







A Deep Reinforcement Learning Framework for Rebalancing Dockless Bike Sharing Systems

摘要
自行车共享为旅行提供了一种环保的方式,并在世界各地蓬勃发展。然而,由于用户出行模式的高度相似性,自行车不平衡问题不断发生,尤其是对于无停靠自行车共享系统,对服务质量和公司收入造成重大影响。因此,如何有效地解决这种不平衡已经成为自行车共享运营商的一项关键任务。在本文中,我们提出了一个新的深度强化学习框架来激励用户重新平衡这样的系统。我们将问题建模为一个马尔可夫决策过程,并考虑了空间和时间特征。我们开发了一种新的深度强化学习算法,称为分层强化定价(Hierarchical Reinforcement Pricing)(HRP),它建立在深度确定性策略梯度算法( Deep Deterministic Policy Gradient algorithm.)(DDPG)的基础上。与通常忽略空间信息并严重依赖精确预测的现有方法不同,HRP使用带有嵌入式本地化模块的分治结构(divide-and-conquer structure) 来捕获空间和时间依赖性。我们进行了广泛的实验来评估HRP,基于中国主要的无码头自行车共享公司Mobike数据集。结果表明,HRP的性能接近24时隙前瞻优化,在服务水平和自行车分配方面都优于最先进的方法。当应用于看不见的区域时,它也能很好地传输.
abstract
Bike sharing provides an environment-friendly way for traveling and is booming all over the world. Yet, due to the high similarity of user travel patterns, the bike imbalance problem constantly occurs, especially for dockless bike sharing systems, causing significant impact on service quality and company revenue. Thus, it has become a critical task for bike sharing operators to resolve such imbalance efficiently. In this paper, we propose a novel deep reinforcement learning framework for incentivizing users to rebalance such systems. We model the problem as a Markov decision process and take both spatial and temporal features into consideration. We develop a novel deep reinforcement learning algorithm called Hierarchical Reinforcement Pricing (HRP),which builds upon the Deep Deterministic Policy Gradient algorithm. Different from existing methods that often ignore spatial information and rely heavily on accurate prediction, HRP captures both spatial and temporal dependencies using a divide-and-conquer structure with an embedded localized module. We conduct extensive experiments to evaluate HRP, based on a dataset from Mobike, a major Chinese dockless bike sharing company. Results show that HRP performs close to the 24-timeslot look-ahead optimization, and outperforms state-of-the-art methods in both service level and bike distribution. It also transfers well when applied to unseen areas.
1. Introduction
[待修改】
自行车共享,尤其是无码头自行车共享,正在全世界蓬勃发展。例如,中国自行车共享巨头Mobike已经在国内外部署了700多万辆自行车。自行车共享作为一种环保方式,通过在用户之间共享公共自行车,为人们提供了一种方便的通勤方式,并解决了“最后一英里”的问题(沙欣、古兹曼和张2010)。与传统的对接自行车共享系统(BSS)不同,例如Hubway,自行车只能出租和归还在固定的停靠站,用户可以在任何有效的地方访问和停放共享自行车。这减轻了用户的担心,当他们想使用自行车时,他们会找到空的码头,或者当他们想归还自行车时,他们会进入完全被占用的车站。
然而,由于大多数用户的出行模式相似,BSS的租赁模式导致自行车不平衡,尤其是在高峰时段。例如,人们大多在早上高峰时间从家里骑车去上班。这导致住宅区的自行车非常少,这反过来抑制了潜在的未来需求,而地铁站和商业区由于共享自行车的压倒性数量而瘫痪。由于用户停车位置不受限制,这个问题对于无停靠基站来说被进一步夸大了。这种不平衡不仅会给用户和服务提供商带来严重问题,也会给城市带来严重问题。因此,对于自行车共享提供商来说,高效地重新平衡自行车至关重要,以便更好地为用户服务,并避免堵塞城市人行道和造成自行车混乱。
自行车再平衡面临几个挑战。🐸首先,这是一个资源受限的问题,因为服务提供商通常会为重新平衡系统提出有限的预算。天真地花费预算来增加自行车的供应不会解决问题,也不符合成本效益。此外,由于监管,允许的自行车数量通常是有上限的。其次,🐸由于自行车和用户数量庞大,这个问题在计算上很棘手。第三,🐸用户需求通常是高度动态的,并且在时间和空间上都在变化。第四,🐸如果用户也参与自行车再平衡,再平衡策略需要有效利用预算,激励用户提供帮助,而不需要知道用户的私人成本。
最近有大量关于自行车再平衡的结果,主要集中在两种方法上,即基于车辆的方法(O’Mahony 和 Shmoys2015;Liu 等人 2016;Ghosh、Trick 和 Varakantham 2016;Li, Zheng 和 Yang 2018;Ghosh 和 Varakantham 2017)以及基于用户的方法(Singla 等人,2015 年;Chemlaet al. 2013 年;Fricker 和 Gast 2016 年)。基于车辆的方法利用多辆卡车/自行车拖车在不同区域通过装载或卸载自行车来实现重新定位。但其重新平衡效果在很大程度上取决于需求预测的准确性。此外,由于难以实时调整重新定位计划以满足波动的需求,因此可能不灵活。此外,由于卡车的维护和行驶成本以及劳动力成本,基于卡车的方法会迅速耗尽有限的预算。相比之下,基于用户的方法提供了一种更经济、更灵活的方式来重新平衡系统,通过为用户提供金钱奖励和替代的自行车上车或下车地点。通过这种方式,用户更有动力在邻近地区取车或还车,而不是在自行车或码头短缺的地区。然而,现有的基于用户的方法往往没有在激励政策中考虑空间信息,包括自行车分布和用户分布。此外,用户相关信息,例如步行到另一个位置的费用,也经常是未知的。

在本文中,我们提出了一个深度强化学习框架来激励用户重新平衡无备审的BSS,如图1所示。具体来说,我们将问题视为自行车共享服务运营商和环境之间的相互作用,并将问题表述为马尔可夫决策过程(MDP)。在这个MDP,一个state由供给、需求、到达和其他相关信息组成,每个行动对应于每个地区的一套货币激励措施,以激励用户步行到附近的地方并在那里使用自行车。直接的回报是满足用户请求的数量。我们的目标是最大化长期服务水平,即满足的请求总数,这是自行车共享服务提供商最感兴趣的(林和杨2011)。我们的方法属于多智能体系统中激励策略的主题(薛等,2016;唐2017;蔡等2018)。
为了解决这个问题,我们开发了一种新的深度强化学习算法,称为分层强化定价算法。HRP算法建立在深度确定性策略梯度(DDPG)算法的基础上(Lillicrap等人,2015),使用一般的分层强化学习框架(Dietterich,2000)。我们的想法是将整个感兴趣区域的Q值分解成多个较小区域的子Q值。分解能够有效地搜索策略,因为它解决了由于高维输入空间和时间依赖性而导致的复杂性问题。此外,HRP算法还考虑了空间相关性,并包含一个局部化模块,以纠正子状态和子动作之间的分解和相关性所引入的Q值函数估计偏差。这样做减少了输入空间,减少了训练损失。与现有算法相比,该算法提高了收敛速度,取得了更好的性能。
本文的主要贡献如下:
- 我们提出了一个新的时空自行车再平衡框架,并将问题建模为一个马尔可夫决策过程(MDP),目标是最大化服务水平
- 我们提出了分层强化定价(HRP)算法,该算法决定每次如何向不同的用户付费,以激励他们帮助重新平衡系统
- 我们使用摩拜单车的数据集进行了广泛的实验。 结果表明,HRP 大大优于最先进的方法。 我们还通过与我们提出的离线最优算法进行比较来验证 HRP 的最优性。 我们进一步证明了 HRP 在不同领域的泛化能力。
2. Related Work
Rebalancing approaches随着BSS的最新发展,研究人员开始研究利用大数据的运营问题(刘等,2017;Y ang等人,2016年;陈等2016;李等,2015),其中再平衡是最重要的焦点之一。再平衡方法可以分为三类。第一类采用基于卡车的方法,使用多辆卡车。对于对接的基站系统,这些方法可以静态(刘等人,2016年)或动态(戈什,特里克和瓦拉坎瑟姆,2016年)重新定位自行车。第二类侧重于自行车拖车的使用(O’Mahony和Shmoys,2015年;Ghosh和Varakantham 2017李,郑,杨2018)。第三类侧重于基于用户的再平衡方法(Singla等人,2015年;Chemla等人,2013年;Fricker和Gast 2016)。
Reinforcement learning:深度确定性策略梯度算法(DDPG)(Lilli rap等人,2015)建立在确定性策略梯度算法(Silver等人,2014)的基础上,使用深度神经网络来逼近动作值函数,以提高收敛性。然而,传统的强化学习方法不能扩展到高维输入空间的问题。分层强化学习(Dayan和Hinton 1993)将一个大问题分解成几个由子代理学习的较小的子问题,适用于大规模问题。每个子代理只专注于学习其子DP的子Q值。因此,次级代理可以忽略与其当前决策无关的部分状态(Andre和Russell 2002V an Seijen等人(2017年),以实现更快的学习。
3. Problem Definition
在本节中,我们介绍并形式化了基于用户的自行车再平衡问题,即通过向用户提供货币激励来激励他们帮助重新平衡系统。
考虑一个在空间上分成n个区域的区域,即{r1,r2,…,rn}。我们将一天离散成长度相等的T个时隙,用 T = { 1 , 2 , . . . , T } \mathcal{T} = \{1,2,...,T\} T={1,2,...,T}。让Si(t)表示时隙timeslot t ∈ T t ∈ \mathcal{T} t∈T开始时的区域 r i r_i ri中的供应,即可用自行车的数量。我们也把 S ( t ) = ( S i ( t ) , ∀ i ) S(t) = (Si(t),∀i) S(t)=(Si(t),∀i)表示为供给向量。时隙t期间区域 r i r_i ri骑行的总用户需求和自行车到达分别用 D i ( t ) 和 A i ( t ) Di(t)和Ai(t) Di(t)和Ai(t)表示。我们同样将 D ( t ) = ( D i ( t ) , ∀ i ) 和 A ( t ) = ( A i ( t ) , ∀ i ) D(t) = (Di(t),∀i)和A(t) = (Ai(t),∀i) D(t)=(Di(t),∀i)和A(t)=(Ai(t),∀i)分别表示为需求向量和到达向量。让 d i j ( t ) d_{ij}(t) dij(t)表示在时隙t期间打算从区域 r i r_i ri到区域 r j r_j rj的用户数量。
Pricing algorithm. 在每个时隙t,对于在他的当前区域 r i r_i ri中找不到可用自行车的用户,定价算法 A \mathcal{A} A建议他在 r i r_i ri的 相邻区域(用 N ( r i ) N(r_i) N(ri)表示) 中选择自行车。同时, A \mathcal{A} A还向用户提供价格激励 p i j ( t ) p_{ij}(t) pij(t)(按照用户到达的顺序),激励他步行到邻近区域 r j ∈ N ( r i ) r_j∈ N(ri) rj∈N(ri)去取自行车 b h j b_{hj} bhj,其中 b h j b_{hj} bhj表示在 r j r_j rj的第 h h h辆自行车。 A \mathcal{A} A有一个总的再平衡预算 b b b .当预算完全耗尽时, A \mathcal{A} A不能再进一步拨备。
User model对于区域ri中的每个用户
u
k
u_k
uk,如果当前区域中有可用的自行车,他会选择最近的一辆。否则,如果他从里走到邻近地区去取自行车,就要付步行费。我们用
c
k
(
i
,
j
,
x
)
c_k(i,j,x)
ck(i,j,x)表示成本,其中x是从他的位置到自行车的步行距离。我们假设它具有以下形式:
c
k
(
i
,
j
,
x
)
=
{
0
i
等
于
j
α
x
2
r
j
是
r
i
的
邻
居
区
域
+
∞
e
l
s
e
(1)
c_k(i,j,x)=\begin{cases}0 & i 等于 j\\\alpha x^2 &r_j是r_i的邻居区域\\+\infty & else \ \end{cases}\tag{1}
ck(i,j,x)=⎩⎪⎨⎪⎧0αx2+∞i等于jrj是ri的邻居区域else (1)
这种特殊形式的
c
k
(
i
,
j
,
x
)
c_k(i,j,x)
ck(i,j,x)是由在(Singla等人,2015年)进行的一项调查推动的,该调查显示用户成本具有凸形结构。请注意,该成本对每个用户都是私有的,并且服务提供商不知道成本函数。对于在当前区域
r
i
r_i
ri找不到可用自行车的用户,如果他收到一个报价
(
p
i
j
(
t
)
,
b
h
j
)
(p_{ij}(t),b_{hj})
(pij(t),bhj)并接受它,他将获得一个效用
p
i
j
(
t
)
−
C
k
(
i
,
j
,
x
)
p_{ij}(t)-C_k(i,j,x)
pij(t)−Ck(i,j,x)。因此,用户将选择并挑选他可以获得最大效用的自行车
b
h
j
b_{hj}
bhj,并收取价格激励
p
i
j
(
t
)
p_{ij}(t)
pij(t)。如果没有报价导致非负效用,用户将不会接受它们中的任何一个,导致未满足的请求。
Bike dynamics让
x
i
j
l
(
t
)
x_{ijl}(t)
xijl(t)表示在时隙
t
t
t区域
r
i
r_i
ri的用户乘用
r
j
r_j
rj区域的自行车骑行到
r
l
r_l
rl区域。每个区域
r
i
r_i
ri的供应动态可以表示为:
S
i
(
t
+
1
)
=
S
i
(
t
)
−
∑
j
=
1
n
∑
l
=
1
n
x
j
i
l
(
t
)
+
∑
m
=
1
n
∑
j
=
1
n
x
m
j
i
(
t
)
(2)
S_i(t+1)=S_i(t)-\sum_{j=1}^n\sum_{l=1}^nx_{jil}(t)+\sum_{m=1}^n\sum_{j=1}^nx_{mji}(t)\tag{2}
Si(t+1)=Si(t)−j=1∑nl=1∑nxjil(t)+m=1∑nj=1∑nxmji(t)(2)
等式(2)中的第二项和第三项表示区域
r
i
r_i
ri中出发和到达的自行车数量。请注意,自行车在不同地区之间有一个旅行时间(travel time)。
objective我们的目标是开发一个最优定价算法
A
\mathcal{A}
A,激励拥堵区域的用户到邻近区域取车,从而在平衡预算
B
B
B的前提下,最大化服务水平,即满足的请求总数。
4. Hierarchical Reinforcement Pricing Algorithm
在这一部分,我们提出了我们的分层强化定价(HRP)算法,激励用户有效地重新平衡系统。
4.1 MDP Formulation
我们的问题是一个在线学习问题(这里应该值得是on-policy),其中一个agent与environment交互。因此,它可以被建模为一个马尔可夫决策过程(MDP),由5个变量 ( S , A , P , R , R , γ ) (S,A,P,R,R,γ) (S,A,P,R,R,γ)定义,其中 S 和 A S和A S和A表示状态和动作的集合, P r P_r Pr表示转移矩阵, R R R表示即时奖励, γ γ γ表示折扣因子。在我们的问题中,在每个时间步长t,🐸状态 s t = ( S ( t ) , D ( t − 1 ) , A ( t − 1 ) , E ( t − 1 ) , R B ( t ) , U ( t ) ) s_t= (S(t),D(t-1),A(t-1),E(t-1),RB(t),U(t)) st=(S(t),D(t−1),A(t−1),E(t−1),RB(t),U(t))。这里,S(t)是每个区域的当下供应,而RB(t)是当前剩余预算。d(t1)、A(t1)和E(t1)是每个地区上一个时隙末的的需求、到达和费用。U(t)表示在过去固定数量的时间步长内,每个地区的未服务率。自行车共享服务运营商采取的🐸动作 a t = ( p 1 t , . . . p n t ) a_t= (p_{1t},...p_{nt}) at=(p1t,...pnt),并且接受的🐸即使报酬为 R ( s t , a t ) R(s_t,a_t) R(st,at),它表示在时隙t整个区域R的满足请求的数量。
具体来说, p i t p_{it} pit表示区域 r i r_i ri在时隙 t t t的价格。 P r ( s t + 1 ∣ s t , a t ) P_r(s_{t+1}|s_t,a_t) Pr(st+1∣st,at)表示在 a t a_t at作用下从状态st到状态st+1的🐸转移概率。带有参数θ的🐸策略函数 π θ ( S t ) \pi_θ(S_t) πθ(St)将当前状态映射为确定性动作。总的目标是找到一个最优策略,使状态 s 0 s_0 s0策略 π θ \pi_{\theta} πθ下的🐸总折扣奖励最大化,,用 J π θ = E [ ∑ k = 0 ∞ γ k R ( a k , s k ) ∣ π θ , s 0 ] J_{\pi θ}= \mathbb{E}[\sum_{k=0}^{\infty} γ^kR(a_k,s_k)|\pi _θ,s0] Jπθ=E[∑k=0∞γkR(ak,sk)∣πθ,s0]表示,其中γ ∈ [0,1]表示折扣系数。在策略 π θ \pi_θ πθ下的动作 a t a_t at和状态 s t s_t st的值函数表示为 Q π θ ( s t , a t ) = E [ ∑ k = t ∞ γ k − t R ( s k , a k ) ∣ π θ , s t , a t ] Q^{\pi \theta}(s_t,a_t)=\mathbb{E}[\sum_{k=t}^{\infty}\gamma^{k-t}R(s_k,a_k)|\pi_{\theta},s_t,a_t] Qπθ(st,at)=E[∑k=t∞γk−tR(sk,ak)∣πθ,st,at]。请注意, J π θ J_{πθ} Jπθ是目标服务目标的折扣版本( a discounted version of the targeting service level objective),当γ接近1时,它将作为一个近似。实际上,我们的实验结果表明,当γ = 0.99时,我们的算法非常接近服务水平目标的离线最优,证明了该方法的有效性.
4.2The HRP Algorithm
我们这个问题的关键挑战之一,就是它有一个连续的高维动作空间,这个空间随着区域的数量呈指数级增长,并且遭受“维度诅咒”。为了解决这个问题,我们提出了HRP算法,如算法1所示。受分层强化学习和DDPG的启发,同时捕捉时间和空间相关性的HRP算法能够解决现有算法的收敛问题并提高性能。

Require:随机初始化权重
θ
,
μ
\theta,\mu
θ,μ:分别是演员网络
a
=
π
θ
(
s
)
a=\pi_{\theta}(s)
a=πθ(s)和评论家网络
Q
μ
(
s
,
a
)
Q_{\mu}(s,a)
Qμ(s,a)中的NN的参数
- 对 target_actor网络 π ′ \pi ' π′的权重 θ ′ ← θ \theta'\leftarrow \theta θ′←θ 和 target_critic 网络 Q ’ Q’ Q’的 的权重 μ ′ ← μ \mu' \leftarrow \mu μ′←μ进行更新
- 初始化 经验池 B \mathcal{B} B :预先将数据收集放入经验池
- for episode in range(M):
- 初始化 一个 随机过程 N \mathcal{N} N(例如高斯噪声) 用来探索(探索的含义体现,策略网络输出的动作为确定性动作 π θ ( s ) \pi_{\theta}(s) πθ(s),添加高斯噪声 N t \mathcal{N}_t Nt可探索空间)动作空间,并 接受初始状态 s1
- for step t in range(T):
探索和抽样
- env中 选择并执行 a t = π θ ( s t ) + N t a_t=\pi_{\theta}(s_t)+\mathcal{N}_t at=πθ(st)+Nt动作,返回得到报酬 R t R_t Rt和下一状态 S t + 1 S_{t+1} St+1
- replay memory中,将env获得经验 ( s t , a t , R t , s t + 1 ) (s_t,a_t,R_t,s_{t+1}) (st,at,Rt,st+1)存入 经验池 中
- replay memory中, 从经验池 B \mathcal{B} B 中抽取 batch个经验
获得Q(当前状态,当前动作)
- critic network中,对 每个区域 r j r_j rj 计算分解后的Q值 Q μ j j ( s j t , P j t ) Q^j_{\mu j}(s_{jt},P_{jt}) Qμjj(sjt,Pjt)(其中, s j t , P j t s_{jt},P_{jt} sjt,Pjt分别表示区域 r j r_j rj在时间 t t t的子状态和子动作)
- critic network中,对 每个区域 r j r_j rj的局部模块,计算偏差矫正项 f j ( s j t , N S ( s t , r j ) , p j t ) f_j(s_{jt},NS(s_t,r_j),p_{jt}) fj(sjt,NS(st,rj),pjt)(其中, N S ( s i , r j ) NS(s_i,r_j) NS(si,rj)表示的是在时间t,区域 r j r_j rj的邻接区域的状态集)
- 根据公式 ∑ j = 1 n Q μ j j ( s j t , p j t ) + f j ( s j t , N S ( s t , r j ) , p j t ) \sum_{j=1}^nQ^j_{\mu j}(s_{jt},p_{jt})+f_j(s_{jt},NS(s_t,r_j),p_{jt}) ∑j=1nQμjj(sjt,pjt)+fj(sjt,NS(st,rj),pjt)计算当前的Q(状态,动作)
得到Q(下一状态,下一动作)
- target_actor中,输入下一状态 s t + 1 s_{t+1} st+1,输出下一动作 a t + 1 a_{t+1} at+1: a t + 1 ′ = π θ ′ ( s t + 1 ) a_{t+1}'=\pi_{\theta '}(s_{t+1}) at+1′=πθ′(st+1)
- target_critic中,计算每个区域 r j r_j rj的分解子Q值: Q μ j ′ j ( s ( t + 1 ) , p j ( t + 1 ) ′ ) Q^j_{\mu j'}(s_{(t+1)},p'_{j(t+1)}) Qμj′j(s(t+1),pj(t+1)′)
- target_critic中,计算每个区域 r j r_j rj的局部模块的偏差矫正项: f j ( s j ( t + 1 ) , N S ( s t + 1 , r j ) , p j ( t + 1 ) ′ ) f_j(s_{j(t+1)},NS(s_{t+1},r_j),p_{j(t+1)}') fj(sj(t+1),NS(st+1,rj),pj(t+1)′)
- 根据公式 ∑ j = 1 n Q μ j j ( s j t , p j t ) + f j ( s j t , N S ( s t , r j ) , p j t ) \sum_{j=1}^nQ^j_{\mu j}(s_{jt},p_{jt})+f_j(s_{jt},NS(s_t,r_j),p_{jt}) ∑j=1nQμjj(sjt,pjt)+fj(sjt,NS(st,rj),pjt)计算下一时隙的Q(下一状态,下一动作)
更新
- 设置 y t = R t + γ Q μ ′ ( s t + 1 , a t + 1 ′ ) y_t=R_t+\gamma Q'_{\mu}(s_{t+1},a'_{t+1}) yt=Rt+γQμ′(st+1,at+1′)
- 根据公式 L ( Q π θ ) = E s t ∼ ρ π , a t ∼ π [ ( Q μ ( s t , a t ) − y t ) 2 ] L(Q^{\pi \theta})=\mathbb{E}_{s_t \sim \rho_{\pi},a_t \sim \pi}[(Q_{\mu}(s_t,a_t)-y_t)^2] L(Qπθ)=Est∼ρπ,at∼π[(Qμ(st,at)−yt)2](即均方差)得到的loss.minimize去更新critic network。
- 根据公式 ∇ θ J π θ = E s ∼ ρ π θ [ ∇ θ π θ ( s ) ∇ a Q μ ( s , a ) ∣ a = π θ ( s ) ] \nabla_{\theta}J_{\pi \theta}=\mathbb{E}_{s\sim \rho_{\pi \theta}}[\nabla_{\theta}\pi_{\theta}(s)\nabla_aQ_{\mu}(s,a)|_{a=\pi_{\theta}(s)}] ∇θJπθ=Es∼ρπθ[∇θπθ(s)∇aQμ(s,a)∣a=πθ(s)](策略的梯度)去更新actor netwok(在更新ac-nn时,其cri-nn的参数时不变的)
- target_netwok的参数采用软更新方式: θ ′ = τ θ + ( 1 − τ ) θ ′ , μ ′ = τ μ + ( 1 − τ ) μ ′ \theta '=\tau\theta +(1-\tau)\theta ',\quad \mu '=\tau\mu+(1-\tau)\mu ' θ′=τθ+(1−τ)θ′,μ′=τμ+(1−τ)μ′
具体来说,我们将整个区域的Q值分解为每个区域的子Q值。然后,可以根据sub-Q值得估计量得相加组合 ∑ j = 1 n Q μ j j ( s j t , p j t ) \sum_{j=1}^nQ_{\mu j}^j(s_{jt},p_{jt}) ∑j=1nQμjj(sjt,pjt)来估计Q值,其中 s j t , p j t s_{jt},p_{jt} sjt,pjt表示是区域 r j r_j rj在时隙 t t t的子状态和子动作, μ j \mu_j μj是估计量的参数。对于每个时间步长,当前状态取决于以前的状态,因为人们会动态地选择和返回自行车。为了捕捉状态中呈现的顺序关系,一个想法是使用LSTM训练每个子代理短期记忆(LSTM)(Hochriter和Schmidhuber 1997)单元,可以捕捉复杂的顺序依赖关系。然而,LSTM保持着复杂的体系结构,需要训练大量的参数。请注意,分层强化学习的一个关键挑战是估计准确的子Q值,这将导致准确的整体Q值估计。因此,我们采用了门控循环单位(GRU)模型(Cho等人,2014),这是LSTM的简化变体。这种结构更紧凑,参数更少,从而实现更高的采样效率,并避免过度拟合。
然而,由于每个区域及其相邻区域的依赖性,应用直接分解会导致较大的偏差。在我们的例子中,用户可能会在当前区域之外的邻近区域骑自行车,导致不同区域的行为是耦合的。因此,我们需要考虑这一领域的空间特征。我们通过嵌入局部化模块来整合空间信息,从而解决了 Q μ ( s t , a t ) 和 j ∑ j = 1 n Q μ j j ( s j t , p j t ) Q _{\mu}(s_t,a_t)和j\sum_{j=1}^nQ^j_{\mu j}(s_{jt},p_{jt}) Qμ(st,at)和j∑j=1nQμjj(sjt,pjt)的偏差。对于每个区域rj,局部化模块(由fj表示)不仅采用状态 s j t s_{jt} sjt和动作 p j t p_{jt} pjt,还采用由)其相邻区域的状态 N S ( s t , r j ) NS(s_t,r_j) NS(st,rj)作为输入。具体而言, f j f_j fj是由一个神经网络近似,该网络由两个完全连接的层组成,用于偏差校正。因此,我们通过下式估计 Q μ ( s t , a t ) Q_{\mu} (s_t,a_t) Qμ(st,at):
∑ j = 1 n Q μ j j ( s j t , p j t ) + f j ( s j t , N S ( s t , r j ) , p j t ) (3) \sum_{j=1}^nQ^j_{\mu j}(s_{jt},p_{jt})+f_j(s_{jt},NS(s_t,r_j),p_{jt})\tag{3} j=1∑nQμjj(sjt,pjt)+fj(sjt,NS(st,rj),pjt)(3)
图2显示了我们提出的在大状态空间和大动作空间中加速搜索过程的网络架构。从形式上讲,HRP算法的关键组成部分描述如下:

看图解析:
-
首先看虚线表示划分为三个模块:🐸State S t S_t St ,🐸 Actor Network π θ \pi _{\theta} πθ ,🐸 Critic Network Q μ Q_{\mu} Qμ.
-
关于 State S t S_t St 的猜想。首先明确的是一个小方格对应的是自行车网络中的grid,其方格的排列方式对应现实中的grid的排列方式。关于多个 方阵和 ⋯ \cdots ⋯的猜测有两个:
- ⋯ \cdots ⋯关于时间上的排序,理由是因为下面直接 输入 GRU中,是一个关于时间数轴的抓取。但矛盾的是 用虚线框起来的是明显表示 在 t t t时刻的一个状态,以及每个站点存在多个特征。也就引出第二个猜测。
- ⋯ \cdots ⋯ 是关于节点特征的一个排序,参考Fig1中的State具有多个方阵,更倾向于是每个节点不仅仅有一个特征,而是多维特征。使用GRU对这个多维特征进行信息的筛选与重组。
-
关于 Actor Network 的猜想。首先可以明确对于每个节点来说是分开训练的,先经过GRU,在经过sub-NN,最后获得每个节点的Action值
- 即 节点 v v v的在 t t t时刻的特征为 S t v = ( s u p p l y , d e m a n d , a r r i v a l ) S_t^v=(supply,demand,arrival) Stv=(supply,demand,arrival),经过GRU后变为 S ˉ t v = ( s u p p l y ˉ , d e m a n d ˉ , a r r i v a l ˉ ) \bar{S}_t^v=(\bar{supply},\bar{demand},\bar{arrival}) Sˉtv=(supplyˉ,demandˉ,arrivalˉ));再次经过sub-NN后得到 a t v a_t^v atv.
- 对所有的节点进行线性组合: a t = ( a t 1 , . . . , a t v , . . . , a t n ) a_t = (a_t^1,...,a_t^v,...,a_t^n) at=(at1,...,atv,...,atn)或描述为 = ( p t 1 , . . , p t i , . . . , p t j , . . , p t n ) =(p_t^1,..,p^i_t,...,p_t^j,..,p_t^n) =(pt1,..,pti,...,ptj,..,ptn)这里为线性组合而不是加减运算的原因,在与下面有 ∑ \sum ∑符号表示加法,从而反推不是数学上的加减。
- 参数 θ \theta θ:在Alg1中第一行中表示,对 Actor Network 的 参数 θ \theta θ进行初始化,并没有明确指出是对 Actor Network中的NN中的参数进行初始化。所以猜测: θ \theta θ是指GRU和sub-actor-NN的所有参数。
- GRU部分的参数:基于以上猜测正确的基础上,GRU的输出空间的维数=输入空间的维度(根据上面的例子是 3=3)。关于输入的形状(时间窗口,特征维数),特征维度应该是1,而时间窗口<输入空间的维度,如果基于减少划分时间窗口的工作量上来说,那么时间窗口猜测为1.
-
关于 Critic Network 的猜想。首先可以明确的是最后的 ∑ \sum ∑符号,是对每个节点以及交叉节点预测值最后的求和。
- 对于单个节点 v v v来说,有状态 S t v S_t^v Stv和经过Actor Network后得到的 动作值 p t v p_t^v ptv,融合后共同输入 GRU,再输入 sub-critc-NN,获得节点 v v v的未曾修正的状态-动作价值 f v f_v fv.从GRU的输入空间的维度可以看出在Actor和Critic中的都先经过GRU结构,但却不相同。
- 对于交叉节点来说,有节点 v v v的状态 S t v S_t^v Stv和邻居 S t v 1 S_t^v1 Stv1、 S t v 2 S_t^v2 Stv2、 S t v 3 S_t^v3 Stv3、 S t v 4 S_t^v4 Stv4,以及 v v v的动作值 p t v p_t^v ptv融合后共同输入一个 Local-NN,最后获得矫正值 Q μ j j Q^j_{\mu j} Qμjj.
The actor:演员网络表示由θ参数化的策略ψθ。它使用随机梯度上升使Jπθ最大化。特别地,θ上的Jπθ的梯度由下式给出:
∇
θ
J
π
θ
=
E
s
∼
ρ
π
θ
[
∇
θ
π
θ
(
s
)
∇
a
Q
μ
(
s
,
a
)
∣
a
=
π
θ
(
s
)
]
(4)
\nabla_{\theta}J_{\pi \theta}=\mathbb{E}_{s\sim \rho_{\pi \theta}}[\nabla_{\theta}\pi_{\theta}(s)\nabla_aQ_{\mu}(s,a)|_{a=\pi_{\theta}(s)}]\tag{4}
∇θJπθ=Es∼ρπθ[∇θπθ(s)∇aQμ(s,a)∣a=πθ(s)](4)
其中
ρ
π
θ
\rho _{\pi θ}
ρπθ表示状态分布。
The critic:批评网络以国家立场行动作为输入,并输出行动值。具体而言,评论家通过最小化以下损失来近似行动价值函数Qπθ(s,a)(Lilli rap等人,2015年):
L
(
Q
π
θ
)
=
E
s
t
∼
ρ
π
,
a
t
∼
π
[
(
Q
μ
(
s
t
,
a
t
)
−
y
t
)
2
]
(5)
L(Q^{\pi \theta})=\mathbb{E}_{s_t \sim \rho_{\pi},a_t \sim \pi}[(Q_{\mu}(s_t,a_t)-y_t)^2]\tag{5}
L(Qπθ)=Est∼ρπ,at∼π[(Qμ(st,at)−yt)2](5)
where
y
t
=
R
(
s
t
,
a
t
)
+
γ
Q
μ
′
′
(
s
t
+
1
,
π
θ
′
′
(
s
t
+
1
)
)
.
y_t=R(s_t,a_t)+\gamma Q'_{\mu '}(s_{t+1},\pi '_{\theta '}(s_{t+1})).
yt=R(st,at)+γQμ′′(st+1,πθ′′(st+1)).
5. Experiments
5.1 Dataset
5.2 Experimental Setup
根据Mobike的轨迹数据集,我们获得了用户请求和到达的时空信息。我们观察到,根据数据集,不同工作日的需求曲线遵循非常相似的模式,一天中的分布是双峰的,峰值对应于早上和晚上的高峰时间。因此,我们汇总所有工作日需求,以恢复一天的总需求。每天由24个时隙组成,每个时隙为1小时。我们每分钟为用户请求提供服务,其中用户请求直接从数据中提取,而其起始位置(经度和纬度)在起始区域中遵循统一分布。为了在一天开始时确定自行车的初始分布,我们采用了大多数自行车共享运营商(例如:。GMobike,Ofo)雇佣员工重新分配自行车。Ri地区的初始自行车数量设置为Ri地区总供应量与总需求量与整个地区总需求量之比的乘积。然后,从数据中(从相应区域中的自行车位置)随机抽取每个区域的初始自行车位置。用户根据定义的用户模型响应系统,其中选择等式(1)中成本函数的参数α,以便成本范围为[0 RM B,5 RM B]。这是根据(Singla et al.2015)进行的一项调查选择的,该调查显示成本在0到2欧元之间,我们根据用户的购买力进行换算。根据Mobike的数据,中国的订单总数约为2000万份,总供应量为。E在中国,自行车的数量将达到365万辆。由于我们无法直接从数据中获取总供应量,因此我们将总供应量设置为O×3.65 20(O是我们系统中的订单数)。由于初始供给会影响Mobike系统中固有的不平衡程度,因此我们在实验中改变这个数字来评估这种影响。我们使用一阶近似计算未观测到的需求损失数量(O’Mahony和Shmoys 2015)。
5.2.1 HRP算法的配置
对于状态表示,我们选择U(t)的固定过去时间步数为8。比较是公平的,因为超参数与强化学习算法的比较相同,遵循(Lillicrap et al.2015)的配置。我们在每个设置中训练100集的算法,其中每个集由24N个步骤组成(N表示天数)。之后,20集用于测试。
5.3 Evaluation Metric
我们提出了一种称为“减少的非服务比率”的性能评估指标。与服务水平相比,这种选择可以更好地描述在未服务事件中定价算法相对于原始系统(无货币激励)的改进(Singla等人,2015)。
5.3.1 定义1.(减少的非服务比率)
算法A的减少的非服务数量是Mobike下的非服务事件数量(U N)与A,i的非服务事件数量(U N)之间的差异。Edun(A)=U N(Mobike)− 联合国(A)。2 A的减少的不服务比率定义为dur(A)=dun(A)un(Mobike)×100%
5.4 Baselines
- 随机定价算法(Random):在预算约束下随机分配货币激励
- OPT-FIX(Goldberg、Hartline和Wright,2001):一种离线算法,在充分先验用户成本信息的情况下最大化接受率。
- DBP-UCB(Singla et al.2015):一种基于用户的再平衡的最先进方法,应用了多武装bandit框架。
- DDPG (Lillicrap et al. 2015)
- HRA(Van Seijen等人,2017):一种直接采用奖励分解的强化学习算法
- 离线最优:一种定价算法,在事先已知用户成本的情况下,在预算约束下最大化服务水平,作为任何在线定价算法的上限。为了降低公式的复杂性,我们假设旅行在其开始的相同时间段(1小时)内结束。3在我们与离线优化的比较中,由于计算复杂性,我们假设用户从一个区域到另一个区域的成本对于每个时隙都是相同的,如果rj是ri的相邻区域,则定义为sck(i,j,x)=cij(t),式中,cij(t)独立于在RJ(而非数据集时隙t中定义为公式(1)的当前区域)内取车的用户成本的经验分布。然后,该问题可以表述为以下说明:U N(Mobike)是通过模拟Mobike的原始系统来计算的。3否则,必须将时隙设置为1分钟,从而导致复杂度过大的整数线性规划。请注意,模型和模拟不依赖于假设。lowing整数线性规划:
公式(6-11)
约束条件(8)保证对于任何时隙,RIR中用于RLI的用户数量不大于rito rl的需求。限制条件(9)意味着,在RJN提货的自行车数量不超过该地区的自行车供应量。约束(10)确保服务提供商花费的资金受到B的限制。约束条件(11)适用于自行车供应的动态。
5.5 Performance Comparison
我们首先比较了HRP和强化学习的基线,以分析趋同的问题。接下来,我们将HRP与不同的预算和供应进行比较,以评估其在一天内的有效性。然后,我们分析了长期绩效。最后,我们将HRP和离线优化方案进行了比较,并对其泛化能力进行了评估
5.5.1 培训损失
图4(a)显示了HRP、HRA和DDPG下的培训损失。正如预期的那样,DDPG由于高维输入空间而发散。值得注意的是,HRA偏离,训练损失更大。这是由于子MDP之间独立性的不切实际假设,导致Q值函数的估计有偏差。HRP的表现优于两者,并且能够趋同。
5.5.2 不同预算约束的影响
图4(b)显示了在不同预算约束下每种算法的非服务率降低。DDPG在不同的预算级别上表现相似,因为它无法学会在如此大的输入空间中有效地使用预算。由于分解,HRA的性能优于DDPG。HRP将联合国服务比率降低43%− 63%,在所有预算水平下都优于其他算法。OPT-FIX和DPB-UCB低于HRP的原因是它们不考虑空间信息,只关注优化接受率。
5.5.3 实现更好的自行车分销
为了分析一天中的再平衡效应,我们使用Kullback-Leibler(KL)测量了一天结束时自行车的分布如何偏离一天开始时的值 散度度量(Kullback和Leibler 1951)。我们模拟了Mobike的原始系统(没有货币激励),得到其KL分歧水平为0.554。如表1所示,OPT-FIX得到的自行车分布与初始自行车分布最为不同。原因可能是OPT-FIX在最大化接受率方面过于激进,这可能会恶化自行车分销。HRP优于所有现有算法,KL散度值为0.548,甚至小于Mobike的值。这表明HRP能够在一天结束时改善自行车分配。
5.5.4 供应变化的影响
除了改变预算外,还值得研究HRP在不同供应水平下的表现,以评估其稳健性。结果如图5(a)所示。直观地说,当供应有限时,问题更具挑战性,这可能导致较大的联合国服务率。Random和DBP-UCB的性能都很差,而OPT-FIX、DDPG和HRA的性能几乎相同。HRP的表现明显优于其他公司,达到47%− 联合国服务比率下降60%,表明其对不同总供给的鲁棒性。
5.5.5 长期表现
除了分析一天的影响外,我们还通过改变天数来评估长期绩效。我们将HRP与两种最具竞争力的算法HRA和OPT-FIX进行比较,使用减少的联合国服务数量,从1天到5天。如图5(b)所示,HRP优于其他算法。随着天数的增加,性能差距也越来越大。这是因为HRP可以实现更好的自行车分配,如前一节所述,并且它可以最大化长期回报。读者请参阅补充资料,以了解我们对结果的详细分析。
5.5.6 Optimality
我们现在提供与离线最优方案的比较结果。为了避免计算和内存开销,我们在由3×3个具有最高请求密度的区域组成的较小区域上进行比较,以评估HRP在最拥挤区域的性能。我们将HRP和HRA与离线优化进行比较, 通过调整时隙V的不同值。V时隙优化意味着,对于每一个V时隙,我们使用V horizons优化离线程序。直观地说,V越大,性能越好。在本次评估中,对每种算法的400次独立运行的结果进行平均。图6(a)表明,HRP的性能非常接近24时隙优化,而HRA仅执行接近4时隙优化。
5.5.7 Generalization
现在,我们研究HRP是否能很好地转移。E在特定领域接受过培训,但在应用到新领域时仍表现良好。由于数据集只包含上海的轨迹,我们将整个区域划分为更小的区域,每个区域由3×3个区域组成,以生成更多的区域。我们在某个区域培训HRP和HRA,然后在其他区域进行测试。图6(b)显示了所有地区人力资源规划和人力资源管理的累积密度函数(CDF)对联合国服务比率下降的影响。HRP可以达到40%− 在80%的测试区域内,80%的非服务比率降低。这表明HRP可以很好地推广到以前从未见过的新领域。请注意,HRP曲线严格位于HRA右侧,表明HRP比HRA更具普遍性。
6.Conclusion
我们提出了一个深度强化学习框架,鼓励用户重新平衡无码头自行车共享系统。我们提出了一种新的深度强化学习算法,称为分层强化定价(HRP)。HRP维护一个分而治之的结构,可以处理复杂的时间依赖性。它还嵌入了一个本地化模块,以更好地估计Q值,这可以捕获空间依赖关系。我们基于Mobike的真实数据集对HRP进行了广泛的实验,Mobike是中国一家大型无码头自行车共享公司。结果表明,HRP优于最先进的方法。
至于未来的工作,一个有趣的扩展是将我们的算法部署在现实世界的自行车共享系统中。为了适应全年不断变化的环境,可以首先使用最新收集的数据更新模拟器,然后每隔固定天数使用更新后的模拟器离线培训HRP。经过培训后,可以在网上采用新政策。还可以考虑在用户反馈模型E中考虑更多的因素。G旅行距离和一天中的时间。
附录.A: HRP的Model

[受DQN的启发进行HRP]
理论:
- 对环境产生的 奖励函数
R
e
n
v
R_{env}
Renv(也就是真实的目标数据)进行拆分;拆分的方法不唯一,最优的标准是每个奖励函数进设计少量的节点的状态。

- 每个环境奖励函数 R k ( s , a ) R_k(s,a) Rk(s,a)对应一个代理商产生一个预测奖励函数 Q i ( s , a ; θ ) Q_i(s,a;\theta) Qi(s,a;θ).为了得到一个 multiple action-value,一个聚合操作是指将不同的代理商对当前状态产生的action-value接受并组合成一组动作值,并使用相同的线性组合。从而获得 HRA的预测的奖励函数 Q H R A Q_{HRA} QHRA。

3.在当前分割方法下的loss函数以及相关理解。

4. 优化损失函数后获得最优解
Q
H
R
A
∗
(
s
,
a
)
Q^*_{HRA}(s,a)
QHRA∗(s,a)。

5.其他组件介绍:聚合操作的其他方法;目标更新的其他公式。

6.涉及到相同分解的原理证明。

model architecture:
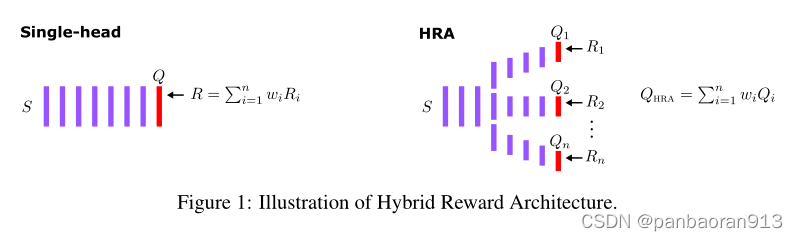
7.个人理解
n个agent并不代表着n个节点。

















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









