







时间序列shapelets是一种具有短分辨性的子序列,近年来被发现在单变量时间序列的分类问题中不仅具有精确性,而且具有可解释性。然而,现有的关于shapelets选择的研究还不能应用于多变量时间序列分类(MTSC),因为MTSC的候选shapelets可能来自不同长度的变量,因此无法直接进行比较。为了解决这一问题,本文提出了一种新的ShapeNet模型,该模型将不同长度的shapelet候选者嵌入到一个统一的空间中进行shapelet选择。该网络采用聚类三组损失训练,考虑锚点与多个正(负)样本之间的距离和正(负)样本之间的距离,这对收敛很重要。我们计算具有代表性和多样化的最终shapelets,而不是直接使用所有的嵌入来建立模型,以避免大量的非歧视性候选shapelets。我们使用UEA MTS数据集在ShapeNet上用最先进的竞争和基准方法进行了实验。结果表明,ShapeNet算法的精度是所有方法中最好的。此外,我们通过两个案例研究说明了shapelets的可解释性。
背景:
与单变量时间序列分类(UTSC)相比,MTSC的研究受到的关注要少得多。
First, multivariate time series, of course, have multiple variables.
Second, shapelet candidates of different variables can beof different lengths, and such shapelets are hard to compare
Third, most existing studies take a black-box approach. Few methods provide interpretable results for understanding and explaining the classification.
框架
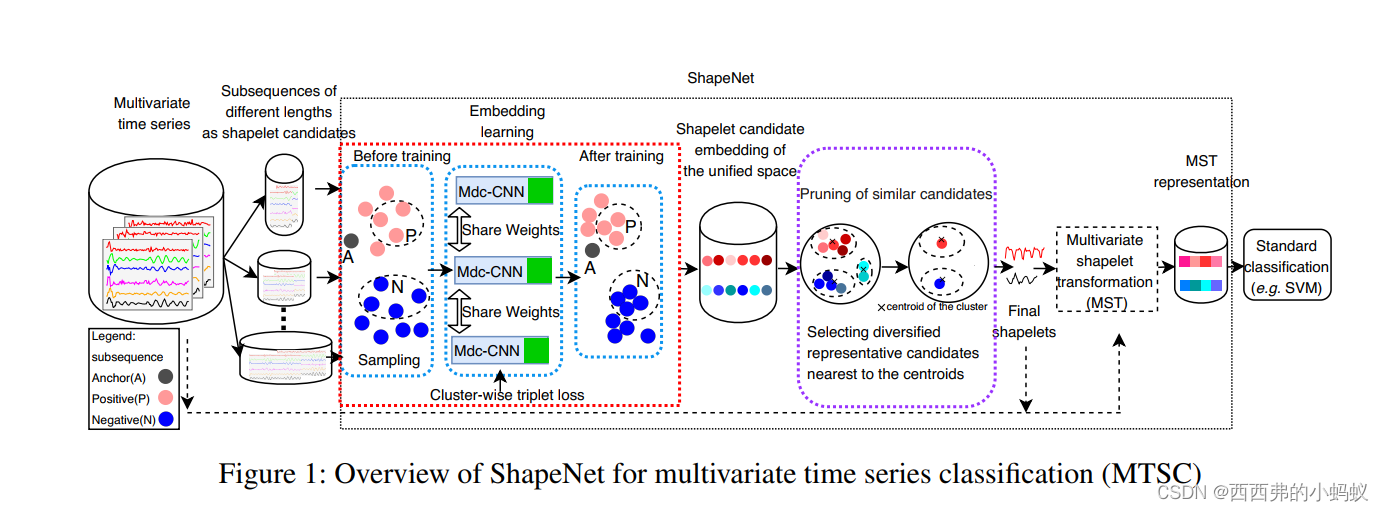
我们提出了一种形状-神经网络方法,即ShapeNet。具体地说,我们提出了多长度输入膨胀因果CNN,the cluster-wise triplet loss function, and multivariate shapelet transformation.
1)Multi-length-input Dilated Causal CNN(Mdc-CNN)
Shapelet候选序列最初都是不同长度的时间序列子序列。我们使用离散大小的滑动窗口(图1圆柱体中显示的数据)来生成候选对象。我们的目标是将所有的shapelet候选从原始空间嵌入到一个新的统一空间
首先,利用扩张的因果卷积神经网络(Dc-CNN) (Van Den Oord and Dieleman 2016)学习一种新的时间序列子序列表示
第二,虽然输出可以和输入相同的长度,但是Dc-CNN不能处理各种长度的输入。因此,我们建议引入一个全局最大池化层和一个线性层,叠加在最后一个DcCNN层之上,将所有shapelet候选对象嵌入到统一空间(如图1中的绿框所示),我们称之为Multi-length-input Dilated因果CNN (Multi-length-input Dilated因果CNN, Mdc-CNN)。
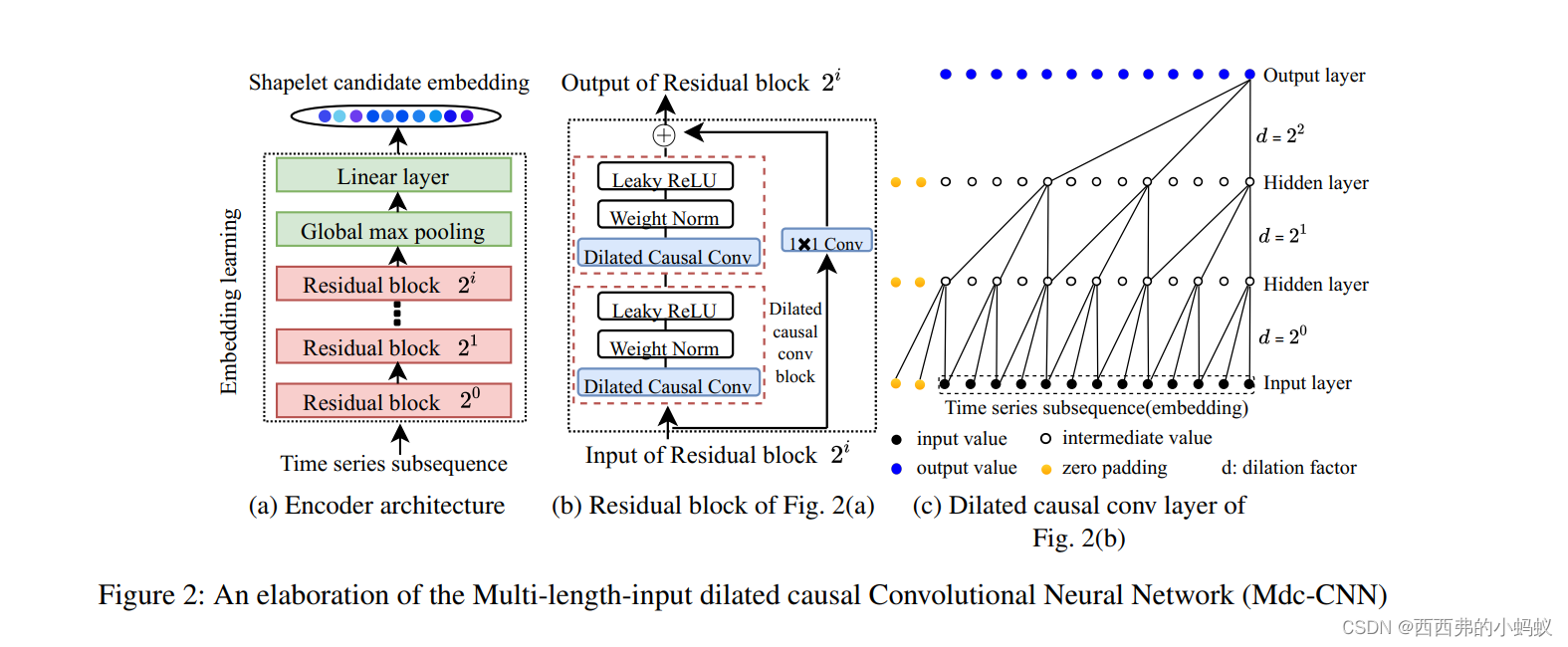
Mdc-CNN架构。Mdc-CNN进一步说明图2。图2(a)显示编码器有i + 1层剩余块。
编码器的输入是各种长度和变量的时间序列子序列,输出是它们的统一表示。我们称输出为shapelet候选嵌入。图2(b)给出了由两个相同的子块和一个扩张的因果卷积块组成的剩余块。图2(c)给出了一个带有膨胀因子的扩张因果卷积示例
2)Unsupervised Representation Learning
2.1) Cluster-wise triplet loss function.
在本文中,我们提出了一个以多个正样本和负样本以及正(负)样本之间的距离作为输入的簇级三组损失函数。为了简单起见,我们使用两个集群来演示我们的损失函数。具体来说,训练集T中所有可能的三胞胎的集合定义如下
 在一些真实的数据集中,三元组的数量(x;x+;x−)很大,使用所有三元组进行训练在计算上是不允许的,而且是次优的。相反,我们进行三重采样。
在一些真实的数据集中,三元组的数量(x;x+;x−)很大,使用所有三元组进行训练在计算上是不允许的,而且是次优的。相反,我们进行三重采样。


考虑正负样本内部之间额距离

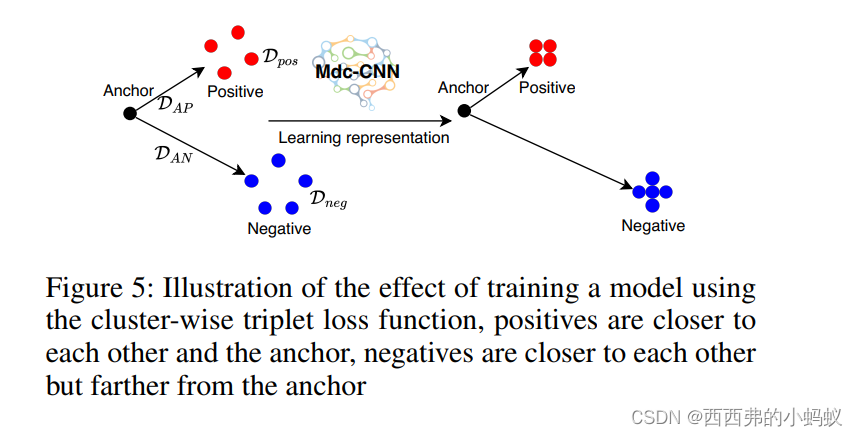
图5说明了Eq. 7。本例中展示了我们的集群级三联体损失的两个集群。三重态损失函数既使锚点与所有正样本之间的距离最小,又使所有正(负)样本之间的距离最小,又使锚点(正)与所有负样本之间的距离最大。(相同样本之间距离最小,不同样本之间距离最大)
3)
Multivariate Shapelet Transformation
在确定了shapelets候选结果的统一表示后,我们建议选择高质量、多样化的候选结果作为最终的shapelets。最后,我们对MTS采用shapelet变换的方法,然后应用一个经典的分类器来解决MTSC问题。
3.1)Determining final shapelets.
所有的候选人被嵌入一个统一的空间。它允许我们简单地使用一种聚类方法(例如,kmeans)来获得Y簇的shapelet候选。我们提出一个效用(公式8)来对候选人进行排名,使他们离cluster最近。式8的第一个分量是候选簇的大小。一个大的集群意味着它代表许多候选者。第二部分是与其他地区候选人的距离。距离大说明候选人和其他人不一样
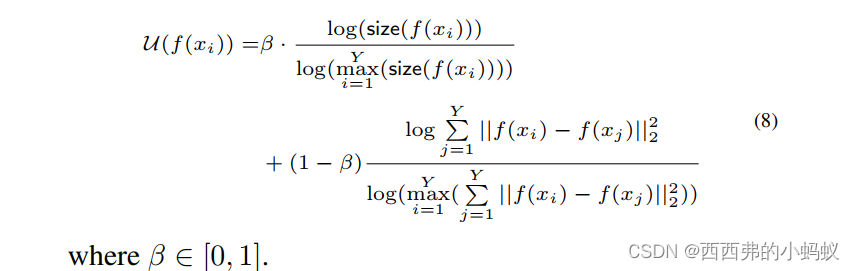

3.2. )Multivariate Shapelet Transformation

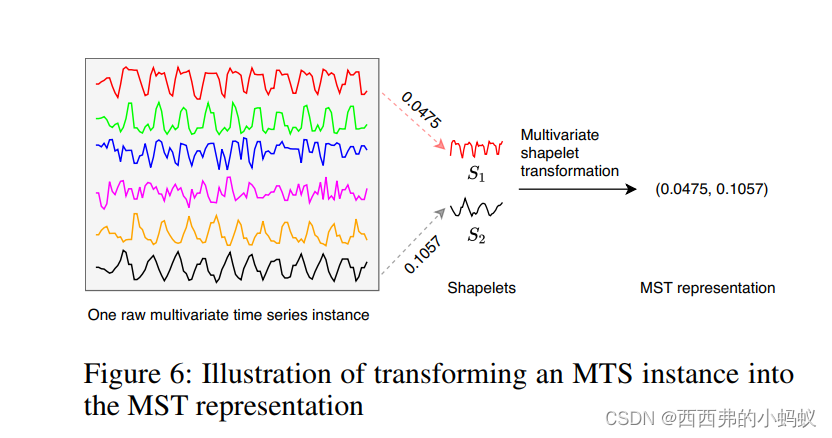
当所有MTS实例的转换完成后,可以利用一些标准的分类器(如SVM)从转换后的表示中学习分类模型。在本文中,我们采用具有线性核的支持向量机,这样我们就可以观察到shapelets的权重来进行分类。
4Experiments
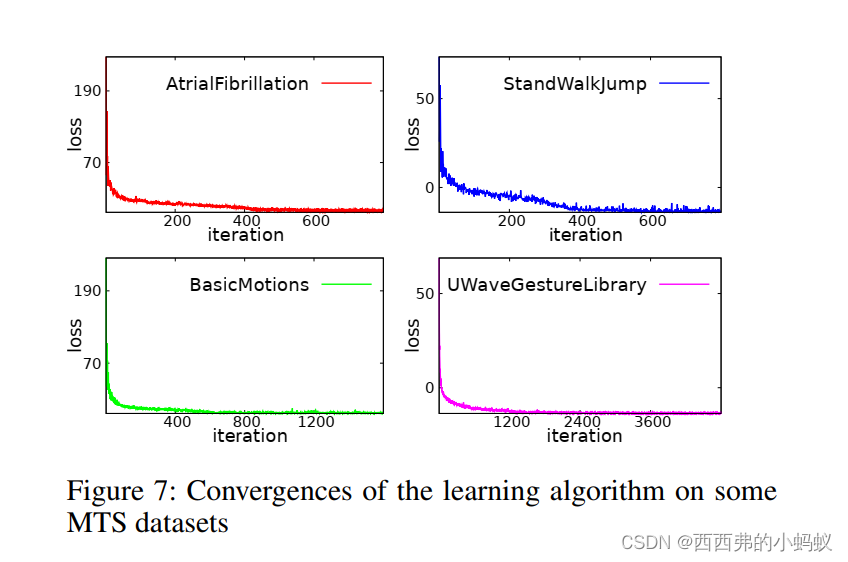
4.1Convergence of Mdc-CNN
我们验证了Mdc-CNN的收敛性,它依赖于Section的参数。当训练在所有四个数据集上进行时,所有的损失都非常平稳地收敛。我们还可以观察到,损失在开始时迅速收敛,然后稳定下来。从其他数据集中也可以观察到类似的趋势。这验证了我们的簇级三联损耗的有效性。
4.2 Comparison with other methods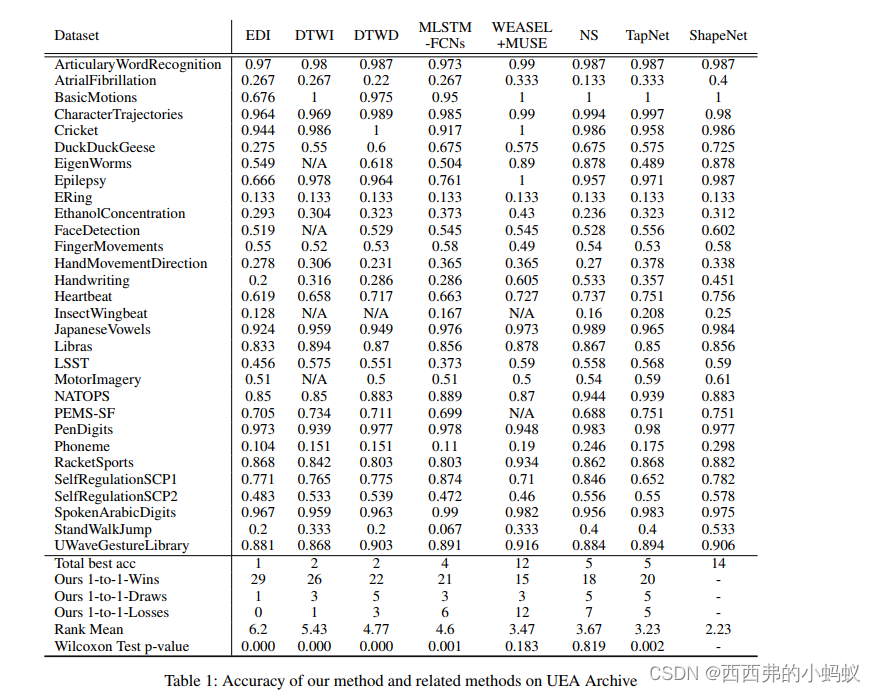
从表1中,我们可以观察到 ShapeNet是所有方法中最好的
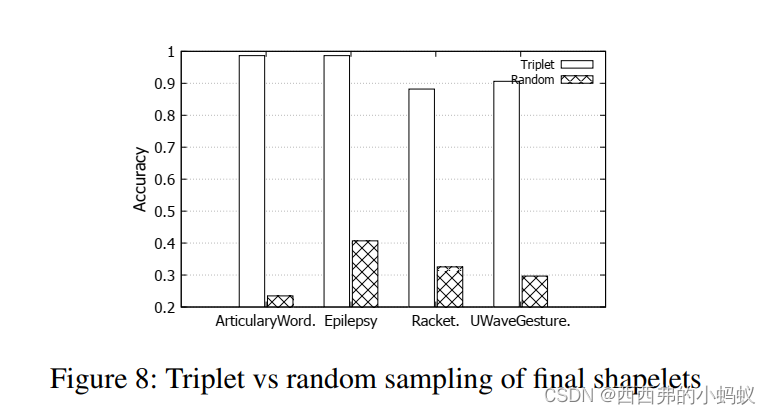
4.3)Triplet sampling vs. random sampling
为了研究三元组抽样的性能,我们与随机三元组抽样进行了比较,以训练网络
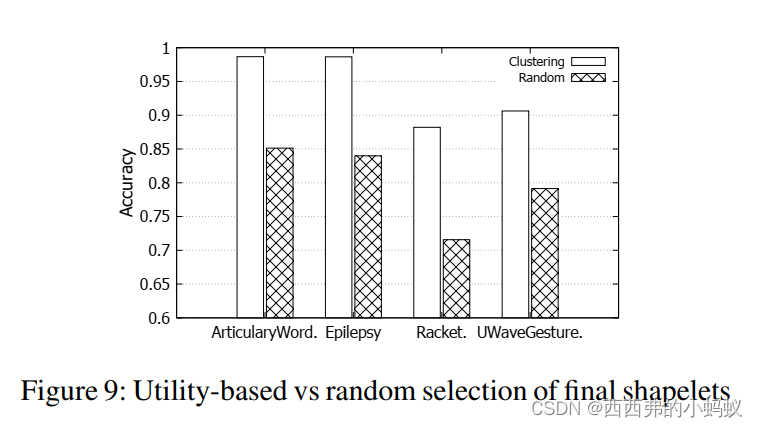
4.4)Utility-based vs. random selection
为了研究效用函数在Section中选择最终shapelets的有效性,我们进行了一个实验,将其与随机选择进行比较。聚类数为200,k取值为50。随机选择数是50。 在这四个数据集中,基于效用的方法的准确性明显优于随机选择方法,显示了其在发现高质量shapelets方面的优越性。
4.5)Varying shapelet numbers
在这四个数据集中,基于效用的方法的准确性明显优于随机选择方法,显示了其在发现高质量shapelets方面的优越性。
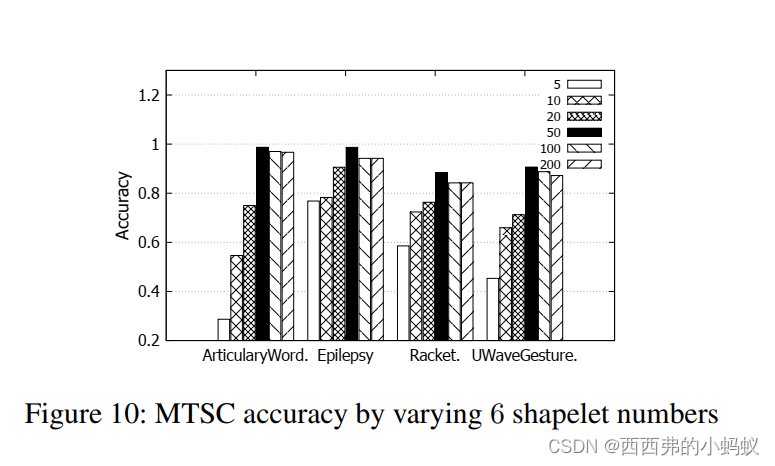
在所有四个数据集中,随着shapelets数量从5增加到50,准确率迅速提高,然后略有下降
4.6)Experiments on Interpretability
我们进一步研究了shapelets可解释性,这是基于shapelets方法的一大优势。我们报告了由ShapeNet从两个数据集生成的两个shapelets(即k = 2)。之所以选择这些数据集,只是因为它们可以在不需要太多领域知识的情况下呈现
4.6.1)Interpreting Basicmotions’ shapelets
从图11中的basicmotion数据集(最左边的图)中发现了两个有趣的shapelets, S1和S2。S1描述x轴的加速度,S2描述z轴的角速度。The shapelets selected by ShapeNet are from the first and fifth variables。
中间的图显示了来自数据集的四类的四个多元时间序列。不同的颜色表示不同的变量。同一变量的时间序列(视觉上相同颜色)之间的距离只能计算。到两个shapelets的距离将多元时间序列投影到一个二维空间(最右边的图)。然后,利用线性分类器对变换后的表示进行分类。结果表明,S2是区分羽毛球运动的有效方法。S1能区分走和跑。最后,S1和S2都可以识别stand from others
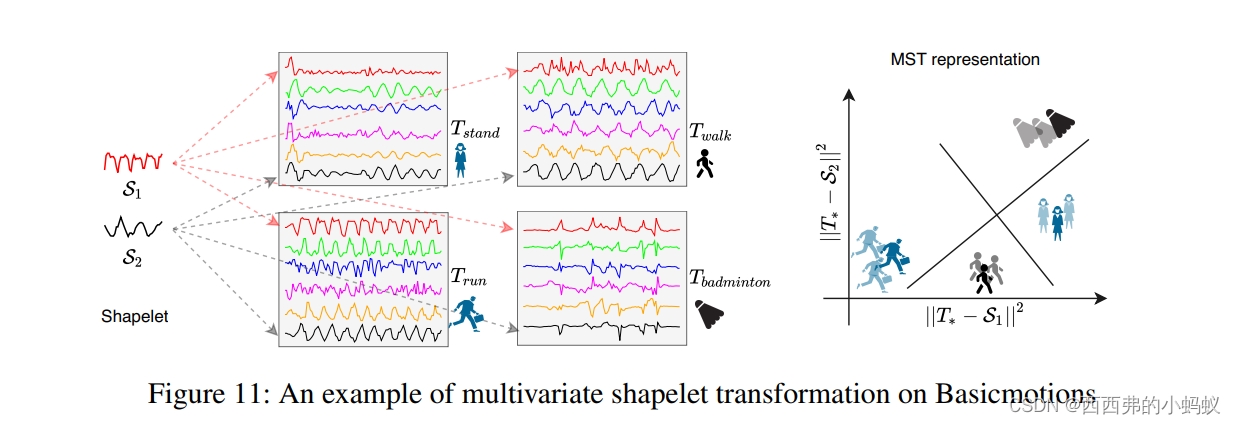
我们注意到,MST表示w.r.t shapelets比原始数据更容易解释,并且可以观察到一些知识。例如,站立和羽毛球是类似的w.r.t S1,这是反直觉的。原来,在等羽毛球的时候,很多选手只是站着
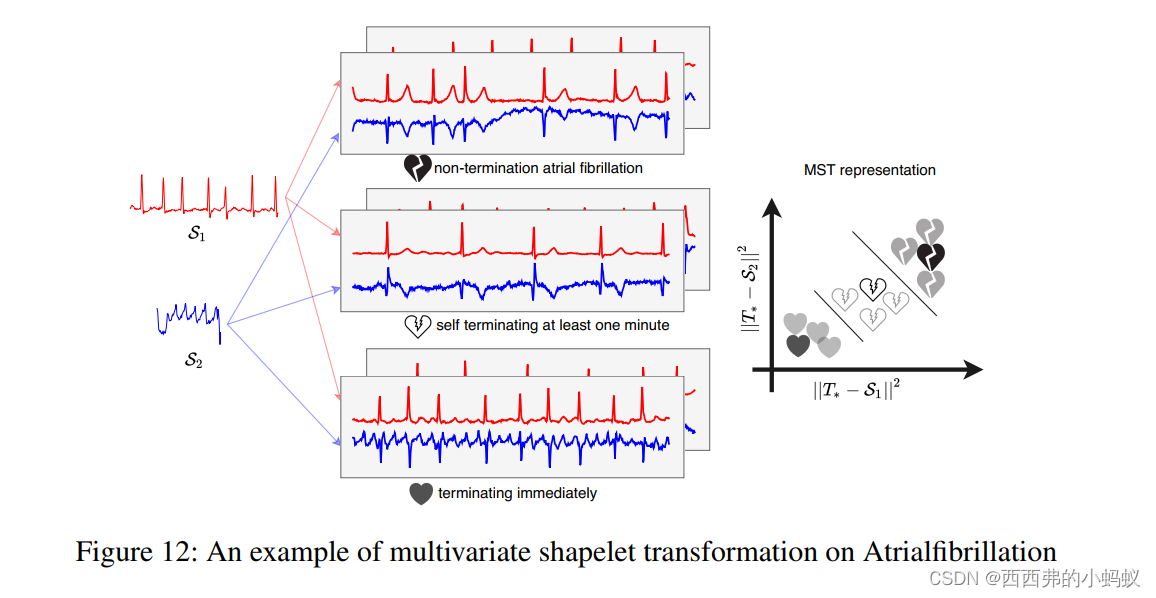
4.6.2)Interpreting AtrialFibrillation’s shapelets
 结论:
结论:
本文提出了一种用于MTSC的新型形状神经网络方法——ShapeNet。我们提出Mdc-CNN在统一空间学习不同长度的时间序列子序列,并提出一种簇级的三元组损失以一种无监督的方式训练网络。我们采用MST方法得到时间序列的MST表示。转换后,我们使用带线性核的SVM进行分类。实验结果表明,该方法的分类精度优于7种比较方法。该学习算法收敛速度快,效用函数有效。为了获得最高的精度,可以将shapelets的数量设置为50(默认)。通过两个案例研究说明了shapelets的可解释性。至于未来的工作,我们计划研究缺失值的MTS,这对现实世界的数据集是一个挑战
总结:这篇论文 从学习shaplets的方法实现多元时间序列分类任务,这是一个有趣的工作。当然它主要基于embedding的方式学习到shapelets, 这点在学习shapelets方面具有创新点。在KDD2014年的shapelets学习论文中是基于传统机器学习的方法,采用优化方式学习到shapelets,但是这种学习方法是基于单元时间序列地,其次在2019年的ICDE 上提到学习shapelets,它主要采用传统的基于符号特征的方式 PAA/SAX-based的方式,相当于词表示的方式。但是这种方式也是针对单元时间序列的。该作者在TKDE2021上提出基于shapelets的单元时间序列分类算法。
总之:创新点1)在多元时间序列shapelets学习场景中,2)考虑了一种三元组损失的方式















 2101
2101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









