







欢迎转载,请注明出处https://blog.csdn.net/ZJKL_Silence/article/details/85798935。
本文提出了(基于深度Q-learning 的推荐框架)基于强化学习的推荐系统框架来解决三个问题:
1)首先,使用DQN网络来有效建模新闻推荐的动态变化属性,DQN可以将短期回报和长期回报进行有效的模拟。
2)将用户活跃度(activeness score)作为一种新的反馈信息,不仅仅考虑点击率作为回报。
3)使用Dueling Bandit Gradient Descent方法来进行有效的探索。
当前强化学习中已经提出增加一些随机性到决策中,来寻找新的物品。e-greedy或者UCB主要作为多臂赌博方法,因为e-greedy可能给消费者推荐完全不相关的物品,然而,UCB只有对物品进行多次尝试,才可以得到相对准确的回报估计。这两种方法在短期内可能损害推荐的性能,这里采取更加有效的探索。
本文用竞争赌博梯度下降方法进行探索。通过在当前推荐的邻居候选物品中随机选择一些物品,这样介意避免推荐完全不相关的物品,因此可以保持较好的推荐准确性。
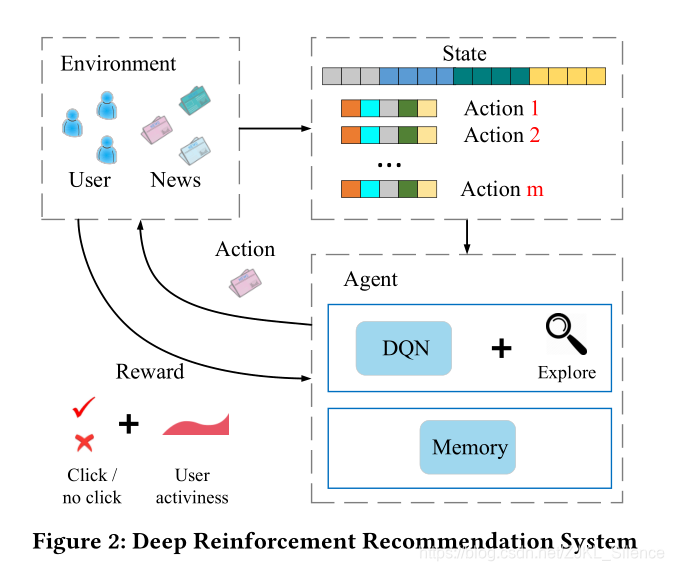
对于上图,描述了强化学习的四个必要因素:
状态:用户的特征
动作:物品(新闻)特征
环境:用户和物品池
回报:点击率和用户的活跃度
强化过程:将用户的连续状态特征表示和连续的物品动作特征表示作为多层深度Q-网络,预测潜在回报。
该框架优点:
1、可以处理高度动态的新闻推荐,由于可以在线更新DQN。同时,DQN网卡可以推断用户和物品之间将来的交互。
2、结合用户的活跃度和来最用户反馈的点击率作为 回报。
3、利用DBGD策略更改推荐多样性。
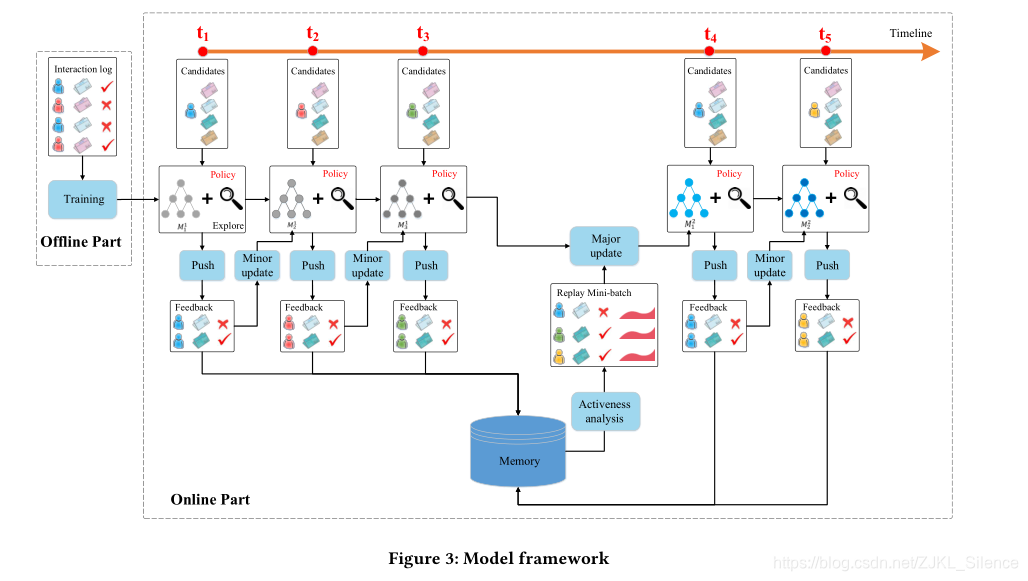
模型框架包括线下阶段和线上阶段:
线下阶段:抽取用户和物品的四种特征。利用用户和物品的点击记录进行训练该网络。
四种特征:新闻特征,进行one-hot编码后的417维度特征;用户特征413*5=2065;用户新闻特征:用户和新闻之间的交互特征25;上下文特征32;
线上学习部分:我们推荐代理G将于用户进行交互,并按照以下方式更新网络:
(1)push:在每个时间戳用户像系统法师弓一个新闻请求,推荐代理G将当前用户和候选的新闻的特征表示作为DQN网络的输入并生成新闻推荐列表L,L的产生是结合当前模型的利用和新颖物品的探索。
(2)反馈:用户u将根据推荐新闻列表L,其点击率做为反馈
(3)次要更新:在每个时间戳之后,先前用户的特征表示,其推荐列表L,反馈B。代理G将通过利用Q网络和探索网络Q’比较推荐的性能。若Q’能够给出较好的推荐,将当前网络朝着Q’网络更新,否则保持Q网络不变。
(4)主要更新:在经过一段时间T后,代理将利用用户的反馈和存储在内存中的用户的活跃度和反馈更新Q网络。因此我们将利用
经验重放技术更新网络。每次更新,代理将抽样批量记录更新模型。
模型的整个回报
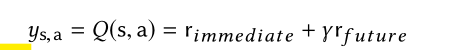
对于DDQN的reward: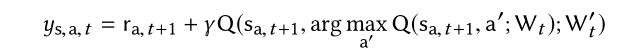
这里t+1是因为回报总是延时;
用户的活跃度
利用用户的生存分析构建用户的活跃度;

利用DBGD算法进行探索

代理G使用当前Q网络产生推荐表L;利用探索网络Q’产生推荐列表L’;在原来Q网络的W基础上,增加小的扰动到当前的Q网络中:
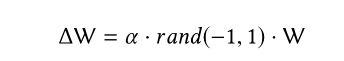
将使用概率交错算法算法首先随机的在L和L’选择物品,假设L被选中,来自列表L的物品i,将通过在L中的排序以确定性的概率放入L’中。然后推荐列表L’作为用户u的推荐列表,并得到反馈B。若利用探索网络Q’获得比较好的反馈,代理将更新Q网络朝着Q’网络进行更新。参数更新如下:
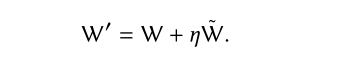














 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









