







转载自:http://blog.csdn.net/beyondhaven/article/details/6753834
浏览器的种类成千上百,但所基于的内核,却没有几个。目前主流的浏览器内核主要为以下四种:
一、Trident内核,代表产品Internet Explorer
说起Trident,很多人都会感到陌生,但提起IE(Internet Explorer)则无人不知无人不晓,由于其被包含在全世界使用率最高的操作系统Windows中,得到了极高的市场占有率,所以我们又经常称其为IE内核。
Trident(又称为MSHTML),是微软开发的一种排版引擎。它在1997年10月与IE4一起诞生,至今经历12年,至少更新了四个版本,虽然它相对其它浏览器核心还比较落后,但Trident一直在被不断地更新和完善。而且除IE外,许多产品都在使用Trident核心,比如Windows的Help程序、RealPlayer、Windows Media Player、Windows Live Messenger、Outlook Express等等都使用了Trident技术。
使用Trident渲染引擎的浏览器包括:IE、傲游、世界之窗浏览器、Avant、腾讯TT、Netscape 8、NetCaptor、Sleipnir、GOSURF、GreenBrowser和KKman等。
二、Gecko内核,代表作品Mozilla Firefox
Gecko也是一个陌生的词,但Firefox的名声应该已经有所耳闻,Gecko是一套开放源代码的、以C++编写的网页排版引擎。
目前为Mozilla家族网页浏览器以及Netscape 6以后版本浏览器所使用。这软件原本是由网景通讯公司开发的,现在则由Mozilla基金会维护。它的最大优势是跨平台,能在Microsoft Windows、Linux和MacOS X等主要操作系统上运行,而且它提供了一个丰富的程序界面以供互联网相关的应用程式使用,例如网页浏览器、HTML编辑器、客户端/服务器等等。
Gecko是最流行的排版引擎之一,仅次于Trident。使用它的最著名浏览器有Firefox、Netscape6至9。
三、WebKit内核,代表作品Safari、Chrome
webkit 是一个开源项目,包含了来自KDE项目和苹果公司的一些组件,主要用于Mac OS系统,它的特点在于源码结构清晰、渲染速度极快。缺点是对网页代码的兼容性不高,导致一些编写不标准的网页无法正常显示。主要代表作品有Safari和Google的浏览器Chrome。
四、Presto内核,代表作品Opera
Presto是由Opera Software开发的浏览器排版引擎,供Opera 7.0及以上使用。它取代了旧版Opera 4至6版本使用的Elektra排版引擎,包括加入动态功能,例如网页或其部分可随着DOM及Script语法的事件而重新排版。
Presto在推出后不断有更新版本推出,使不少错误得以修正,以及阅读Javascript效能得以最佳化,并成为速度最快的引擎,这也是Opera被公认为速度最快的浏览器的基础。
序言
作为一个Web开发者,学习的浏览器操作的内部可以帮助您做出更好的决策,以及开发实践的最佳做法。 虽然这是一个相当漫长的文件,我们建议你花一些时间来挖掘研究, 我们保证你会很高兴你这样做的话。
简介
Web浏览器可能是最广泛使用的软件,在本文中,我将解释它们是如何在幕后工作的。当你在地址栏里敲入的goole.com,直到你在浏览器屏幕上看到谷歌网页,我们将看看这一过程中会发生什么。
目录
- 简介
- 我们所谈论的浏览器
- 浏览器的主要功能
- 浏览器的高层次结构
- 渲染引擎
- 渲染引擎
- 主要流程
- 主要流程实例
- 解析和DOM树建设
- 一般解析
- 文法
- 词法分析器 - 组合
- 翻译
- 解析示例
- 词汇和语法的正式定义
- 解析器的类型
- 自动生成解析器
- HTML解析器
- HTML语法定义
- 并非一个上下文无关文法
- HTML DTD
- DOM
- 解析算法
- 标记化算法
- 树构建算法
- 解析完成时的动作
- 浏览器允许误差
- CSS 解析
- WebKit的CSS解析器
- 脚本和样式表的处理顺序
- 脚本
- 投机性解析
- 样式表
- 一般解析
- 渲染树建设
- 渲染树与DOM树的关系
- 构建树的流程
- 样式的计算
- 共享样式数据
- 火狐规则树
- 结构拆分
- 使用规则树计算样式内容
- 一个简单的匹配操作规则
- 运用正确的级联秩序规则
- 样式表的级联顺序
- 特异性
- 排序规则
- 渐进的过程
- 布局
- 脏位系统
- 全局和增量布局
- 异步和同步布局
- 优化
- 布局过程
- 宽度计算
- 断行
- 绘制
- 全局和增量
- 绘制顺序
- 火狐显示列表
- Webkit的矩形存储
- 动态改变
- 渲染引擎的线程
- 事件循环
- CSS2的视觉模型
- 画布
- CSS盒模型
- 定位方案
- 盒类型
- 定位
- 相对
- 漂浮
- 绝对和固定
- 分层的代表性
- 参考资料
1.1 我们所谈论的浏览器
当今有五款主流的浏览器,分别是: Internet Explorer, Firefox, Safari, Chrome和Opera。将会给出开源浏览器的例子:Firefox, Chrome and Safari (部分开源)。根据2011年8月份的统计图表,Firefox, Safari和Chrome的总体使用份额占了将近60%,因此,时下的开源浏览器占浏览器业务的很大一部分比例。
1.2 浏览器的主要功能
浏览器的主要功能是:通过从服务器请求,并显示在浏览器窗口,以提供您选择的Web资源。资源通常是一个HTML文档,也可能是一个PDF文档、图片或者其它类型。资源的位置是由用户使用URI(统一资源标识符)指定的。
浏览器解释并显示HTML文件的方法是在HTML和CSS规范中指定的。这些规范是由W3C(万维网联盟)组织,它是为制定Web标准组织的机构。多年来的浏览器只是符合一个规范的一部分,并开发自己的扩展。这对网页的作者造成严重的兼容性问题。如今,大多数的浏览器或多或少符合规格。
浏览器的用户界面有很多共同之处。其中普通的用户界面元素是:
- 插入URI的地址栏
- 后退和前进按钮
- 书签选项
- 刷新和停止按钮,用于刷新和停止加载当前文档
- 主页按钮,可以让你到你的主页
1.3 浏览器的高层次结构
浏览器的主要组成如下:
1、用户界面----这包括地址栏,后退/前进按钮,书签菜单等,除主窗口外,在此可以看到所请求的页面浏览器中显示的每一个部分。
2、浏览器引擎----浏览器之间的界面行为和渲染引擎。
3、渲染引擎 ----负责显示所请求的内容。例如,如果请求的内容是HTML,它负责解析HTML和CSS,并在屏幕上显示的解析内容。
4、网络 ---- 网络调用,如用于HTTP请求。它具有平台无关的接口,并为每个平台下面实现的。
5、UI后端 ---- 用于绘制基本部件,如组合框和Windows控件。它暴露了一个通用的接口即不特定于某一平台的。它的下面使用的操作系统的用户界面的方法。
6、JavaScript解释器----用于解析和执行的JavaScript代码。
7、数据存储----这是一个持久层,浏览器保存在硬盘上的数据,例如:cookies。新的HTML规范(HTML5)定义“网络数据库”,这是一个完整的(虽然是轻量级)在浏览器中的数据库。

图1:浏览器的主要组成部分
重要的是要注意,Chrome不像大多数的浏览器只提供一个渲染引擎,它拥有多个实例的渲染引擎,为每个标签提供。每个选项卡是一个单独的进程。
第2章
渲染引擎
渲染引擎的责任... 渲染,就是所要求的内容浏览器屏幕上显示。
默认情况下,渲染引擎可以显示HTML和XML文档和图像。通过一个插件(或浏览器扩展),它可以显示其他类型。例如,使用PDF查看器中显示PDF格式插件。然而,在这一章中,我们将重点放在主要的用例:使用CSS格式化显示HTML和图像。
2.1 渲染引擎
我们的参考浏览器 - 火狐,Chrome和Safari是建立在两个渲染引擎之上。Firefox的使用Gecko - “自制的”Mozilla的渲染引擎;Safari和Chrome使用是Webkit。WebKit是一个开源渲染引擎,开始时为Linux平台的引擎,是由苹果公司修改后,以支持Mac和Windows。点击webkit.org查看详细内容。
2.2 主要流程
渲染引擎将开始从网络层获取所要求的文件的内容,这通常是在8K的块。
之后,这是渲染引擎的基本流程:

图2:渲染引擎的基本流程
渲染引擎开始解析HTML文档,转换树中的标签到DOM节点,它被称为“内容树”。它将解析样式数据,包括外部CSS文件和样式元素。样式信息与HTML中的视觉指示信息,将被用于创建另一个树 ---- 渲染树。
渲染树中包含的视觉属性,如颜色和尺寸的矩形。矩形被正确的顺序显示在屏幕上。
建设渲染树后,它经过一个“布局”的过程。这意味着给每个节点所应该出现在屏幕上的精确坐标。下一阶段是绘制 ---- 将遍历渲染树,每个节点将使用UI后端层来绘制。
重要的是要明白,这是一个渐进的过程。为了达到更好的用户体验,渲染引擎将努力尽可能快地在屏幕上显示内容。它在所有的HTML解析完成之前就开始建设和布局渲染树。部分内容将被解析和显示,而这个过程会一直持续,其余的内容则使来自网络。
2.3 主要流程实例
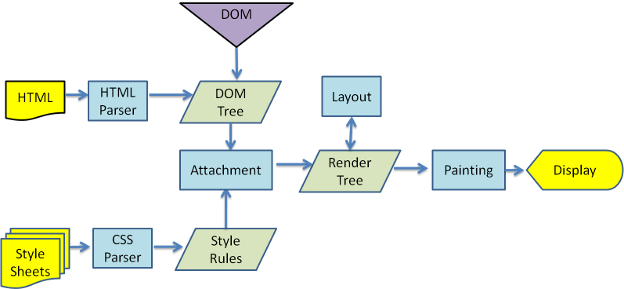
图3:Webkit主要流程
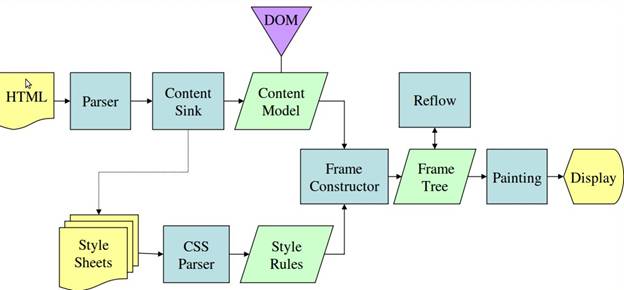
图4:Mozilla的Gecko渲染引擎的主要流程
从图3和4可以看到,尽管WebKit和Gecko的使用策略稍有不同,流程基本上是相同的的。
Gecko称视觉格式化的元素树为一个“框架树”。每个元素都是一个框架。Webkit的使用术语为“渲染树”,并且它由“渲染对象”组成。Webkit的使用术语“布局”来描述元素的放置,而Gecko称之为“回流”。“附件”是WebKit连接DOM节点和视觉信息来创建渲染树的术语。一个轻微的非语义的区别是,Gecko(Molla浏览器的排版引擎)有一个HTML和DOM树之间额外的层。这就是所谓的“内容汇”,是一个DOM元素的工厂。我们将讨论流程的每一部分。
3.解析和DOM树建设
3.1 一般解析
由于解析在渲染引擎中是一个很重要的过程,我们将更加深刻的讲解。让我们开始一个有关解析的简要介绍。
解析文档意味着将其转换成一些有意义的结构----代码可以理解和使用。解析的结果通常是一个树的节点表示文档的结构,它被称为解析树或语法树。
范例 - 解析表达式2 + 3 - 1,可以返回此树:

图5:数学表达式树节点
3.1.1 文法
解析是基于文档所遵循的语法规则 ---- 所写文档的语言或格式。每次解析你可以的格式必须具有确定性的词汇和语法规则的语法。这就是所谓的上下文无关文法。人类的语言是没有这样的语言,因此不能用传统的解析技术解析。
3.1.2 词法分析器 - 组合
解析可分为两个子过程 ---- 词法分析和语法分析。
词法分析是分解成记号输入的过程。记号是语言词汇 ---- 收集的有效的积木。在人类语言中,它将包括所有的在该语言字典中出现的词汇。
句法分析采用的是语法规则。
分析器通常把要做的工作分解为两个部分----词法分析(有时也叫做记号分析)负责分成输入有效的记号;解析器负责分析文档的结构,根据语言的语法规则,构造解析树。词法分析器知道如何去掉无关的字符,例如空格和换行符。

图6:从源文件解析的树
解析过程是迭代的。解析器通常会要求词法分析器一个新的记号,尝试用语法规则来匹配记号。如果规则匹配,一个节点对应的记号将被添加到该解析树,解析器会请求另一个记号。如果没有匹配的规则,解析器将内部存储记号,并不断请求记号,直到在所有内部存储的记号中找到一个规则匹配的。如果发现没有规则,解析器将抛出一个异常。这意味着该文件是无效的,并包含语法错误。
3.1.3 翻译
解析树很多时候,是不是最终产品。解析中经常使用翻译 ---- 转换为另一种格式的输入文件。编译就是一个例子。编译器的源代码编译成机器代码首先解析成语法树,然后翻译成机器代码文件树。

图7:编译流程
3.1.4 解析示例
在图5中,我们建立了一个数学表达式的解析树。让我们试着定义一个简单的数学语言和解析过程。
词汇:我们的语言可以包括整数,加号和减号。
语法:
1、语言语法构造块是表达式、 条件和操作。
2、我们的语言可以包含任意数量的表达式。
3、表达式定义为一个"术语"跟着"操作"跟着另一个术语
4、操作是加号或减号
5、术语是一个整数标记或表达式
让我们来分析 2+3-1这个输入。
与规则相匹配的第一个子字符串是 2,根据规则 #5 是一个术语。第二种匹配是 2 + 3 ,这个匹配是第三个规则-----一个术语后跟着一个操作再跟着另一个术语。下一个匹配,将只会在输入结束时命中。2+3-1是一个表达式,因为我们已经知道 2+3 是一个术语,所以我们必须术语后跟着操作再跟着另一个术语。2++ 不会与任何规则相匹配,因此是无效的输入。
3.1.5 词汇和语法的正式定义
词汇是通常由正则表达式表示。例如,我们的语言经常会做如下的定义:
INTEGER :0|[1-9][0-9]* PLUS : + MINUS: -
如你所见,整数已经定义为一个正则表达式。
语法通常被称为BNF 格式定义。我们的语言将定义如下:
expression := term operation term operation := PLUS | MINUS term := INTEGER | expression
我们说一种语言如果是一个上下文无关语法,则可以通过有规律的分析器解析其语法。上下文无关文法的直观的定义是可以完全在BNF 表示法表示的语法。正式的定义请参阅上下文无关文法维基百科的文章。
3.1.6 解析器的类型
有两种基本类型的解析器-自上而下解析器和自下而上的解析器。自上而下解析器的一个直观的解释是,看到高层次结构的语法,并尝试匹配其中之一。自下而上解析器开始输入并逐渐将它转换为语法规则,从低级别规则开始,直到满足高层次规则。
让我们看看这两种类型的解析器将如何解析我们的示例:自上而下的解析器将开始从更高级别规则 — — 它将确定 2 + 3 作为表达式。它然后将标识 2 + 3-1 作为表达式 (确定表达式的过程演变匹配其他规则,但起点是最高级别规则)。
自下而上的解析器会扫描输入,然后将替换匹配输入规则,直到匹配规则,这将继续下去,直到输入的结束,部分匹配的表达式放置在解析堆栈上。
| Stack | Input |
|---|---|
| 2 + 3 - 1 | |
| term | + 3 - 1 |
| term operation | 3 - 1 |
| expression | - 1 |
| expression operation | 1 |
| expression | |
这种自下而上的解析器的称为转移减少分析器,,因为其向右移动的输入 (想象一下一个指针,指向首先输入开始和向右移动) 和语法规则逐渐减少。
3.1.7 自动生成解析器
有些可以为您生成的解析器的工具,他们被称为解析生成器。你给它们您的语言的语法 — — 它的词汇和语法规则 — — 他们生成工作解析器。创建一个解析器需要深入了解的解析和其不容易用手创建一个优化的解析器,因此解析生成器可能非常有用。Webkit 使用两个众所周知的解析生成器-Flex 创建分析器 和Bison创建一个词法分析器(您可能会遇到他们的名字 Lex 和 Yacc)。Flex 的输入是一个包含正则表达式定义的标记的文件.Bison的输入是 BNF 格式的语言语法规则。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









