









Focal Loss for Dense Object Detection
论文:https://arxiv.org/abs/1708.02002
一、背景介绍
我们知道object detection的算法主要可以分为两大类:two-stage detector 和one-stage detector
前者(two-stage detector)是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。
后者(one-stage detector)是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率低。其中一个很重要的原因是,利用一个分类器很难既把负样本抑制掉,又把目标分类好。
作者希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度,因此提出了 Focal Loss 函数来训练模型。他在训练过程中发现,类别失衡是影响 one-stage 检测器准确度的主要原因,而所谓的类别失衡,指的是:负样本数量太大,占总的loss的大部分,而且多是容易分类的,因此使得模型的优化方向并不是我们所希望的那样
二、Focal Loss
先来看一下交叉熵损失函数,以二分类为例:
公式 1 中,p表示概率,因为是二分类,所以y=±1,p的范围为(0,1),当y=1时,假如某个样本x预测为1这个类的概率p=0.6,那么损失CE就是-log(0.6),注意这个损失是大于等于0的,因为对数函数的性质。如果p=0.9,那么损失就是-log(0.9),而p=0.6的损失要大于p=0.9的损失,这根据对数函数的图像很容易理解。
为了方便,我们用Pt代替p,如公式 2 所示:
因此公式 1 可以改写成:
为了解决 Class Imbalance (类别失衡),我们引入一个加权因子αt∈[0,1],当y = 1时,αt = α,当y = -1时,αt = 1-α。因此可以通过设定α的值(如果 y = 1的样本个数远远多于y = -1的样本个数,即正样本远多于负样本,那么α应该取0 --0.5 之间的数值,来提高y = -1的 Loss权重)来控制正负样本对总的loss的共享权重。由此我们得到公式 3:
公式 3 中αt平衡了正负样本的重要性,但是它不会区别易分类样本和难分类样本。因此,作者将损失函数再一次变形,为了降低易分样本的权重,专注于训练难分负样本,于是就有了Focal Loss:
公式 4 中作者加了 ( 1-Pt ) ^ γ 到交叉熵上,我们称之为调制因子(modulating factor),γ 是可以调节的专注参数 (focusing parameter),γ > 0。
我们来看一下Focal Loss的两个重要性质:
1、当一个样本被误分类,那么 Pt 就会非常小(比如当 y = 1 时,错分类意味着某样本 x 被预测为1的概率非常小,取 p = 0.1,因此 x 被预测为0的概率就是 1 - p = 0.9,即 1 被误分类为 0,此时 Pt 非常小),那么(1 - Pt)就趋向于 1,对 Loss 的影响非常小;反过来,当 Pt 趋向于 1 时(此时样本被分类正确,且是易分类样本),那么(1 - Pt)就趋向于 0,表示易分类样本的权重很低,对 Loss 的贡献很小。总而言之,就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
2、专注参数 γ 平滑地调节了易分类样本的权重比例。当 γ = 0 的时候,Focal Loss就是传统的交叉熵损失,γ 的增大能增强调制因子 ( 1-Pt ) ^ γ 的影响,实验中发现 γ 取 2 效果最好。举例来说,当 γ = 2 时,一个样本被分类的概率 Pt = 0.9 的损失比CE小1000多倍,这样就减少了简单易分类样本的重要性,相对增加了那些误分类样本的重要性。
作者在实验中采用的是公式 5 的 focal loss(结合了公式 3 和公式 4 ,这样既能调整正负样本的权重,又能控制难易分类样本的权重):
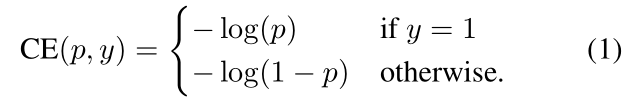
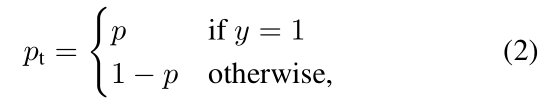
三、RetinaNet Detector
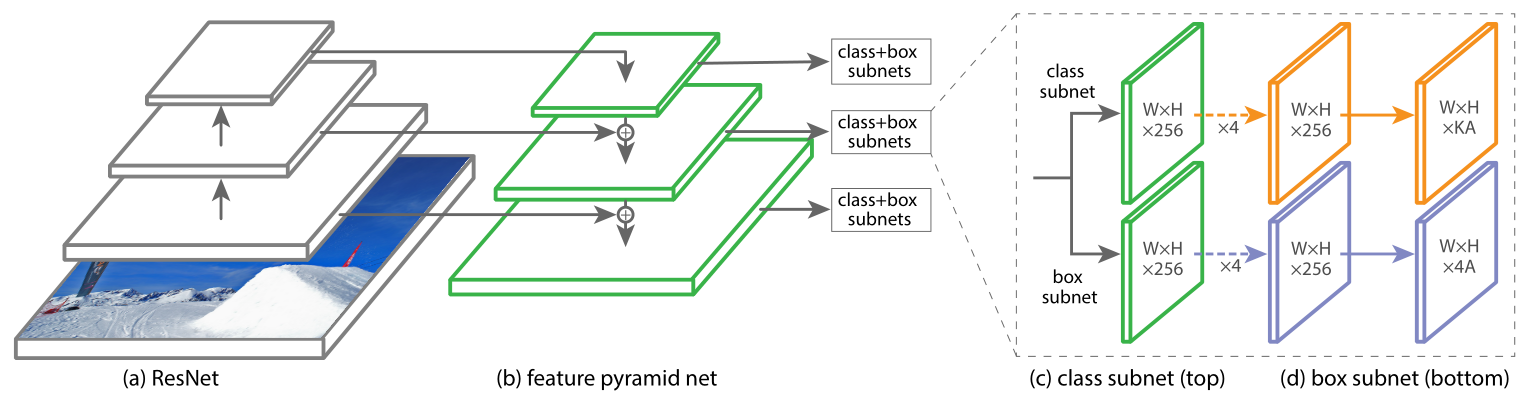
RetinaNet 是由一个骨干网络(backbone)和两个特定任务子网(task-specific)组成的单一网络。骨干网络负责在整个输入图像上计算卷积特征图,并且是一个现成的卷积网络。 第一个子网在骨干网络的输出上执行目标分类(Object Classification);第二个子网执行卷积边界框回归(bounding box regression)。网络结构如图 1 所示:
图 1
RetinaNet 在 ResNet 前馈网络的顶部使用了一个 Feature Pyramid Network(FPN)网络作为骨干网络,以此来生成丰富的、多尺度的 convolutional feature pyramid(卷积特征金字塔)。
Classification Subnet
如图 1(c) 所示,分类子网络在每个空间位置,为 A 个 anchors 和 K 个类别,预测 object presence 的概率。这个子网络是小的 FCN(全卷积网络),与 FPN 中的每一层相连;这个子网络的参数在整个金字塔的层间共享。设计方法是:如果一个从金字塔某个层里来的 feature map 是 C 个通道,子网络使用 4 个 3 * 3 的卷积层(图中橙色虚线箭头所示),C个滤波器,每个都接着ReLU激活函数;接下来用 3 * 3 的卷积层,有 KA 个滤波器。最后用sigmoid激活函数对于每个空间位置,输出 KA 个二进制的预测结果。作者用实验中 C = 256,A = 9。
与 RPN 对比,作者的 object classification 子网络(class subnet)更深,只用 3 * 3 卷积,且不和 box regression 子网络共享参数。作者发现这种 higer-level 的设计比超参数的特定值要重要。
Box Regression Subnet
与 Classification Subnet 平行,作者在金字塔每个层都接到一个小的FCN上,为了回归每个 anchor box 对邻近 ground truth object 的偏移量。回归子网络的设计和分类相同,不同的是它为每个空间位置输出 4A 个线性输出,如图 1(d)所示。对于每个空间位置的 A 个 anchors,4 个输出预测anchor和ground-truth box的相对偏移。与现在大多数工作不同的是,作者用了一个 class-agnostic bounding box regressor,这样能用更少的参数而且更高效。 object classification 和 bounding box regression 两个网络共享一个网络结构,但是分别用不同的参数。















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









