










CIVET: Exploring Compact Index for Variable-Length Subsequence Matching on Time Series VLDB 2024
如今,管理和分析大幅增加的时间序列集合的需求变得越来越具有挑战性。子序列匹配作为时间序列分析的核心子程序,引起了研究的广泛关注。以前的大多数工作只关注匹配与查询长度相等的子序列。但是,许多方案需要支持有效的可变长度子序列匹配。在本文中,我们提出了一种新的表示形式,即均匀分段聚合近似 (UPAA),它能够对齐可变长度时间序列的特征,同时保持下边界属性。基于UPAA,我们通过分别对相邻子序列和相似子序列进行分组,提出了一个紧凑的索引结构。此外,我们提出了一种索引剪枝算法和数据甩动策略,以有效地支持可变长度子序列匹配而不会产生错误解雇。在真实数据集和合成数据集上进行的实验表明,我们的方法比现有方法实现了更好的效率、可扩展性和有效性。
一 框架
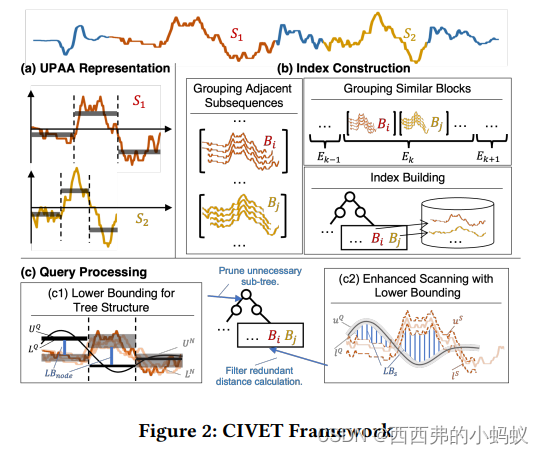
二 算法流程
下面简单的总结下论文的算法思想:
这篇论文处理了可变长的时间子序列相似性查询(匹配)。即查询序列(Q)和被查序列(time series)之间不用等长,那么返回的结果也不用和查询序列等长。论文设计思路很清晰,首先处理不等长问题,其次进行时间序列表征,然后构建查询树,最后实现KN和topk查询。
1)处理不等长序列:文中考虑的是统一缩放(uniform scale), 即将查询序列缩放成和被查询序列等长的序列,然后进行后续处理。文中采用uniform scale和 z-normal的方法,文中提到的uniform scale是按照被查序列实现的,那么对query 实现缩放代价会不会有点大。

2) 序列摘要:文中提出了一种Uniform PAA,这是一种PAA的变体,核心想法是将原来的PAA中固定段长,变成只固定段数,这样能够实现在不同情况下的动态分段,然后使用均值等统计特征表示该段。


A: Lower Bound for a Set of Time Series
我们需要估计查询序列和一组变长子序列之间的距离。这部分容易理解,简单概括:找到查询序列中的上下界QU 和QL ,具体就是查询序列被摘要后的最大和最小均值。然后找到序列集合中的上下界SU 和SL,然后比较上面这两组上下界的大小关系(跳过)
3) 索引构建

们提出我们的紧凑index。我们提供了两种技术,分别称为块汇总(第 4.1 节)和包络汇总(第 4.2 节)来压缩子序列的冗余信息。然后,我们描述了构建 CIVET 索引的过程(第 4.3 节)。
A Grouping Adjacent Subsequence

1)文中提到要把subsequence看成 在二维空间中的点,但是论文中没有提到这些子序列怎么投影到二维空间中,它的分布如何,按照后面的实验和紧致压缩index 的说法,这个关键的环节,在这里论文中没有提到,并且实验部分也没有体现分布情况。
2)论文中按照w和h的参数分割二维空间,然后找到分割块的上下界

3)为了实现紧致的块表示,实现了InvSAX for block summarization 将位置相邻的块放置在一起。

4)进一步在滑动窗口上使用包络
到此 论文之前的工作都是实现序列的表征处理,主要实现紧致表征,采用块和envlope的方法。
5) Index Building

文中是基于iSAX这种树实现索引创建的,具体的创建过程参考iSAX树实现,但是有两点可以看出:1)CIVET index不是一个平衡树,2)CIVET index中可能存在一些空节点,即节点中装载的序列是不均衡分布。这两点可能导致查询性能没有预期的好。
6)QUERY PROCESSING
这部分主要是剪枝处理了,Lower Bounding for Envelope and Node,具体的上下界计算跳过
7)Search Algorithm
利用上一小节中的下边界距离来修剪不必要的子树,并指示树节点的访问顺序,这支持了有效的近似搜索。然后,我们用精确的搜索程序来提炼结果。主要实现KNN 和topk的查询。两个过程,首先近似查询 找到一个候选对象集合,然后在精确查询,验证候选集合,找到最后的结果。
 三实验部分
三实验部分
1)数据集:是百万级的序列点,但是文中没有提到数据量的大小,只是序列长度。

2)实验方法
ULISSE 和UCR序列

文中也提到UCR系列是非索引方法,因此主要关注了ULISS方法,ULISS方法是fix length query。文中对比的算法不全面,有点少。子序列匹配算法有常规的FAST ,GeneralDual, KVmatch, DSTree, Dumpy等,但是论文仅比较了ULISS,有点遗憾。
3)W和H
1)这个很直观 w和h影响查询时间,和索引大小,w和h越大 索引越小,但是论文中没有比较改变w和h对recall的影响。从不同的数据上查询时间看的出来,w和h的设定对数据不是稳定的,也就是说对不同的数据集找打合适的w和h可能比较难。
4)

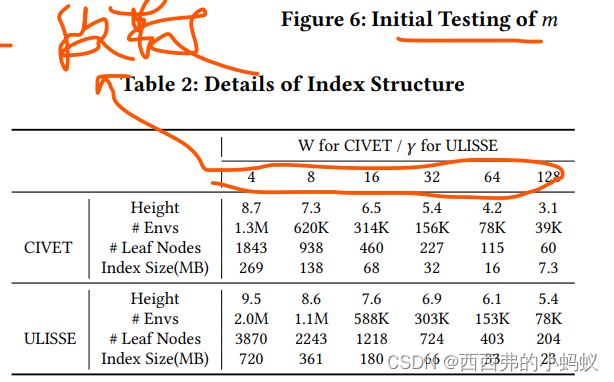
从表中看出 在树高,env, 叶节点数量和索引大小上 都比ULISS高
5) 扩展性

看出 CIVT的索引创建时间比ULISS要慢,要做大量的上下界计算。
实验总结:从查询时间,recall ,剪枝效率上 CIVT比 ULISS效果好。这些索引和查询效果的基础来自文中采用了多种紧致表征的方法,其次是剪枝方法,这些可能是很关键的点。整体读下来,感觉实验部分不是很充足,但是整体思路和算法说明上很清晰,这点值得学习,细节的具体实现还是要代码。















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









