






本文将针对ORC与Parquet这两种列式存储方式进行详细解析。在了解两者存储特点的同时,我们也将深入探究它们在底层存储内存上的异同之处,让我们一起来看看吧!
一、ORC和Parquet的区别
ORC列式存储
ORC(Optimized Row Columnar)是一种高效的列式存储格式,通常用于数据仓库和大规模数据分析场景。它是由Hive社区开发的,并由Apache软件基金会进行管理。
ORC主要由三个层级组成:文件、条带(Stripe)和行组(Row Group)。文件是包含多个条带的顶层结构,每个条带又由多个行组组成。这种多级结构可以帮助ORC优化查询性能并提高数据压缩率。
在ORC中,数据被按列而不是按行存储,这意味着相同类型的数据将被存储在相邻的位置上,方便进行批量处理和压缩。此外,ORC还提供了一些额外的功能,如跳过不必要的行、布隆过滤器和字典编码等,以提高查询速度并降低存储成本。
与其他列式存储格式相比,ORC还具有一些独特的特点。例如,在ORC的Stripe中,索引信息可以在头部进行统一抽取,这样可以减少IO操作的次数;同时,ORC还支持读取数据时进行分段解压,从而加快查询速度。
parquet列式存储
Parquet是一种性能优越的列式存储格式,通常用于海量数据的存储和分析。它最初由Cloudera和Twitter公司共同开发,现在已经成为了Apache软件基金会的顶级项目。
与传统的行式存储不同,Parquet采用按列存储的方式,将同一列的数据存放在一起,这使得Parquet非常适合读取部分数据,而不需要读取全部数据集的场景。此外,Parquet还支持多层次的结构、可变长度的数据类型以及高效的压缩算法,使得它可以同时满足固定模式和半结构化数据的存储需求。
在Parquet的实现中,数据被组织成多个行组(Row Group)和多个数据页(Data Page),每个行组包含多个数据页,每个数据页保存的是同一个列中的固定数目的值。这些页的大小都是固定的,并且可以使用不同的压缩算法进行压缩,包括Gzip、Snappy、LZO等等。
此外,为了提高查询性能,Parquet还提供了一些额外的功能。例如,Parquet文件中的每个数据页都带有各种元数据,这些元数据包括数据页中的最大值、最小值和null值的数量等,可以用于对数据进行过滤和查询优化。此外,Parquet还支持多种编码方式,如Run Length Encoding和Delta Encoding等,这些编码方式可以进一步压缩存储空间,并且减少了存储IO和网络传输。
ORC和Parquet区别
首先,相比于Parquet,ORC在写入和读取方面更加高效。它采用了一些高级技术,例如基于内存的压缩、数据类型推断和多层次索引等,具有更快的数据写入速度和更低的存储空间占用。此外,ORC还支持数据读取Projected I/O和Predicate Pushdown,可以实现仅读取特定列或行,从而减少读取大量无用数据的时间和开销。
其次,ORC在支持动态结构和嵌套数据类型方面表现更加优秀。它可以处理多种复杂的数据类型,包括嵌套的数据结构、变长数组、日期和时间、二进制和字符串等,这使得它适用于存储非常规数据和半结构化数据。
然而,Parquet在支持跨平台查询和集成方面表现更好。虽然ORC也是一种开放源代码的存储格式,但由于其较新且较少受支持,因此可能不如Parquet广泛应用于各种平台和工具。而Parquet则被广泛应用于多种开源和商业分布式计算和分析系统中,例如Apache Spark、Apache Hadoop、Apache Hive和Amazon S3等。
二、ORC和Parquet存储结构
ORC文件结构
一个ORC文件包含称为stripes的行数据组,以及file footer中的辅助信息。在文件的末尾,postscript包含压缩参数和压缩页脚的大小。
默认条带大小为 250 MB。大条带可实现从 HDFS 进行大而高效的读取。
文件页脚包含文件中的条带列表、每个条带的行数以及每列的数据类型。它还包含列级聚合计数、最小值、最大值和总和。
下图说明了 ORC 文件结构:
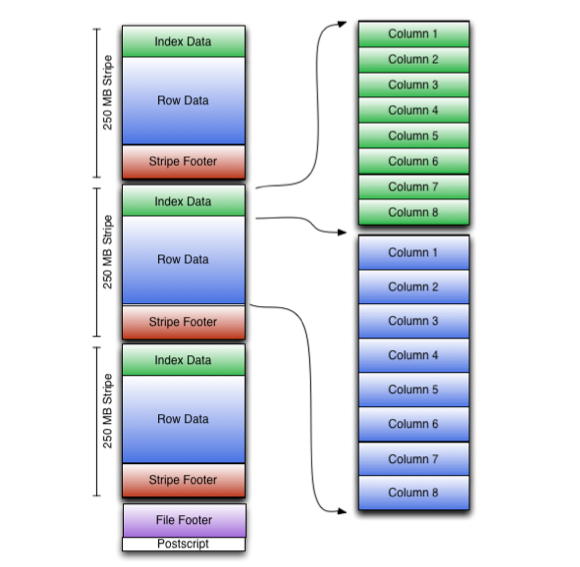
Stripe结构
如图所示,ORC 文件中的每个条带都包含索引数据、行数据和条带页脚。
stripe footer包含流位置的目录。row data用于表扫描。
Index data包括每列的最小值和最大值以及每列中的行位置。也可以包括位域或布隆过滤器。行索引条目提供偏移量,允许在解压缩块中查找正确的压缩块和字节。注意,ORC 索引仅用于选择条带和行组,而不用于回答查询。
具有相对频繁的行索引条目可以在条带内跳行以实现快速读取,即使stripe大小很大。默认情况下,每 10000 行可以跳过一次。
由于能够基于筛选器谓词跳过大量行,因此可以根据表的辅助键对表进行排序,从而大大减少执行时间。例如,如果主分区是事务日期,则可以按州、邮政编码和姓氏对表进行排序。然后,在一个州查找记录将跳过所有其他州的记录。
Parquet文件结构
该格式明确设计为将元数据与数据分开。这允许将列拆分为多个文件,以及让单个元数据文件引用多个Parquet文件。
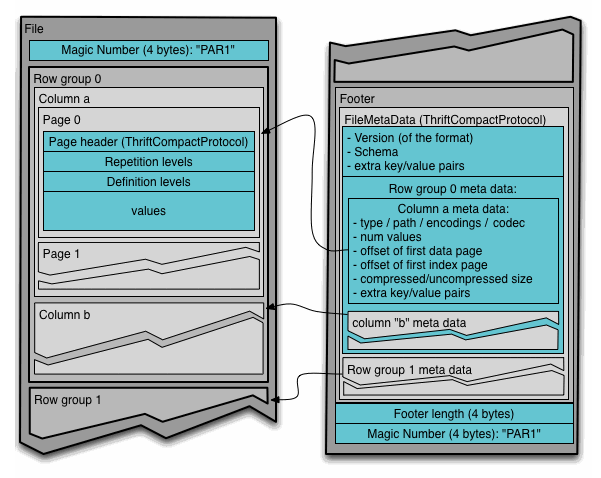
Block (hdfs块):hdfs中的一个块,描述这种文件格式的含义不变。该文件格式旨在在 hdfs 之上很好地工作。
File:必须包含文件元数据的 hdfs 文件。它不需要实际包含数据。
Row group:将数据划分为行的逻辑水平分区。没有保证行组的物理结构。行组由数据集中每一列的列区块组成。
Column chunk:特定列的数据区块。它们位于特定的行组中,并保证在文件中是连续的。
Page:列区块分为多个页面。页面在概念上是一个不可分割的单元(就压缩和编码而言)。可以在列块中交错有多个页面类型。
在层次结构上,文件由一个或多个行组组成。行组每列只包含一个列区块。列块包含一个或多个页面。
总结
ORC和Parquet都是列式存储格式,用于高效地存储和查询大规模数据。相比于Parquet,ORC在写入和读取方面更加高效,支持动态结构和嵌套数据类型,适用于存储非常规数据和半结构化数据。而Parquet在支持跨平台查询和集成方面表现更好,被广泛应用于多种开源和商业分布式计算和分析系统中。不同的应用场景下,可以根据需求选择最合适的存储格式。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









