









Object Detection 一般分为两大部分
第一部分(Two-stage Detectors):R-CNN、Fast R-CNN、 Faster R-CNN、R-FCN
第二部分(One-stage Detectors) :YOLO、ssd
一、Two-stage Detectors
(一)、R-CNN (Regions with CNN)
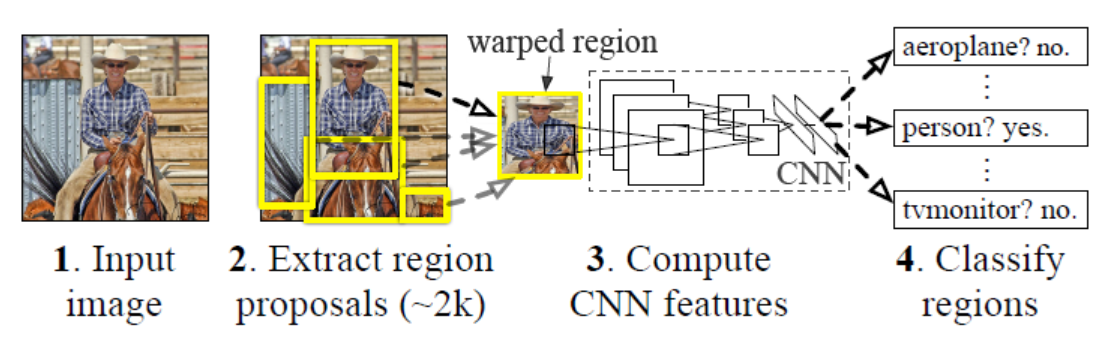 图 1
图 1
RCNN主要分为以下步骤:1、 提取候选框(Selective Search方法,提取约2k个候选框)2、将所有候选框输入CNN 提取特征3、使用 分类器对CNN的输出特征图进行分类,判定是否属于某一类4、对于预测为属于某一类的特征图,使用 回归器修正候选框位置
由于R-CNN中所有候选框都需要各自输入CNN中进行特征提取,因此造成了大量冗余的计算量。于是作者参考SPP-Net的思路研究出了后来的Fast R-CNN。
(二)、Fast R-CNN
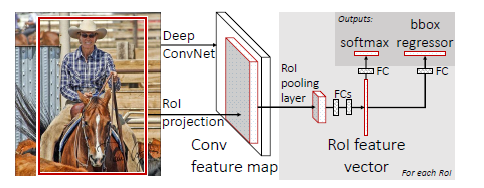
图 2
Fast R-CNN主要步骤如下:
1、使用Selective Search方法提取候选框,即在原图上生成ROI(regions of interest)
2、将生成了ROI的图像输入到CNN提取特征
3、CNN的输出特征图再经过ROI Pooling Layer,将原图中的ROI映射到特征图的对应位置,我们称之为patch,并用spp layer将patch统一到固定尺寸,输出为特征向量(feature vector)
4、最后分别输入到softmax分类器进行分类,以及bounding box回归器对ROI位置进行修正
与R-CNN的主要区别:
R-CNN中所有候选框都要经过卷积层,而Fast R-CNN只需要将原图输入卷积层,大量减少了计算量,提高了效率。
(三)、Faster R-CNN
参考:http://blog.csdn.net/zy1034092330/article/details/62044941
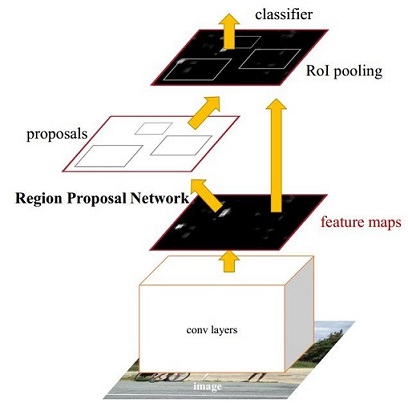
图 3
Faster R-CNN主要分为如下内容:
1、conv layers(卷积层)
提取特征图 feature maps
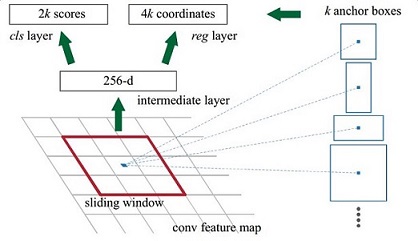
2、Region Proposal Network(RPN)
在 feature map 上提取候选框 region proposal 。并通过softmax判断anchors属于前景foreground还是背景background,之后再利用bounding box regression对anchors进行修正。
由于RPN为全卷积网络,因此可以共享之前的卷积层的参数,只需花很短的时间去提取候选框
RPN是一个网络,需要提前训练好,之后就能直接用来提取候选框了,速度比selective search方法更快
3、ROI Pooling
就是一层的SPP结构。主要用来将不同大小的ROI对应的feature map映射成同样维度的特征,思路是不论对多大的ROI,规定在上面画一个n*n 的网格,每个网格里的所有像素值做一个pooling(平均),这样不论图像多大,pooling后的ROI特征维度都是n*n。
输入为在原图经过卷积层输出的feature maps上,按照RPN得到的region proposal的位置信息,提取出特征图上的候选框。
输出为proposal feature maps(包含proposal位置信息的feature maps),即pooling到固定尺寸的那些候选框,表示为向量形式
4、Classification(分类)
对proposal feature maps进行分类,并通过bounding box 回归再次对候选框进行位置修正
详情如下:
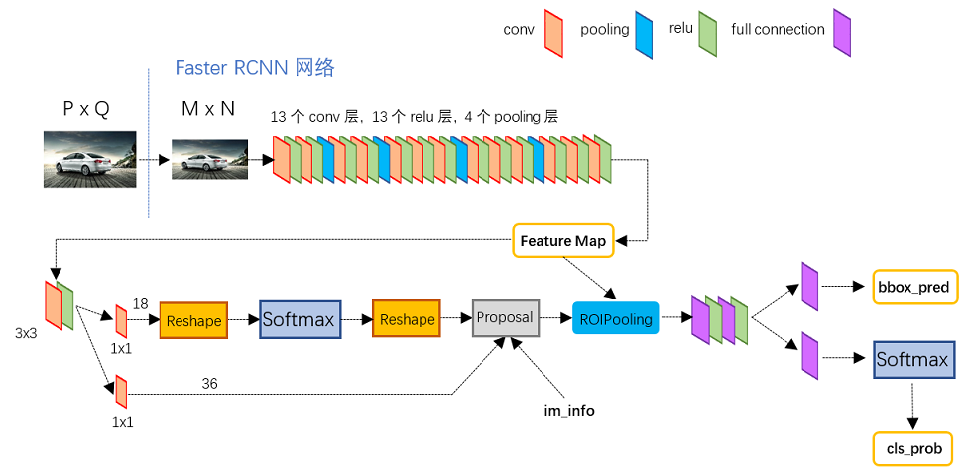
图 4
如图 4 所示,细节如下:
① 输入图像尺寸为 P*Q,resize到 M*N 后输入到卷积层中,最后输出的特征图feature map为 (M/16)*(N/16)
② feature map有两条路走:第一条路,直接通过ROI Pooling;第二条路,通过RPN网络生成候选框region proposal,之后通过ROI Pooling将候选框映射到feature map,生成带有候选框的feature map,我们称为proposal feature
③ RPN详情如下:
图 5
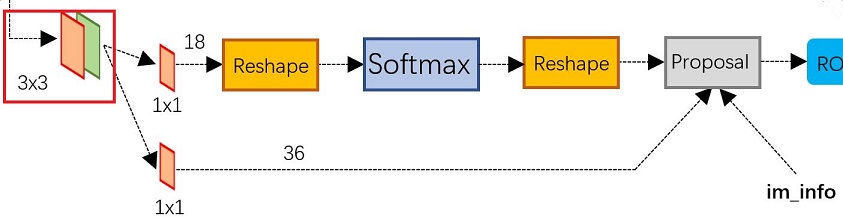
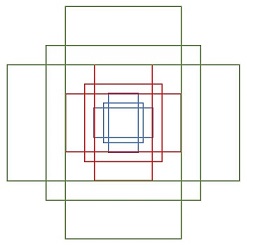
如图 5 所示,使用3*3的卷积核对feature map进行卷积,输出为256维,即256张特征图feature map,所以相当于特征图上每个点都是256维的,而在特征图每个点上都有k个anchors(默认k=9),anchors示意图如下:
图 6
图 7
即以特征图上每个点为中心进行候选框的选取,9个anchors一共三种形状 [ 1:1 , 1:2 , 2:1 ]。对于每个anchors要分前景 fg 和背景 bg,因此每个点由256-d转换为 cls = 2k = 2*9 = 18 维scores,而每个anchor都有 [ x,y,w,h ] 四个参数,因此需要 reg = 4k = 4*9 = 36 维 coordinates,如图 7所示。
回到图 5 ,由anchors得到的18维scores通过softmax层进行前景和背景的分类,之后通过proposal层,取出那些被判定为foreground的anchors,将其作为初步的region proposal(*);另外,由anchors得到的36维coordinates通过proposal层,经由bounding box regression修正之前初步得到的region proposal(*),我们将得到的结果称之为proposal
总而言之,RPN层的工作概括如下:
1)生成anchors
2)softmax分类器将anchors分类并取得foreground anchors
3)bounding box regression回归foreground anchors,修正其位置
4)proposal layer生成proposal
④ ROI Pooling层整合两个输入信息:原始 feature maps 以及 由RPN生成的 proposals 。输出为带有proposal的feature maps,以及pooling到固定尺寸的那些候选框,表示为向量形式
⑤ 对ROI Pooling层输出的那些候选框proposals进行分类,输出cls_prob概率向量;同时利用bounding box regression对proposals进行回归,获得每个proposal的bbox_pred位置偏移量,用于精修他们的位置
注意:Faster R-CNN 并没有显式地提取任何候选窗口,完全使用网络自身完成判断和修正,就是说将一系列的操作完全放在C一个网络中执行,很大程度上提高了效率。
(四)、R-FCN
参考:http://www.jianshu.com/p/db1b74770e52
图 8
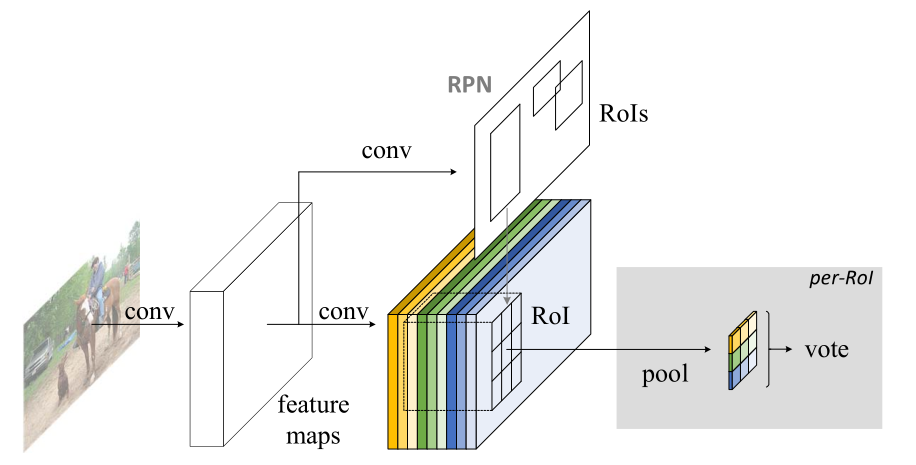
R-FCN的总体框架如图 8 所示:
① 原图输入卷积层提取特征,输出特征图feature maps
② feature maps 输入RPN网络提取候选框ROIs
③ 将ROIs映射到feature maps上
④ 再经过一个ROI Pooling Layer进行池化
⑤ 最后对其进行vote,即分类,确定其类别
细节:
图 9
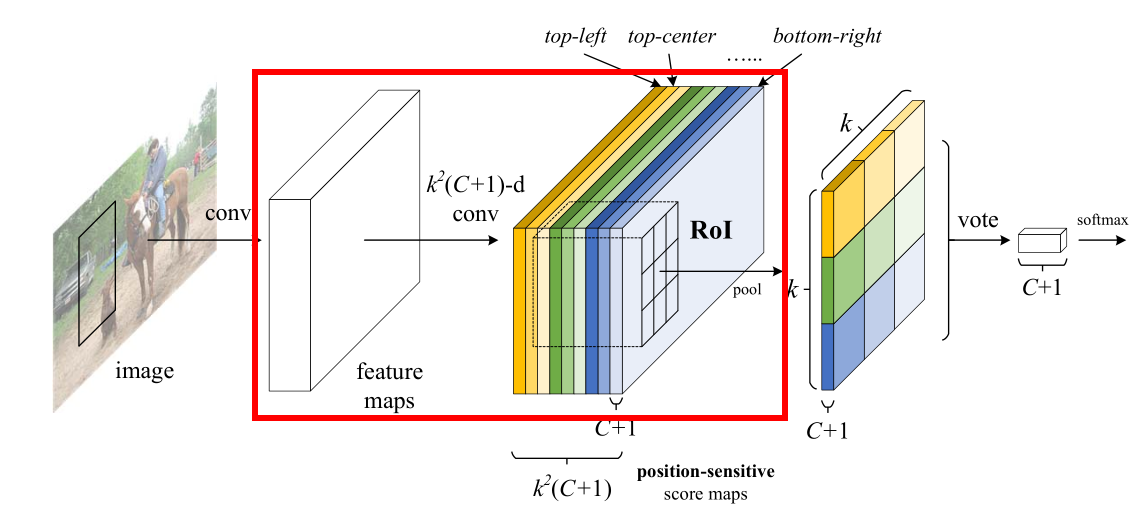
1)如图 9 所示,我们来看一下红框中左边卷积到右边的过程:
feature maps 再经过一个卷积层,这个卷积层有k^2*(C+1)个卷积核,即输出k^2*(C+1)新的特征图,我们称之为position-sensitive score maps(位置敏感的得分图)。对于这些score maps,k一般默认取3,C表示类别数,C+1表示类别数加上背景。
举个例子,我们假设k=3,C=6,那么最后生成的score maps有3*3*(6+1)=63张,对于每一类有9张,即上图中红框右边对应的九种颜色代表k*k=9,每种颜色的厚度表示类别数为(C+1)=7类,总的厚度即为所有score maps的数量k^2*(C+1)=63张。
图 10
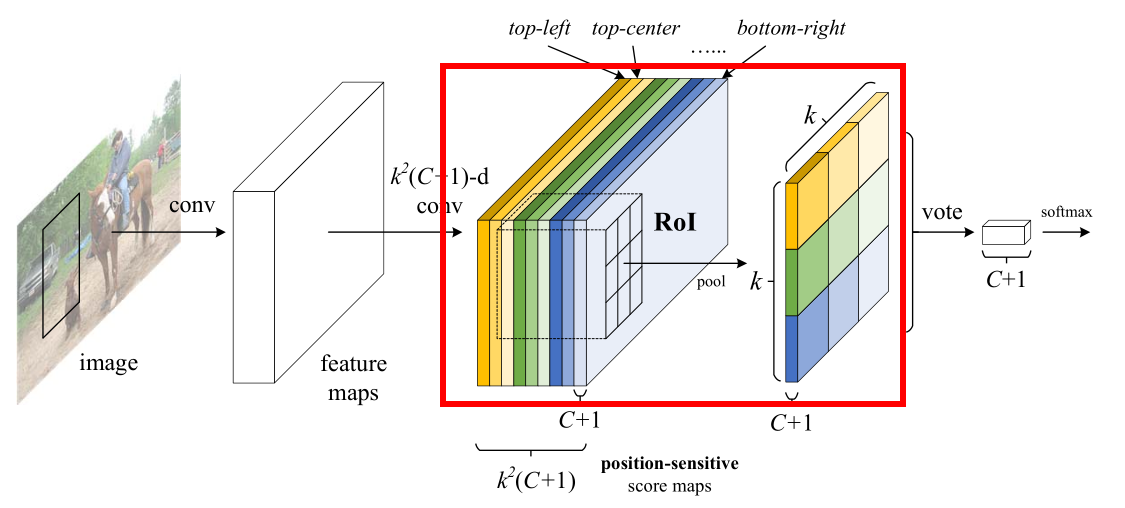
2)如图 10 所示,我们看一下对score maps进行池化的过程:
还是以上文为例,7个类别(6个物体类 + 1个背景类),有63张score maps,每一类为9张,这个9就对应上图红框左边的9种颜色。我们知道,之前通过RPN提取到了ROIs并将其映射到了score maps上,而这里的池化则只是针对于ROI进行的。我们同样将ROI平均分成k*k=3*3=9份,每一份我们称之为bin,如上图左边的九宫格所示,每一次池化操作只对一个bin进行。
比如说对于橙色的score maps,只关注ROI部分,我们只对其ROI的左上角那个bin进行平均池化,输出为上图红框右边对应的橙色格子
接着对黄色ROI的上面中间那个bin进行平均池化,输出为右边黄色的格子
然后对浅黄色ROI的右上角那个bin进行平均池化,输出为右边浅黄色的格子
之后对绿色ROI的左侧中间那个bin进行平均池化,输出为右边绿色的格子
以此类推………………
最终我们可以得到如图 10 红框右边所示的k*k=3*3=9种颜色的九宫格,他的厚度为(C+1),表示有C+1种类别。
这里只对ROI的某个bin进行池化,目的是为了记录位置信息
图 11
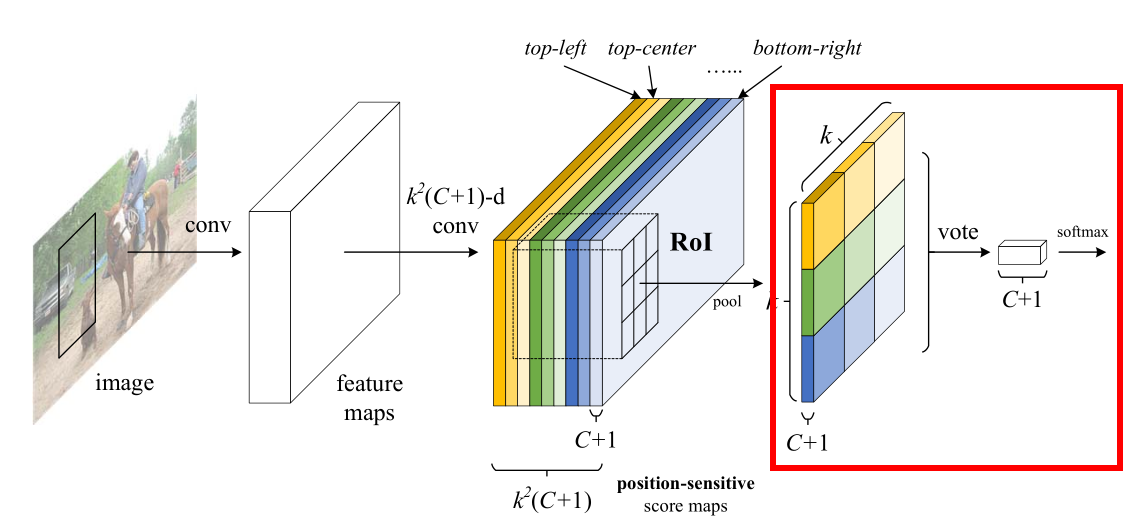
3)如图 11 所示,我们最后看一下对池化层的输出进行vote(投票)的过程:
对于池化层输出的特征图,它有(C+1)张,即(C+1)种类别,我们取其中一个类别c1为例,单独看它那张表示为九宫格的特征图,对它的9个bins分别进行vote(投票),最后取平均,得到对于c1这个类别的评分。以此类推,可以得到其他类别的相应评分,最终将所有这(C+1)个评分表示成向量的形式输入softmax函数,得到对应于原图中这个ROI的类别判定。




二、One-stage Detectors
(一)YOLO(You Only Look Once)
One-stage Detectors与Two-stage Detectors的区别:
Two-stage Detectors:大致将流程分为提取候选框(region proposal)、目标分类(classification)这两个分离的模块,因此我们称之为two-stage detector;预测速度慢,但是精度高
One-stage Detectors:将目标定位以及分类合成到一个单独的神经网络模型中,作为一个回归问题求解,能够一次性得到目标的位置和类别判定,因此我们称之为one-stage detector;预测速度快,但是精度低
YOLO流程如下:
图 12
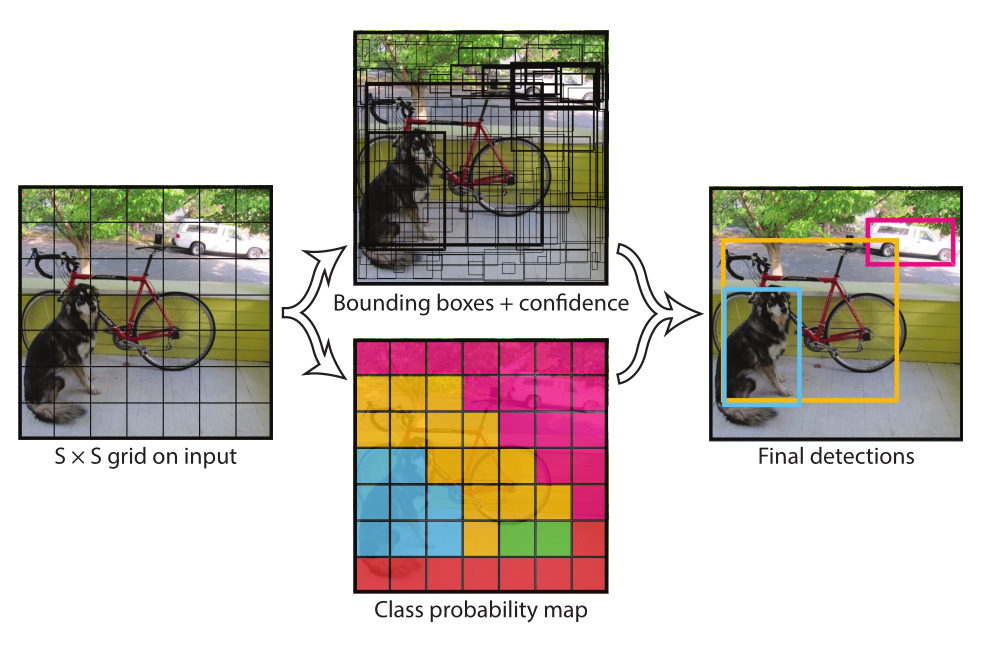
如图 12 所示
左图 ——YOLO首先将图像分成S*S个网格,如果一个目标的中心点落入某网格,那么这个网格就负责检测该目标。
中上图 ——每个网格又输出B个 bounding boxs,每个 bounding box 包含(x,y,w,h)以及 confidence 这5个值,其中(x,y)表示当前 bounding box 相对于当前网格的中心点的位置,w和h分别表示 bounding box 相对于整张图像的宽度和高度,confidence(置信值)代表该 bounding box 包含一个目标的置信度,即是否包含物体
中下图 ——每个网格需要预测他们各自的类别信息,即C个类别(categories)
右图 ——测试时,通过将每个网格的类别概率和 bounding box 的置信度相乘来得到对于该 bounding box 的特定类别的置信值,设定阈值,过滤低分的box,并通过NMS(非极大值抑制)方法挑选出最终的检测结果
S*S个网格,每个网格预测B个 bounding box 和C个categories,每个bounding box预测x,y,w,h,confidence这五个信息,因此最终输出就是S*S*(B*5+C)的一个tensor
注意:categories是针对网格的,confidence是针对bounding box的
举个例子:
取S=7,bounding box的数量B=2,类别数量C=20,则输出就是7*7*(2*5+20)=7*7*30的一个tensor
7*7*30可以理解为:每个网格有30维,其中8维(2*4)是bounding box的坐标以及形状信息,2维(2*1)是bounding box的confidence,还有20维是类别categories
缺陷:
1、每个网格只检测一个物体,容易造成误检
2、对于物体的尺度比较敏感,对尺度变化较大的物体泛化能力较差,即位置预测不够精确
针对以上缺陷,大牛们结合了YOLO和Faster R-CNN中的anchor的特点,既保证了实时性方面的速度,又保证了非实时性方面的精度,提出了SSD目标检测方法
(二)SSD(Single Shot Detector)
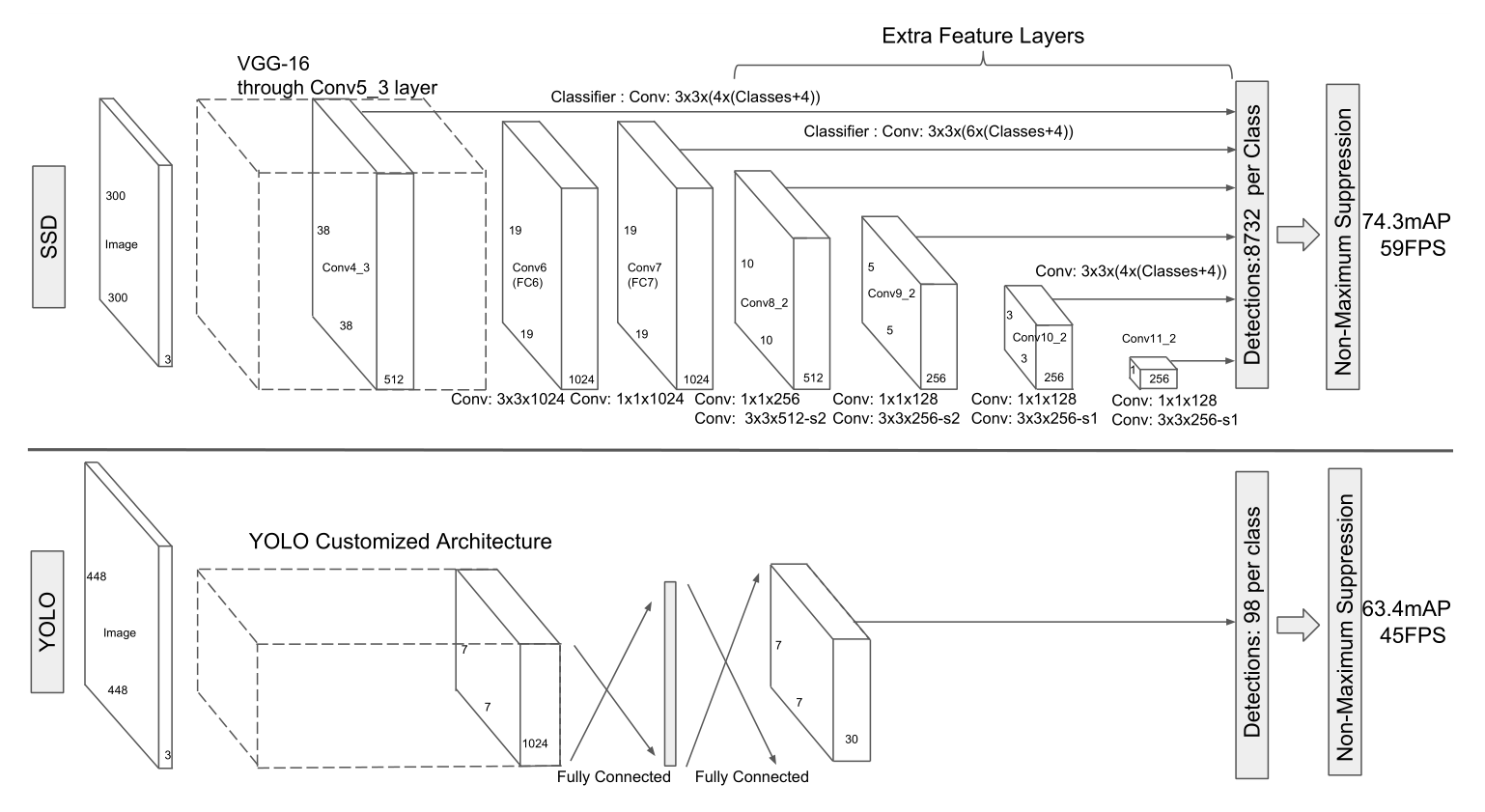
图 13
图 13 为SSD与YOLO的网络结构对比图,SSD采用VGG-16的前五层卷积层作为base-net,然后将VGG-16的fc6以及fc7转换为两个卷积层,之后又增加了三个卷积层和一个average pooling层。其中各卷积层输出的feature maps分别进行预测default box的偏移以及类别得分,最终通过NMS(非极大值抑制)得到结果。
关于候选框的选取:
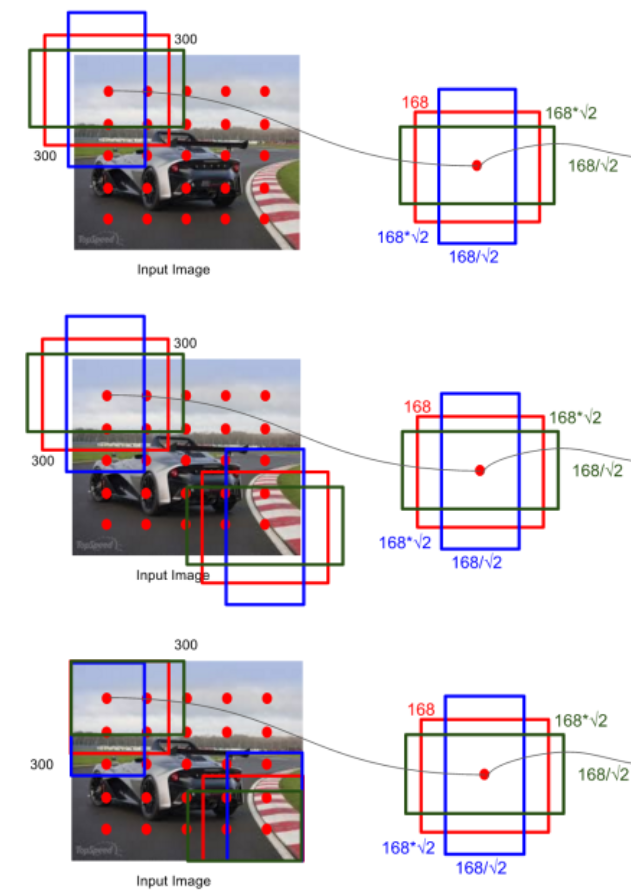
图 14
由图 14 我们可以看到,SSD首先采用YOLO的方式将图片分为S*S个网格,然后采用Faster R-CNN中的anchor的方式,在每个网格中按照不同的尺度和比例,生成k个default boxes,如上图中红绿蓝三个矩形框就是k个default boxes之三。(我们取S=5,k=6,那么整张图就会生成S*S*k=5*5*6=150个default boxes)
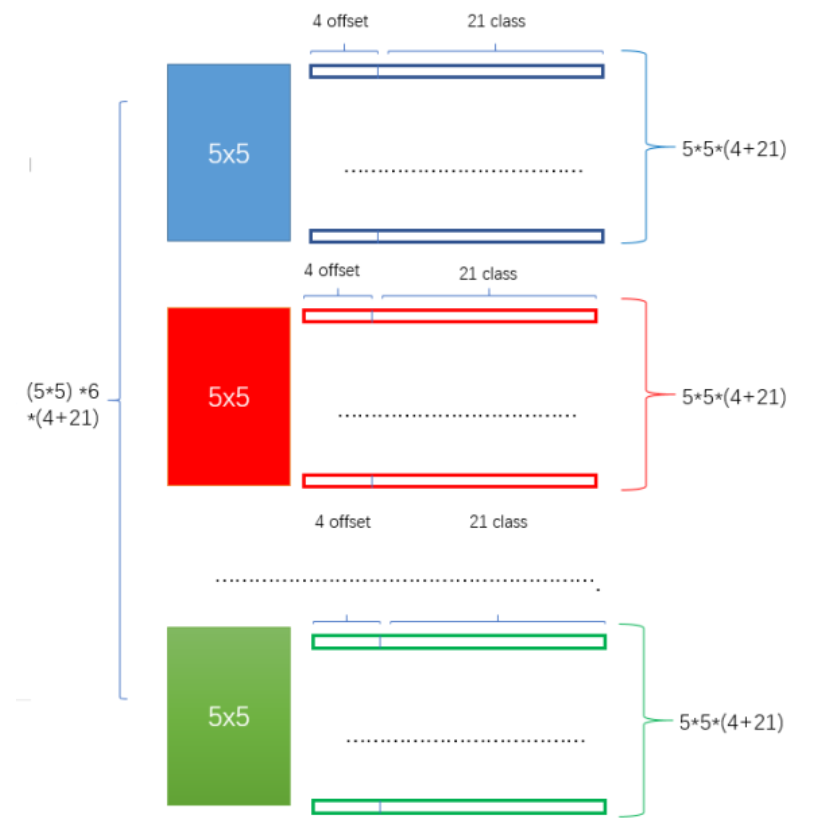
图 15
对于每个default box,将其通过一些小的卷积操作,得到各自的关于物体类别的(C+1)个置信度和4个偏移,如图 15所示,我们取类别数C=20,划分的网格维度S=5,每个网格生成的default box的数量k=6,那么对于某个feature map的输出就是 (S*S)*k*[4+(C+1)]=(5*5)*6*(4+21)
注意:以上一系列的操作都是在卷积层生成的各feature maps上分别执行的,最终将各feature maps的输出进行整合,得到结果















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









