









最近,由于其在数据科学和人工智能应用中的高维向量数据管理中的核心作用,最近邻搜索(nn)近年来引起了人们的快速兴趣。神经嵌入的成功激发了人们的兴趣,深度学习模型将非结构化数据转换为语义相关的特征向量,用于数据分析,例如推荐流行项目。在快速神经网络的几类方法中,基于图的近似最近邻搜索算法在广泛的真实世界数据集上取得了同类最佳的搜索性能。之前的工作主要是通过利用具有复杂启发式规则的图的结构来提高基于图的神经网络的搜索效率,而本文工作表明,基于图的神经网络的边访问的频率分布可能是高度倾斜的。这一发现导致了对利用查询分布在图遍历过程中修剪不必要的边以避免冗余计算的研究,这是基于图的神经网络的一个重要但尚未探索的方面。
将图剪枝表示为一个离散优化问题,并引入图优化算法GraSP,通过学习剪枝冗余边来提高相似图的搜索效率。GraSP使用概率模型增强现有的相似度图。然后,它执行一种新的子图采样和迭代精化优化,以显式地最大化搜索效率,当对大量训练查询集在图上删除期望中的边子集时。实验结果表明,GraSP持续提高了在真实数据集上的搜索效率,在不损失精度的情况下,搜索速度比现有方法提高了2.24倍。
背景:

例如,亚马逊[41]和阿里巴巴[56]等电子商务公司构建了基于语义的搜索引擎,将产品目录和搜索查询嵌入到高维向量中,并推荐嵌入与嵌入式搜索查询最接近的产品
为了提高搜索效率,现有方法通常利用图结构并结合启发式规则来构建相似图。例如,一些最先进的方法[25,36]通过迭代地向部分构造的图中添加节点来构建图 。在此过程中,现有方法通过添加多样化的边(例如,添加短程链接以创建密集连接的局部簇和连接这些簇的长程链接)和删除不必要的边(例如,使节点不超过预定义的出度上限)来改进图的可导航性
为了回答这个问题,我们将图修剪过程表述为一个离散优化问题,当从原始图中去除一个边子集时,该优化问题的目标是最大化大量训练查询的搜索效率。针对这一问题,提出了一种新的图优化最近邻搜索算法(GraSP: graph Sampling and Pruning),通过学习修剪冗余边,有效地提高了相似图的搜索效率。GraSP使用一种称为可退火相似度图(ASG)的概率模型来增强现有的相似度图。然后,GraSP执行一种新的子图采样和迭代细化方法,基于单个边的联合概率来学习重要的边,以最大化图上的精度和最小化期望的搜索复杂度。
3 OBSERVATIONS AND OPPORTUNITIES
1)Optimizing graphs based on heuristics?
首先,通过比较在图构建中应用不同启发式方法的ANN图进行分析。我们的目标是衡量某种启发式算法是否始终比其他算法更好。
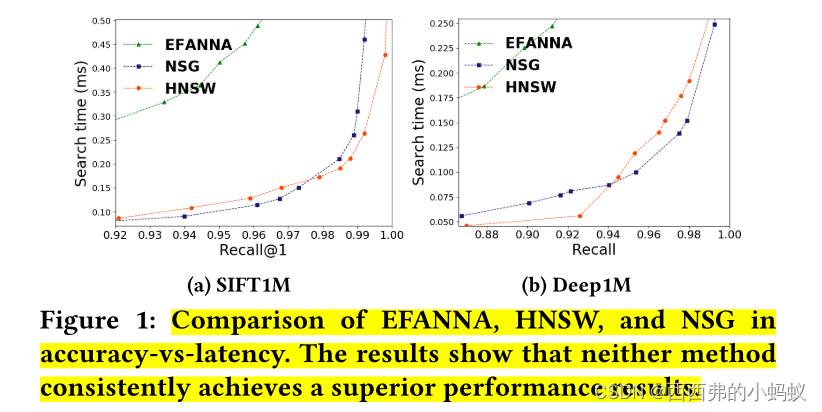
我们的假设是,由于HNSW和NSG在构建图时都没有显式地最大化在线搜索延迟-精度,因此图中可能存在冗余边,会对搜索效率产生负面影响。具体来说,不能帮助减少搜索路径长度的边会负向增加邻居检查的成本,因为它们创建了冗余计算。因此,这两种方法都没有在两个数据集上始终取得卓越的性能。本文推测,通过去除冗余计算,可以显著提高神经网络的搜索效率。
2)Highly skewed query distribution
我们的第二次分析测量了所有边的访问频率。目的是评估ANN图的负载平衡特性。我们从相应的学习集SIFT1M和Deep1M中随机采样100K向量作为查询。

大多数边只被访问一次,频率大致遵循指数衰减曲线,其中只有少数边被频繁访问。我们进一步发现,分布的偏斜是由一些中心节点(例如,深度较高的节点)比其他节点更有可能被访问造成的。
4 GraSP: LEARNING TO OPTIMIZE GRAPHS


Stage 1: Probabilistic graph construction.
首先,引入了一种新的概率模型,称为可退火相似图(ASG)(第4.1节),将图的每条边都关联到一个可学习的边概率,该概率表明是保留还是删除该边。这种新的表示允许将边缘连接细化作为一个优化问题,以最大化对大量训练查询的搜索效率。ASG可以定义在任何现有的相似图上,例如用现有的启发式方法构建的相似图,如HNSW[36]。
Stage 2: Learning edge importance via subgraph sampling and iterative refinement.
为了定量衡量不同查询的边重要性,将边重要性建模为图搜索效率对边去除的鲁棒性。这种策略允许我们定义一个反映搜索效率损失的目标函数,该目标函数由搜索诱导子图(𝐺' in 2.)的查询的距离误差来量化。a)和全图(G∗in 2。B)在搜索预算内。为了优化目标函数,引入了一种新的子图采样和迭代细化方法(2.c, 2.c)。在开始时,所有边的概率相等(这里的边权重没有信息)。在优化过程中,GraSP能够探索和利用边概率,并迭代优化边概率,以创建精细化子图的集合。
Stage 3: Final pruning.
在这一步中,我们选择一个小但关键的边集来形成最终的相似性图,并通过屏蔽它们来修剪剩余的边。最终的细化图可以用于回答查询。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









