







强化学习
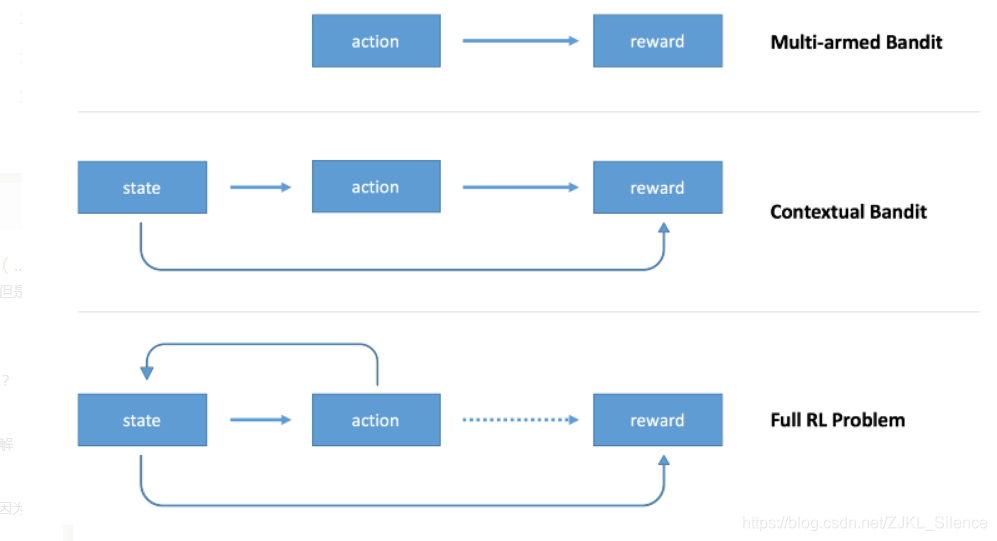
上图:多臂赌博机问题中,只有行动影响回报。中图:上下文赌博机问题中,状态和行动都影响回报。下图:完备强化学习问题中,行动影响状态,回报可能在时间上延迟。
赌博机
agent集中精力去学习对应的每种行动对应的回报,并保证我们总是选择最优的那些行动。在强化学习术语中,这叫做学习一个策略(Learn a policy)。
(1)我们将使用一种称为策略梯度(policy gradient)的方法,即我们将用一个简单的神经网络来学习如何选择行动,它将基于环境的反馈通过梯度下降来调整它的参数。
(2)agent会学习价值函数(value function),相比于学习给定状态下的最优行动,agent会学习预测一个agent将处于的给定状态或者采取的行动多么好。而这两种方法都可以让agent表现优异,不过策略梯度方法显得更加直接一点。
策略梯度
理解策略梯度网络的方法就是:它其实就是一个会生成明确输出的神经网络。在赌博机的例子里,我们不需要基于任何状态来说明这些输出。因此,我们的网络将由一系列的权重构成,每个权重都和每一个可以拉动的赌博机臂相关,并且会展现出我们的agent认为拉动每个臂分别会对应多么好的结果。如果我们初始化权重为1,那么我们的agent将会对每个臂的潜在回报都非常乐观。
损失函数
Loss=−log(π)∗A
其中,A是优越度,也是所有强化学习算法的一个重要部分。直觉上,它描述了一个行动比某个基准线好多少。在未来的算法中,我们将遇到更复杂的用于比较回报的基准线,而现在我们就假设基准线为0,我们也可以简单地把它想成我们采取每个行动对应的回报。
Pi是策略。在这个例子中,它和所选行动的权重相关。通过采取行动,获得回报并更新网络这个过程的循环,我们将很快得到一个收敛的agent,它将可以解决赌博机问题。
1、多臂赌博机(没有考虑环境和状态)
2、上下文赌博机














 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









