







Linux进程间通信可以采用的方法很多,例如“管道”、“信号”、“共享内存”、“消息队列”、“套接字”等等。不过,我个人比较喜欢“消息队列”。
消息队列和管道相比,至少有以下几个特点:
(1)消息队列是双向、双工的。
(2)如果进程数量较多,要互相通信,如果采用管道的话,要创建很多个管道文件。
(3)消息队列先天就是“异步”操作,例如A进程丢进去,B进程再读出来。A丢进去后,A还可以做其他事。不用管B什么时候去读。
例如:
消息发送函数 int SendMSG(int mqid,long mtype,std::string _msg) strcpy(msg.mtext,_msg.data()); msg.mtype=mtype; msgsnd(mqid,&msg,strlen(msg.mtext)+1,0); return 1;
|
(4)消息的读取操作是阻塞方式的,在多线程编程里,相当的省事
例如: 我们启用一个专门的线程来接收消息 void *pthread_MsgHandle(void *arg) { return (void*) (1);
|
那么现在进入正题,谈谈需求。 假设现在有6个进程,相互之间要互相通信。
进程名称依次是:A、B、C、D、E、F
例如:A要发送消息给B、C、D
B要发送消息给D、E、F、A
C要发送消息给D、E、F
。。。。。等等。。。。 可能性实在太多。。。
我们现在用消息队列就是要解决这个问题。
问题看上去很难,实际上只要好好思考,就发现用消息队列很简单。
怎么思考呢?
首先,要创建一个消息队列。

然后做好消息接收【通道】定义。
例如:
#define CH_A 1
#define CH_B 2
#define CH_C 3
#define CH_D 4
#define CH_E 5
#define CH_F 6
总之你有多少个进程要共用这个消息队列,你就定义多少个。
【通道】:
解释哈,这个名词不是Linux的标准解释,仅仅是我自己规定的,就像在高速公路的车行道里规定的车道1(行车道)、车道2(货车道)、车道3(超车道)的概念。
通道定义好了,那么再定义消息的来源标示
例如:
#define MSG_A 1
#define MSG_B 2
#define MSG_C 3
#define MSG_D 4
#define MSG_E 5
#define MSG_F 6
有同学问我,为什么不直接采用通道标示呢? 原因很简单。
在一个通道里可能有很多进程发来的消息。 我们拿什么识别呢? 就用消息头识别。
这些定义都有了,我们再看看Linux消息的结构体定义。
struct UMMessage{
long mtype;
char mtext[MSG_TXT_LEN];
};
这些都定义完了,就来说说,怎么收发消息了。
首先:如果A要消息给B,则这么做。

在发送消息时,指定好【通道】名称,即UM_MSG了
在消息的内容里,加上我们事先规定好的【消息来源标示】
例如: MSG_A={你好吗?}
那么,A发给B的消息就是
SendMSG(mqid,CH_B," MSG_A={你好吗?} " ;
C发给B的消息就是
SendMSG(mqid,CH_B," MSG_C={你好吗?} " ;
那么B怎么处理消息呢?
首先B会根据【消息通道】号从消息队列中读取自己的【消息】
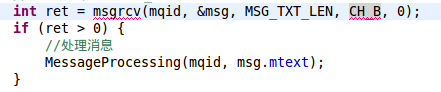
然后再根据消息内容的【源标示】就可以识别消息是谁发的了。
最后再根据 msg.mtext里面的内容的 前面部分 MSG_C 这个部分来识别是谁发的了。
多个进程的消息通信基本就可以采用这个思路。如果还有疑问,欢迎大家一起来交流。















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









