







目录
七、Learning Curve学习曲线->判断high bia/var
一、One_hot编码:(逻辑回归or神经网络)
二、评估classificaition_report

三、序列化&解序列化

四、神经网络的随机初始化

五、特征值映射 Feature-mapping

def feature_mapping(x1,x2,power):
data={} #建立一个空字典
for i in np.arange(power+1):
for j in np.arange(i+1):
data['F{}{}'.format(i-j,j)]=np.power(x1,i-j)*np.power(x2,j)
return pd.DataFrame(data)
六、特征值缩放->归一化和标准化



场景一:有训练集train、交叉验证集cv和测试集test.
一般只需要训练集的mean和std即可
->why:
注意:不同特征mean和std是需要进行分别去求的,不能够混合求


七、Learning Curve学习曲线->判断high bia/var
八、数据的训练集、交叉验证集、测试集的应用:
用交叉验证集选择最佳lambda
# 用交叉验证集选择lmd
lamdas = [0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10]
training_cost = []
cv_cost = []
for lamda in lamdas:
res = train_model(X_train_norm, y_train, lamda)
tc = reg_cost(res, X_train_norm, y_train, lamda=0)#计算训练集上的误差
cv = reg_cost(res, X_val_norm, y_val, lamda=0)#计算验证集上的误差
training_cost.append(tc)
cv_cost.append(cv)
plt.plot(lamdas, training_cost, label='training cost')#不同lamda取值下训练集的损失
plt.plot(lamdas, cv_cost, label='cv cost')
plt.legend()
plt.show()
#拿到最佳lamda
bestLamda = lamdas[np.argmin(cv_cost)]
print(bestLamda)#3
#用最佳lamda来训练测试集
res = train_model(X_train_norm, y_train, bestLamda)
print(reg_cost(res, X_test_norm, y_test, lamda=0))#4.3976161577441975由训练集(带lambda训练)得到theta,->通过看何时cv_cost最小,取为bestLambda->用于test集
九、支持向量机svm的使用
from sklearn.svm import SVC①用SVC函数初始化一个对象出来
常用参数有:C、kernel、gamma

svc1 = SVC(C=1,kernel='linear')
②喂训练集的X_train与y_train-->拟合参数
注意y是一维的---flatten降维度操作
svc1.fit(X,y.flatten())③给定X_d预测相关的y
svc1.predict(X)④将原来的X_train与y_train给出--->可以得知准确率
svc1.score(X,y.flatten())补充:寻找最优的C与gamma 
十、利用meshgrid与contour绘制二维高阶的决策边界
1.原理与应用展示

如上图,一一组合,构成了网格的一个个坐标(注意y每一行都是相同的元素,x是每一列)



例1:
x=np.linspace(-1.2,1.2,200)
xx,yy=np.meshgrid(x,x)#生成两个网格(200,200)
z=feature_mapping(xx.ravel(),yy.ravel(),6).values
z=np.c_[np.ones(z.shape[0]),z]
zz=z@theta_final
zz=zz.reshape(xx.shape)
plt.contour(xx,yy,zz,1)2.应用:
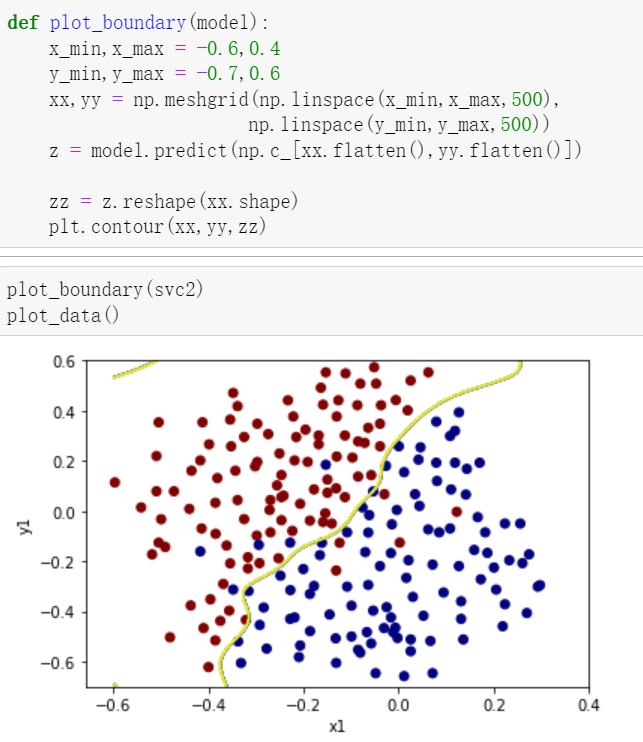
值得注意的是这边的np.c_[ ]将两个flatten()之后的一维数组,变成了(k,2)二维的数组
十一、K-means算法
1.介绍:



2.具体代码实现细节:
①有关np.linalg.norm()解析
②函数:




③初始化聚类点的选取:
def init_centros(X,k):
index = np.random.choice(len(X),k)
return X[index] #此处仍然利用的是bool索引->随机选择出k个坐标3.案例演示:使用kmeans对图片颜色进行聚类
①RGB图像,每个像素点值范围0-255
图片的读取---
from skimage import io
②用16个聚类重构该图片:

十二、PCA降维
1.PCA相关简介

2.执行步骤





3.调用numpy的线性代数库
U,S,V = np.linalg.svd(C)
十三、异常检测
1.算法流程:

2.具体的细节:



3.案例代码:
①获取训练集中样本特征的均值和方差
def estimateGaussian(X,isCovariance): means = np.mean(X,axis=0) if isCovariance: sigma2 = (X-means).T@(X-means) / len(X) else: sigma2 = np.var(X,axis=0) return means,sigma2相同数据两者的区别:
注:原高斯分布模型是多元高斯分布模型的一种特殊情况。(如果协方差矩阵只在对角线的单位上有非零的值,即为原本的高斯分布模型)
②多元正态分布密度函数
再给出相关实现代码之前,了解一下np.diag()的使用方法
(1)对于一个二维矩阵,直接进行了降维操作,只取对角线上的元素.
(2)对于一个一维矩阵,斜对角线上自动补零,构成二维的矩阵。
def gaussian(X,means,sigma2): if np.ndim(sigma2) == 1: sigma2 = np.diag(sigma2) X = X - means n = X.shape[1] #X:(307,2) sigma:(2,2) X.T:(2,307)--->(307,307) first = np.power(2*np.pi,-n/2)*(np.linalg.det(sigma2)**(-0.5)) second =np.diag(X@np.linalg.inv(sigma2)@X.T) #np.diag操作对象为二维数组,取对角线元素构成新的一维数组(307,) p = first * np.exp(-0.5*second) p = p.reshape(-1,1) #p---->(307,1) # m = len(X) # second = np.zeros(m,1) # for row in range(m): # second[row] = X[row].T @ np.linalg.inv(sigma2) @ X[row] # p = first * np.exp(-0.5*second) return p注意:
(i)利用np.ndim判断是否是一个一维数组,是-->将其上升一个维度.(真正变成多元正态分布的一个特殊情况.)
(ii)np.linalg.det计算行列式的值,np.linalg.inv对一个矩阵取逆
(iii)second一开始的维度是(307,307)实际上只有对角线上才是对应的p,上面的代码等效于下面注释的一块代码(用numpy的库进行矩阵运算可能会更快一点)
③绘图
def plotGaussian(X,means,sigma2): x = np.arange(0, 30, 0.5) y = np.arange(0, 30, 0.5) xx, yy = np.meshgrid(x,y) z= gaussian(np.c_[xx.ravel(),yy.ravel()], means, sigma2) # 计算对应的高斯分布函数 zz = z.reshape(xx.shape) plt.plot(X[:,0],X[:,1],'bx') contour_levels = [10**h for h in range(-20,0,3)]#列表解析, 10的负数次次方-->保证概率在0-1之间 plt.contour(xx, yy, zz, contour_levels)
④通过F1_score选取最佳的epsilon
def selectThreshold(yval,p): bestEpsilon = 0 bestF1 = 0 epsilons = np.linspace(min(p),max(p),1000) for e in epsilons: p_ = p < e tp = np.sum((yval == 1) & (p_ == 1)) fp = np.sum((yval == 0) & (p_ == 1)) fn = np.sum((yval == 1) & (p_ == 0)) prec = tp / (tp + fp) if (tp+fp) else 0 #细节:防止分母是0!!!----NaN rec = tp / (tp + fn) if (tp+fn) else 0 F1_e = 2 * prec * rec / (prec + rec) if (prec + rec) else 0 if F1_e > bestF1: bestF1 = F1_e bestEpsilon = e return bestEpsilon,bestF1
高维数据的异常检测:







十四、案例----推荐系统->协同过滤算法:
1.参数的说明与数据的预处理
Y.shape=(1682,943)=R.shape
X.shape=(1682,10) Theta.shape=(943,10)

注:参数nm-->num of movies nu-->num of users nf-->num of features
在编写cost_function和gradient之前,由于opt.minimize的x0参数必须要传入一个一维数组,所以写好序列化参数和解序列化的参数代码:
def serialize(X,Theta):
return np.append(X.flatten(),Theta.flatten())
#####
def deserialize(params,nm,nu,nf):
X = params[:nm*nf].reshape(nm,nf)
Theta = params[nm*nf:].reshape(nu,nf)
return X,Theta2.代价函数与梯度(带正则)
①代价函数
def costFunction(params,Y,R,nm,nu,nf,lamda): X,Theta = deserialize(params,nm,nu,nf) error = 0.5 * np.square((X@Theta.T - Y)* R).sum()#点乘R reg1 = 0.5 * lamda * np.square(X).sum() reg2 = 0.5 * lamda * np.square(Theta).sum() return error + reg1 + reg2注:点乘R是为了保证是评价过的电影才算入cost中。
##test users = 4 movies = 5 features = 3 X_sub = X[:movies,:features] Theta_sub = Theta[:users,:features] Y_sub = Y[:movies,:users] R_sub = R[:movies,:users] cost1 = costFunction(serialize(X_sub,Theta_sub),Y_sub,R_sub,movies,users,features,lamda = 0) cost1 ##22.224603725685675


def costGradient(params,Y,R,nm,nu,nf,lamda):
X,Theta = deserialize(params,nm,nu,nf)
X_grad = ((X@Theta.T-Y)*R)@Theta +lamda * X
Theta_grad = ((X@Theta.T-Y)*R).T@X + lamda * Theta
return serialize(X_grad,Theta_grad)(i)注意维度对应
(ii)注意点乘R
3.添加一个新用户
my_ratings = np.zeros((nm,1))
my_ratings[9] = 5
my_ratings[66] = 5
my_ratings[96] = 5
my_ratings[121] = 4
my_ratings[148] = 4
my_ratings[285] = 3
my_ratings[490] = 4
my_ratings[599] = 4
my_ratings[643] = 4
my_ratings[958] = 5
my_ratings[1117] = 3
Y = np.c_[Y,my_ratings]
R = np.c_[R,my_ratings!=0]
nm,nu = Y.shapeY.shape=(1682, 944)
4.均值归一化与参数的初始化

def normalizeRatings(Y,R):
Y_mean =(Y.sum(axis=1) / R.sum(axis=1)).reshape(-1,1)
Y_norm = (Y - Y_mean) * R
return Y_norm,Y_mean
Y_norm,Y_mean = normalizeRatings(Y,R)X = np.random.random((nm,nf))
Theta = np.random.random((nu,nf))
params = serialize(X,Theta)
lamda = 105.训练模型并预测
#-------训练模型----------
from scipy.optimize import minimize
res = minimize(fun = costFunction,
x0 = params,
args = (Y_norm,R,nm,nu,nf,lamda),
method = 'TNC',
jac = costGradient,
options = {'maxiter':100})
params_fit = res.x
fit_X,fit_Theta = deserialize(params_fit,nm,nu,nf)
#---------预测---------
Y_pred = fit_X@fit_Theta.T
y_pred = Y_pred[:,-1] + Y_mean.flatten()#预测自己新添加的
index = np.argsort(-y_pred)#默认自小到大,加上一个负号就是反向or在最后加上[::-1]
print(index[:10])#array([1466, 1292, 1200, 1499, 1121, 1652, 813, 1598, 1188, 1535])
#读取对应的电影名称
movies = []
with open('data/movie_ids.txt','r',encoding='latin 1') as f:
for line in f:
tokens = line.strip().split(' ')
movies.append(' '.join(tokens[1:]))
print(len(movies))#1682
for i in range(10):
print(index[i],movies[index[i]],y_pred[index[i]])
'''
1466 Saint of Fort Washington, The (1993) 5.001810464524898
1292 Star Kid (1997) 5.001694543358842
1200 Marlene Dietrich: Shadow and Light (1996) 5.00149967272587
1499 Santa with Muscles (1996) 5.001334854576942
1121 They Made Me a Criminal (1939) 5.000999967820586
1652 Entertaining Angels: The Dorothy Day Story (1996) 5.000975637072753
813 Great Day in Harlem, A (1994) 5.000799086576183
1598 Someone Else's America (1995) 5.0006016104689905
1188 Prefontaine (1997) 5.000467537343162
1535 Aiqing wansui (1994) 5.000239077425466
'''















 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











