Θ(T[t, n]R, TR)可以注意到,状态捕获关于查询轨迹、数据轨迹、最后一次分割发生的点和正在扫描的点等信息。注意状态空间是三维连续的。
2)行动。我们用a来表示一个动作。我们定义两个动作,即a = 1和a = 0。前者意味着在正在扫描的点上执行分割操作,后者意味着继续扫描下一个点。
(3)过渡。在分裂轨迹的过程中,给定当前状态和要采取的行动,我们观察到特定状态的概率是未知的。我们注意到,本文中我们用于求解MDP的方法是一种无模型的方法,即使在其转移信息未知的情况下也能求解MDP问题。
(4) Rewards. 我们用r来表示一个奖励。我们定义行动a之后,从状态s到状态s的转换相关的奖励为(s .Θbest s.Θbest),其中s.Θbest是状态s的第一个组成部分,s.Θbest是状态s的第一个组成部分。在这种奖励定义下,MDP问题的目标(即最大化累计奖励)与分割数据轨迹的过程一致,即形成与查询轨迹可能最大相似度的子轨迹。要看到这一点,请考虑该过程经历一系列状态s1、s2、…, sN,结束于sN。设r1 r2…, rN−1表示在这些状态下收到的奖励,然后,当未来回报不打折扣时,我们有Σtrt = Σt(st.Θbest − st−1.Θbest) = sN.Θbest − s1.Θbest。sN.Θbest对应所找到的最佳子轨迹与查询轨迹Tq和s1之间的相似度。Θbest对应于开头最广为人知的相似度
1.2 Deep-Q-Network (DQN) Learning
MDP的核心问题是寻找agent的最优策略,该策略对应于π函数,π函数指定agent在某一特定状态下应采取的行动,从而使累计收益最大化。一种常用的方法是基于价值的方法,主要思想如下。首先,它定义了一个最优行为价值函数Q(,)(或Q函数),代表预期的最大数量累计奖励将收到遵循任何policy在看到state和采取的行动。第二,它估计Q(,)使用一些方法如Q学习和deep-Q-network (DQN)。第三,它返回策略,该策略总是为给定的状态选择使Q (s, a)最大化的行为a。
在MDP中,状态空间是一个三维连续空间,因此我们采用DQN方法。具体来说,我们使用带重放记忆[22]的深度Q学习来学习Q函数。该方法维护两个神经网络。一个叫做主网络Q(s, a;θ),用于估计Q函数。另一种叫做目标网络Qˆ(s, a; θ−),用来计算训练主网络的某种形式的损耗。此外,它维护一个称为重放内存的固定大小的池,该池包含统一采样并用于训练主网络的最新转换。直觉是要避免连续转换之间的相关性。给出了在MDP中实现DQN的具体步骤
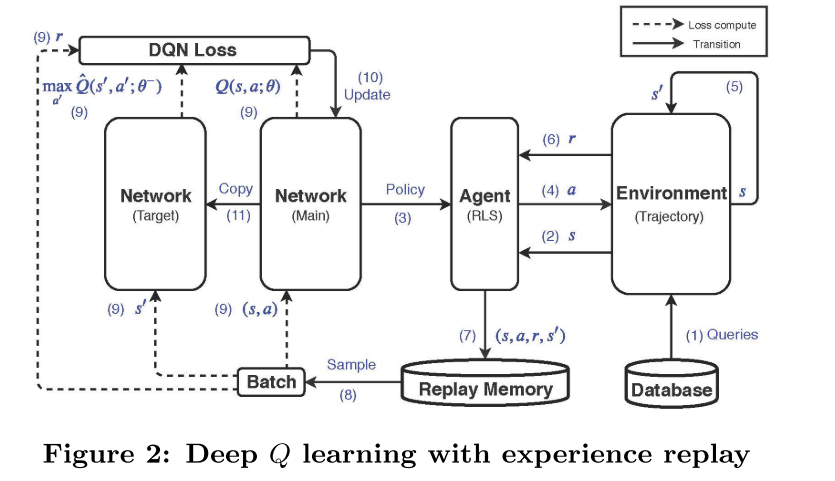
1).我们维护一个数据轨迹数据库D和一组查询轨迹Dq,它首先对应答内存M进行一定容量的初始化,主网络Q(s, a;θ),目标网络Qˆ(s, a; θ−)通过复制Q(s, a;θ)(第1 - 3行)。然后,它涉及到许多情节的序列。对于每一个事件,来自D,它的样本数据轨迹T 和来自Dq查询轨迹Tq ,都一致(4行5)。它初始化一个变量h, ph值对应于后的点,最后分割操作的执行是否和p1否则(第6行)。它还初始化状态s1(7 - 8行)。然后,它以|T|时间步长进行。在第t个时间步长,扫描pt点,采用基于主网络的-贪心策略选择一个动作,即在执行一个随机动作,其概率为 e和at = arg maxa Q(st, a;θ)的概率为(1)(第9 - 10行)。如果at = 1,它在点pt拆分轨迹,并更新h为t + 1(第11行13行)。如果可能的话,它会更新Θbest(第14行)。如果当前被扫描的点是最后一个pn点,它就终止(第15 - 17行)。否则,它观察一个新的状态st+1和奖励rt(第18 - 20行)。然后,它将体验(st, at, rt, st+1)存储在应答记忆中,并对一小批体验进行采样,使用它来执行梯度下降步骤
1.3 Reinforcement Learning based Search Algorithm (RLS)
一旦我们估计了Q函数Q(s, a;θ)通过具有经验重放的深度Q学习,我们采用在给定状态下总是采取使Q(s, a)最大化的动作的策略Q(s, a; θ),用于数据轨迹分裂过程。在该过程形成的所有子轨迹中,我们返回与查询轨迹Tq相似度最大的那一个。我们称这种算法为基于强化学习的搜索(RLS)。本质上,它与PSS相同,只是它使用了通过DQN学习的策略
RLS与PSS具有相同的时间复杂度,因为RLS和PSS都是根据扫描点时考虑的子轨迹的相似度和最著名的相似度来做决策的:(1) RLS构造了一个包含它们的状态,并将状态信息通过DQN的主网络,即O(1),考虑到网络规模较小(如只有几层);(2) PSS只是对相似点进行一些比较,也是O(1)。在有效性方面,RLS提供持续的解决方案比PSS和POS POSD,将实证研究中显示,原因可能是,RLS是基于学习策略,使决策更聪明比human-crafted简单的启发式方法。
1.4 Reinforcement Learning based Search with Skipping (RLS-Skip)
在RLS算法中,每个点都被认为是执行分割操作的候选点。虽然这有助于获得相当大的子轨迹空间来进行探索,从而获得良好的效果,但它在某种程度上是保守的,并导致了对每个点进行决策标记的一些成本。另一种选择是更乐观一点,跳过一些被认为是分割操作的地方。好处是立竿见影的,也就是说,在这些点上做决定的成本被节省了。基于此,我们提议增加RLS使用的MDP,引入k个操作(除了现有的两个操作:扫描下一个点并执行拆分操作),即跳过1个点,跳过2个点,…,跳过k个点。这里,k是一个超参数,通过跳过j个点(j = 1,2,…, k),表示跳过点pi+1, pi+2,…, pi+j,然后扫描点pi+j+1,其中pi是被扫描点。MDP的所有其他组件与RLS的组件保持一致。请注意,当k = 0时,这个MDP减少到RLS的原始MDP。我们将基于此增强MDP的算法称为RLS-Skip。
3.实验
3.1数据集。我们的实验是在三个真实的轨迹数据集上进行的。第一个数据集由波尔图表示,收集自葡萄牙波尔图1市,该数据集包含18个月的约170万条出租车轨迹,采样间隔为15秒,平均长度约为60秒。第二个数据集以哈尔滨为例,涉及中国哈尔滨市13000辆出租车8个月的约120万条轨迹,采样率不均匀,平均长度约120条。第三个数据集被称为Sports,涉及从STATS Sports 2中收集的约20万名足球运动员和球的轨迹,采样率为10次/秒,平均长度约为170。
3.2比较的方法。我们比较了基于RLS的搜索(RLS- skip)、基于RLS的带跳跃搜索(RLS- skip)和提出的基于非学习的算法(第4节),即ExactS、SizeS、PSS、POS和POS- d。对于RLS和RLSSkip,当采用t2vec时,根据实证结果,我们忽略了状态的Θsuf成分
3.3 评价指标。我们使用三个度量来评估一个近似算法的有效性。(1)近似比率(AR)(2) Mean Rank (MR): (3) Relative Rank (RR):
3.4 Experimental Results
(1)有效性的结果。我们从一个数据集中随机抽样10,000对轨迹,对于每对轨迹,我们使用一个轨迹作为查询轨迹,从另一个轨迹中搜索最相似的子轨迹。图3显示了结果。结果清楚地表明,RLS和RLSSkip算法在两组数据集上和三种轨迹相似度度量下,在这三种度量指标上始终优于其他所有非学习的近似算法。此外,RLS- skip算法的有效性略低于RLS算法,但仍优于非学习算法,因为它是基于学习策略进行决策的。
(2)效率的结果。我们通过在数据集中包含不同数量的轨迹来准备不同的数据轨迹数据库,并改变数据库中总点数。对于每个数据库,我们从数据集中随机抽取10个查询轨迹,为每个查询轨迹运行一个查询,以找到前50个相似的子轨迹,然后收集10个查询的平均运行时间。波尔图数据集上的运行时间结果如图4所示,其他数据集上的运行时间结果可以在技术报告中找到。RLS-Skip运行速度最快,因为在那些被跳过的点上,维护状态和做决策的成本被节省了。相比之下,其他算法都不会跳过点。ExactS的运行时间最长

(5)查询轨迹长度的影响。我们从一个数据集准备四组查询轨迹,即G1、G2、G3和G4,每组有10,000条轨迹,这样一组中的轨迹长度如下:G1 = [30, 45), G2 = [45, 60), G3 =[60, 75)和G4 =[75, 90)。然后,对于每个查询轨迹,我们从数据集准备一个数据轨迹。注意,对于查询轨迹和相应的数据轨迹,后者可能比前者长,也可能比前者短。对于每一组,我们报告平均结果。我们观察到,当查询长度增加时,除了size之外,所有算法的rr都保持稳定。对于大小,rr随查询长度的变化而波动。这是因为最相似的子轨迹的长度可能与查询轨迹的长度不相似
(11)训练时间。RLS和RLS- skip模型在不同数据集上的训练次数如表7所示。通常需要几个小时来训练RLS和RLS- skip的强化学习模型。RLS- skip的训练时间比RLS更短,因为我们使用相同数量的轨迹对和epoch来训练算法,并且RLS- skip的运行速度更快。
4结论
在本文中,我们研究了相似子轨迹搜索(SimSub)问题,并开发了一套算法,包括精确算法,近似算法,提供了一个可控制的效率和有效性之间的权衡,以及一些基于分割的算法,其中一些基于预定义的启发式,一些基于深度强化学习,称为RLS和RLS- skip。我们在真实的数据集上进行了大量的实验,验证了在近似算法中,基于学习的算法的有效性和效率是最好的















 1072
1072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









