







FlowNet(光流神经网络)主要有两个版本:
FlowNet: Learning Optical Flow with Convolutional Networks
FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks
一、光流
什么是光流?
图 1
如图 1 所示,简单来说, 是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法
光流可视化:
图 2
如图 2 所示即为光流的可视化,左边图片中每个像素都有一个x方向和y方向的位移,右图是通过计算得到的光流flow,是个和原来图像大小相等的双通道图像。不同颜色表示不同的运动方向,深浅表示运动的速度。

二、论文细节
1、网络结构
图 3
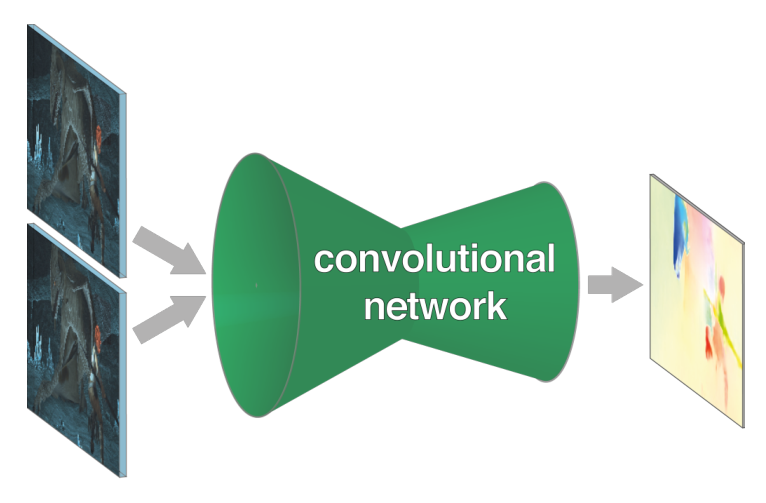
如图 3 所示就是FlowNet神经网络的大体思路。
输入为两张图像,他们分别是第 t 帧以及第 t+1 帧的图像
它们首先通过一个由卷积层组成的收缩部分,用以提取各自的特征图
但是这样会使图片缩小,因此需要再通过一个扩大层,将其扩展到原图大小,进行光流预测
1)收缩部分网络结构
图 4
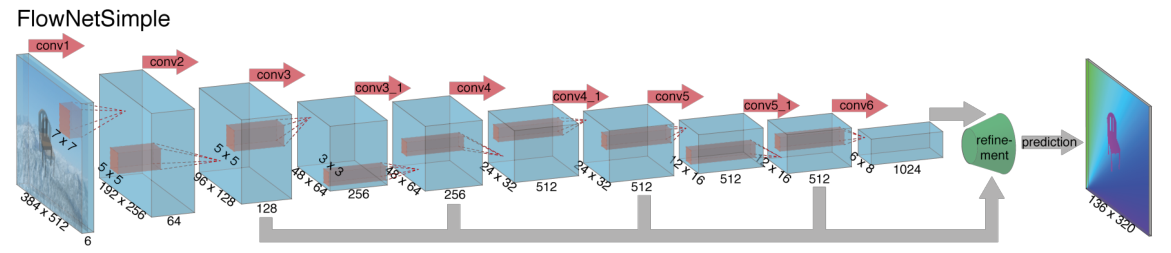
第一种方案:直接将输入的一对图片叠加在一起,让它们通过一系列只有卷积层的网络,我们称之为 FlowNetSimple。
图 5
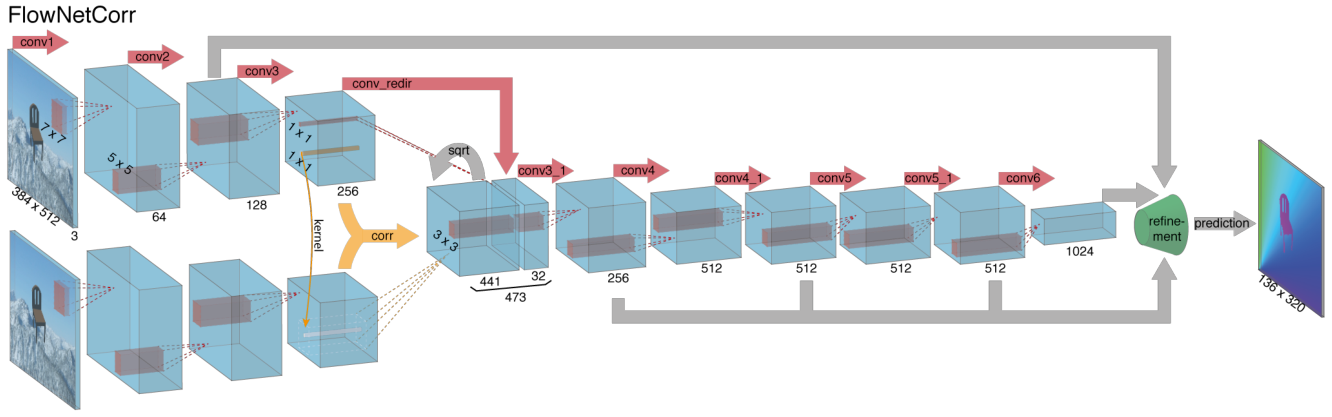
第二种方案:将一对图片分开处理,分别进入卷积层提取各自的特征,然后再对它们的特征进行匹配,寻找它们之间的联系,我们称之为 FlowNetCorr。
图 5 中黄色箭头所示即为比较两个特征图的操作。我们举例说明,设两个特征图分别为f1和f2,它们都为w*h*c的维度,即宽度为w,高度为h,通道数为c,比如以x1为中心的一块和以x2为中心的一块,它们之间的联系用以下公式计算,假设块长为K= 2k+1,大小为 K*K
这一公式与神经网络的卷积操作是一样的,只不过普通的卷积是与filter(卷积核)进行卷积,而这个是两个块进行卷积,所以它没有可以训练的权重。
计算这两块之间的联系计算复杂度是 c * K * K,而f1上每个块都要与f2上所有块计算联系,f1上有w * h个块(每个像素点都可以做一个块的中心点),f2上也有w * h个块,所有整个计算复杂度是c * K * K * ( w * h) * ( w * h),这里是假设每个块在下一张图上时,可以移动任何位置。但是这样计算复杂度太高了,所以我们可以约束位移范围为d(上下左右移动d),就是每个块只和它附近D: 2d+1的位置块计算联系,而且还可以加上步长。
2)放大部分网络结构
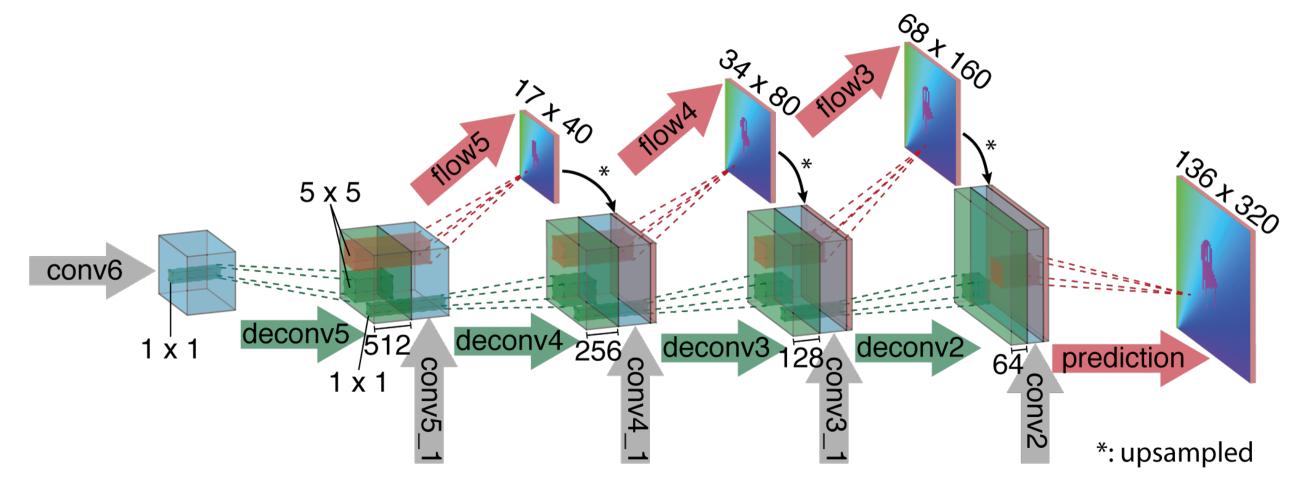
图 6
这里的放大部分主要由逆卷积层(upconvolutional layer)组成,而上卷积层又由逆池化层(unpooling,与pooling操作相反,用来扩大feature map)和一个卷积层组成。
我们对 feature maps 执行逆卷积操作(绿色箭头 deconv5),并且把它和之前收缩部分对应的feature map(灰色箭头 conv5_1)以及一个上采样的的光流预测(红色箭头 flow5)链接起来。每一步提升两倍的分辨率,重复四次,预测出来的光流的分辨率依然比输入图片的分辨率要小四倍。论文中说在这个分辨率时再接着进行双线性上采样的 refinement 已经没有显著的提高,所以采用优化方式:the variational approach。
2、数据集
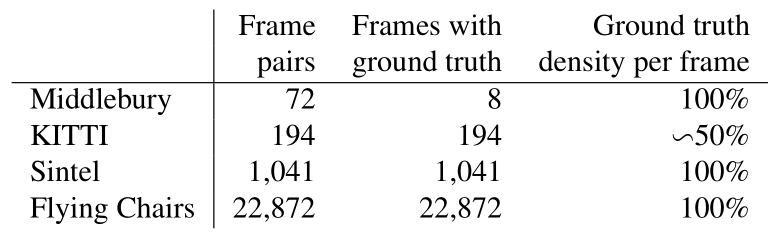
表 1
FlowNet主要使用了四种数据集,如表 1 所示
1)Middlebury数据集
用于训练的图片对只有8对,从图片对中提取出的,用于训练光流的 ground truth 用四种不同的技术生成,位移很小,通常小于10个像素。
2)Kitti数据集
有194个用于训练的图片对,但只有一种特殊的动作类型,并且位移很大,视频使用一个摄像头和 ground truth 由3D激光扫描器得出,远距离的物体,如天空没法被捕捉,导致他的光流 ground truth 比较稀疏。
3)Mpi sintel数据集
是从人工生成的动画sintel中提取训练需要的光流 ground truth,是目前最大的数据集,每一个版本都包含1041个可一用来训练的图片对,提供的gt十分密集,大幅度,小幅度的运动都包含。
sintel数据集包括两种版本:
sintel final:包括运动模糊和一些环境氛围特效,如雾等。
sintel clean:没有上述final的特效。4)Flying Chairs数据集
用于训练大规模的cnns,sintel的dataset依然不够大,所以作者他们自己弄出来一个flying chairs数据集。
 图 7
图 7
如图 7 所示,这一数据集背景是来自flickr的图片,剪切成四分之一,用512*384作为背景,前景是生成的3d椅子模型,从这些模型中去掉一些相似的椅子模型,留下809种椅子,每一种有62个视角。
为了产生运动信息,产生第一张图片的时候会随机产生一个位移变量,与背景图片与椅子位移相关, 再通过这种位移变量产生第二个图片和光流。每一个图像对的这些变量,包括,椅子的类型,数量,大小,和产生的位置都是随机的,位移向量也是随机的产生的。尽管flying-chair数据集已经很大,但是为了避免过拟合,而采用了data Augmentation 的方法,让数据扩大,样式变多,不单调,防止分类变得严格。
5)Flying Things3D 数据集
图 8
在 FlowNet2.0 中,又生成并引入了另外一个数据集 Flying Things3D ,如图 8 所示,由一堆会飞的三维图形组成,更加接近于现实,有22000对图像。
3、训练策略
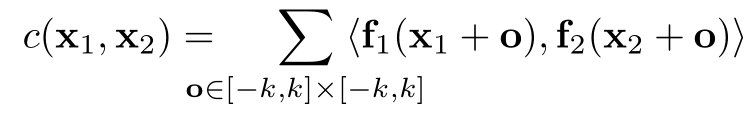

相对于 FlowNet,FlowNet 2.0 主要改变的是训练策略
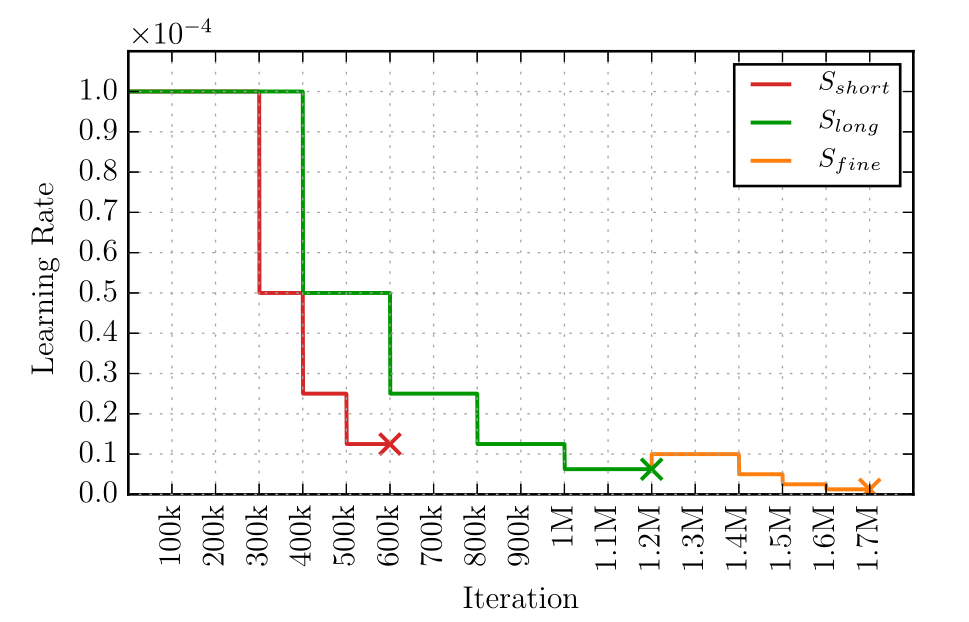
图 9
如图 9 所示为神经网络训练过程中的学习率(Learning Rate)随着迭代次数(Iteration)的衰减策略
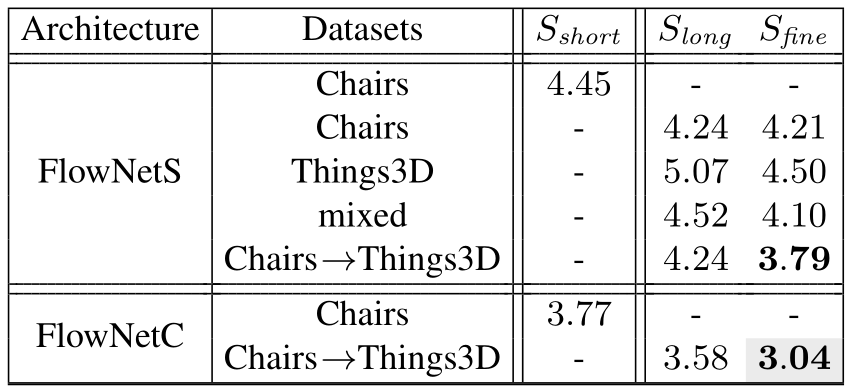
表 2
表 2 所示为 FlowNet 使用不同的训练策略以及不同的数据集顺序得到的实验结果,其中的数字表示的是 EPE(End Point Error),这种评估方式是将所有像素点的 gound truth 和预测出来的光流之间的差别距离(欧氏距离)的平均值,EPE 越低越好。
从表中可以看出,先使用Chairs这样简单的数据集然后再使用Things3D 这样复杂的数据集,可以得到比两个数据集一起 mixed 训练更好的结果。
网络的堆叠(Stacking NetWorks)
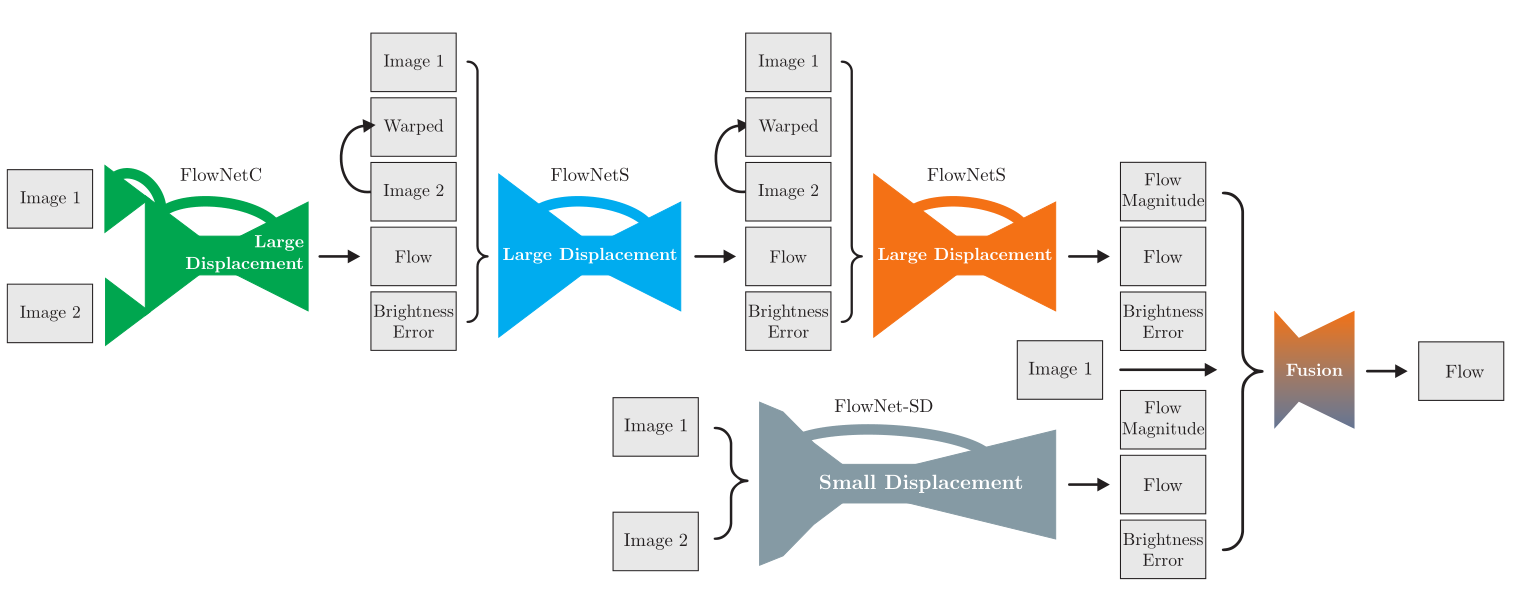
图 10
图 10 所示为 FlowNet 2.0 的大体框架
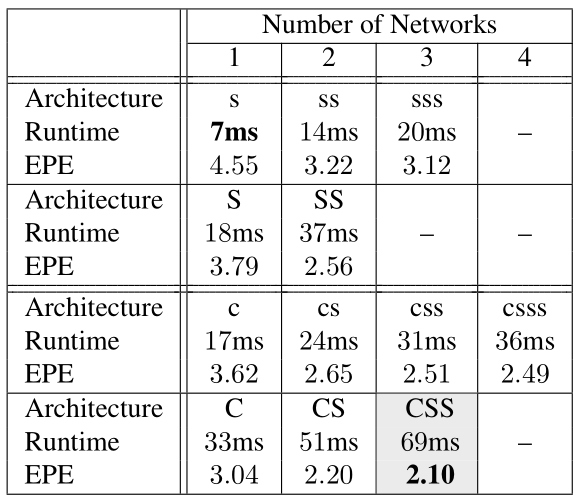
表 3
论文在这里除了引入FlowNetS,FlowNetC,还引入了每层只有3/8个通道的FlowNetc和FlowNets以小写的s和c表示,3/8是因为当通道数为3/8时,EPE和通过网络所需时间达成一个较好的平衡。这里的训练都是用Chairs->Things3D的方法,且网络按照one-by-one的设置训练。
实验设置及结果见表 3,CSS表示1个FlowNetC + 2个FlowNetS,其他以此类推,由此可见,两个小网络在一起,虽然他们的参数更少,但是效果好于一个大网络。
Small Displacement
上面使用的Chairs 及Things3D 数据集相对真实场景的变动较大,所以训练的效果在实际应用时并不太好,所以作者就重新做了一个数据集,叫作ChairsSDHom, 使用 FlowNet2-CSS 在 ChairsSDHom 及 Sintel 上 finetune 得到 FlowNet-Css-ft-sd , finetune时对 small displacement 的loss权重加强,效果在微变物体上表现变好,变化大的物体的效果也还不错,但是仍然还有噪声。于是作者就设计了图 10 中右下角的FlowNet-SD。
主要改进:
- 将FlowNetS的第一层的stride=2变为1
- 将7x7和5x5变为几个3x3
- 在上采样前加了卷积层用了平滑噪声
Fusion
最后的 Fusion 融合了前面的 FlowNetCSS-ft-sd 及 FlowNet-SD 的结果,输出预测的光流图Flow















 2395
2395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









