






感觉今年题目挺恶心人的,就好像逼着大家氪金买雷达和基站,传统视觉如果没有焦距大于50mm的镜头都完全没办法进行。
目录
目录
一、无人机题目分析(视觉部分)
做视觉的嘛,最重要的肯定是先提取特征,只有提取足够多的特征才能限定我们需要识别的东西。
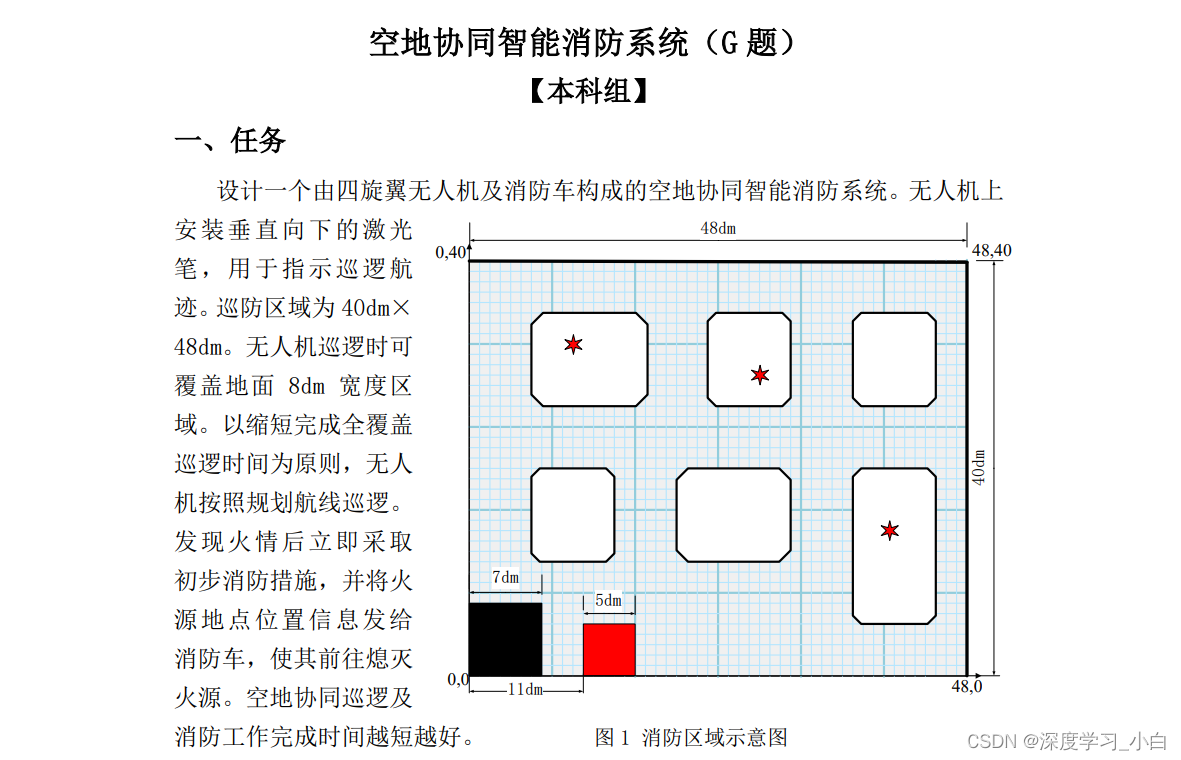
从这份示意图中,飞行部分我们能看到特征最明显的应该就是那堆黑线,那我们就至少有一个想法那就是提取黑线然后返回中心坐标来约束无人机飞行轨迹,但是很多队伍应该会被黑线宽度只有1厘米劝退这个方案,我们队伍是因为恰好买了一个焦距能达到50mm的长焦镜头才决定通过巡线去完成飞行任务,我们队伍一共想了两个方案,第一个是通过单黑线进行飞行限制,第二个是通过双线进行飞行限制。
二、视觉部分硬件基础
openMV配套专用长焦镜头,树莓派4B(配备系统:Raspberry Pi OS(Raspbian))、USB免驱工业摄像头(焦距5~55mm),树莓派最大的优势就是支持多种网络协议,拥有一个专用的GPIO板,可以支持多种用户自定义的硬件连接和扩展,具备多线程处理任务和强大的算力,非常适合我们的需求。我们队伍主要使用的也是树莓派来进行视觉任务,这里我就分别对树莓派和openMV进行一定的介绍。
1、树莓派(重点介绍)
当初因为以为无人机能自动化脚本控制因此被商家忽悠着去买了树莓派,拿回来捣鼓了一下发现用树莓派能使用OpenCV,OpenCV经过了速度和性能的优化。许多核心功能是用C / C++实现的,并具有硬件加速支持,使其适用于实时应用程序。
再者我发现树莓派相较于openMV有一个优势就是它的引脚很多而且图形化界面开发起来真的很方便!
这里我就不给大家说明我在树莓派上走过的坑了,因为介绍起来有点多,大家有兴趣可以去看我另外一篇博客“树莓派走过的坑”,我会在里面详细说明,包括本人的解决方法。
这里贴出我树莓派上的代码以及介绍:
调试部分
由于我们的无人机不方便时时查看画面信息,很难通过图像来进行调试,于是我们想到可以通过RGB小灯来判断当前识别信息进行调试,而且这里可以看到树莓派的优势,那就是多线程。
我们这里的小灯闪烁的部分全是通过多线程操控的(多线程的意思就是可以同时进行多个任务),这样我们看到了小灯闪烁就说明肯定是当前状态,我们就完全不用担心是否因为延时导致的误判断,而且代码逻辑也超级简单。
这里也告诉大家一种查看树莓派引脚定义的方法,直接在命令行输入pinout就可以了
# 引入GPIO定义库,树莓派自带的不需要安装
import RPi.GPIO as GPIO
# 设置GPIO模式为BCM
GPIO.setmode(GPIO.BCM)
# 定义LED黄所连接的GPIO引脚
led_pin_yellow=16
# 定义LED红所连接的GPIO引脚
led_pin_red=20
# 定义LED绿所连接的GPIO引脚
led_pin_green=21
# 定义激光模块所连接的GPIO引脚
laser_pin=12
# 定义激光模块S脚所接高电平的GPIO引脚
laser_S_pin=26
# 设置GPIO引脚为输出模式
GPIO.setup(led_pin_yellow, GPIO.OUT)
GPIO.setup(led_pin_red, GPIO.OUT)
GPIO.setup(led_pin_green, GPIO.OUT)
GPIO.setup(laser_pin,GPIO.OUT)
GPIO.setup(laser_S_pin,GPIO.OUT)
# 创建一个Event对象,用于线程间的通信
blink_event_yellow=threading.Event()
blink_event_red=threading.Event()
blink_event_green=threading.Event()
laser_event=threading.Event()
# 定义闪烁的函数
def blink_led_yellow():
while True:
# 等待Event的触发,当主线程设置Event后才会继续执行
blink_event_yellow.wait()
# 打开LED
GPIO.output(led_pin_yellow, GPIO.HIGH)
time.sleep(0.1) # 等待0.5秒
# 关闭LED
GPIO.output(led_pin_yellow, GPIO.LOW)
time.sleep(0.1) # 等待0.5秒
# 定义闪烁的函数
def blink_led_red():
while True:
# 等待Event的触发,当主线程设置Event后才会继续执行
blink_event_red.wait()
# 打开LED
GPIO.output(led_pin_red, GPIO.HIGH)
time.sleep(0.1) # 等待0.5秒
# 关闭LED
GPIO.output(led_pin_red, GPIO.LOW)
time.sleep(0.1) # 等待0.5秒
# 定义闪烁的函数
def blink_led_green():
while True:
# 等待Event的触发,当主线程设置Event后才会继续执行
blink_event_green.wait()
# 打开LED
GPIO.output(led_pin_green, GPIO.HIGH)
time.sleep(0.5) # 等待0.5秒
# 关闭LED
GPIO.output(led_pin_green, GPIO.LOW)
time.sleep(0.5) # 等待0.5秒
# 定义激光闪烁的函数
def laser_blink():
while True:
# 等待Event的触发,当主线程设置Event后才会继续执行
laser_event.wait()
# 打开S
GPIO.output(laser_S_pin, GPIO.HIGH)
GPIO.output(laser_pin, GPIO.HIGH)
time.sleep(0.5) # 等待0.5秒
# 关闭LED
GPIO.output(laser_pin, GPIO.LOW)
time.sleep(0.5) # 等待0.5秒
# ...
blink_event_green.set()
blink_event_yellow.set()
blink_event_red.set()
blink_event_green.clear()
blink_event_red.clear()
blink_event_yellow.clear()
GPIO.cleanup()
# ...
if __name__ == "__main__":
# 创建并启动LED黄闪烁的线程
led_thread=threading.Thread(target = blink_led_yellow)
led_thread.daemon=True # 将线程设置为守护线程,当主线程结束时自动结束闪烁线程
led_thread.start()
# 创建并启动LED红闪烁的线程
led_thread=threading.Thread(target = blink_led_red)
led_thread.daemon=True # 将线程设置为守护线程,当主线程结束时自动结束闪烁线程
led_thread.start()
# 创建并启动LED绿闪烁的线程
led_thread=threading.Thread(target = blink_led_green)
led_thread.daemon=True # 将线程设置为守护线程,当主线程结束时自动结束闪烁线程
led_thread.start()
# 创建并启动LED绿闪烁的线程
led_thread=threading.Thread(target = laser_blink)
led_thread.daemon=True # 将线程设置为守护线程,当主线程结束时自动结束闪烁线程
led_thread.start()串口部分
import serial
import time
import struct
# ------------------串口初始化-----------------------#
# 创建串口对象
ser=serial.Serial('/dev/ttyAMA0', baudrate = 115200, timeout = 1)
# 等待一段时间以确保串口已经打开
time.sleep(2)
# 首尾标志的十六进制表示
start_flag=b'\x45'
end_flag=b'\x46'
# 要发送的数据(字节形式)
data_to_send=bytes([0])
# ------------------串口初始化-----------------------#
#...
error_x=int(center_x - 320)
print(error_x)
# 用两个字节表示偏移量
send_data_x=struct.pack('>h', error_x)
# 将首尾标志和数据拼接成字节流
encoded_data=start_flag + turn_flag + send_data_x + end_flag
# 发送数据
ser.write(encoded_data)
print(encoded_data)然后给大家介绍一下我经常用的做识别的方法,一个是色块识别,另外一个就是霍夫识别,然后对两种方法进行条件限定之后返回坐标就可以完成大部分视觉任务了。
色块识别
import numpy as np
import cv2
def get_largest_black_area(image):
# 转换图像到HSV颜色空间
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 定义黑色的HSV范围
lower_black = np.array([0, 0, 0])
upper_black = np.array([179, 255, 50])
# 创建黑色色块的掩膜
mask = cv2.inRange(hsv, lower_black, upper_black)
# 找到黑色色块的轮廓
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if contours:
# 找到最大的黑色色块
max_contour = max(contours, key=cv2.contourArea)
# 计算最大黑色色块的中心点坐标
M = cv2.moments(max_contour)
center_x = int(M["m10"] / M["m00"])
center_y = int(M["m01"] / M["m00"])
# 绘制最大黑色色块的轮廓和中心点
cv2.drawContours(image, [max_contour], 0, (0, 255, 0), 2)
cv2.circle(image, (center_x, center_y), 5, (0, 0, 255), -1)
blink_event_red.set()
return center_x, center_y
else:
return None,None霍夫识别
霍夫识别其实是可以结合色块识别将感兴趣区域提取出来,然后在感兴趣区域上进行霍夫直线识别,这样就能减少误识别的情况。
import cv2
import numpy as np
def calculate_angle(line1, line2):
# 计算两条直线的夹角(弧度)
dx1, dy1 = line1[2] - line1[0], line1[3] - line1[1]
dx2, dy2 = line2[2] - line2[0], line2[3] - line2[1]
angle_radians = np.arccos((dx1*dx2 + dy1*dy2) / (np.sqrt(dx1**2 + dy1**2) * np.sqrt(dx2**2 + dy2**2)))
return np.degrees(angle_radians)
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
print("Failed to grab a frame from the camera.")
break
# 将图像转换为LAB颜色空间
lab_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2LAB)
# 使用阈值将黑色区域提取出来
lower_black = np.array([0, 0, 0], dtype=np.uint8)
upper_black = np.array([50, 128, 128], dtype=np.uint8)
black_mask = cv2.inRange(lab_frame, lower_black, upper_black)
# 找到黑色区域中的最大轮廓
contours, _ = cv2.findContours(black_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if contours:
max_contour = max(contours, key=cv2.contourArea)
x, y, w, h = cv2.boundingRect(max_contour)
roi = frame[y:y+h, x:x+w]
# 在ROI区域内使用霍夫直线检测算法找到直线
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray_roi, threshold1=50, threshold2=150, apertureSize=3)
lines = cv2.HoughLinesP(edges, rho=1, theta=np.pi/180, threshold=100, minLineLength=100, maxLineGap=10)
if lines is not None and len(lines) >= 2:
# 在图像坐标系下找到两条夹角近似于90度的直线并计算交点
for line in lines:
x1, y1, x2, y2 = line[0]
cv2.line(roi, (x1, y1), (x2, y2), (0, 255, 0), 2)
for i in range(len(lines)):
for j in range(i + 1, len(lines)):
line1 = lines[i][0]
line2 = lines[j][0]
# 计算两条直线的夹角
angle_degrees = calculate_angle(line1, line2)
# 夹角在85度到95度之间认为符合条件
if 85 <= angle_degrees <= 95:
p1, p2 = (line1[0], line1[1]), (line1[2], line1[3])
p3, p4 = (line2[0], line2[1]), (line2[2], line2[3])
# 计算两直线的交点
# 略去计算交点的部分
# 在这里可以将交点打印到后台或进行其他处理
print("Found two lines with angle:", angle_degrees)
cv2.imshow("ROI", roi)
cv2.imshow("Black Mask", black_mask)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
这两个方法都有一个问题,那就是阈值该怎么得到,不像openMV有个阈值编辑器,OpenCV如果要进行阈值编辑需要自己写一个脚本,这里提供两个我自己在使用的脚本,一个是图片的,一个是摄像头的,非常方便。
图片阈值编辑
# -*- coding:utf-8 -*-
import cv2
import numpy as np
"""
功能:读取一张图片,显示出来,转化为HSV色彩空间
并通过滑块调节HSV阈值,实时显示
"""
image=cv2.imread(r'D:\pycharmproject\num_pic_save_1\frame_0067.png') # 根据路径读取一张图片,opencv读出来的是BGR模式
cv2.imshow("BGR", image) # 显示图片
hsv_low=np.array([0, 0, 0])
hsv_high=np.array([0, 0, 0])
# 下面几个函数,写得有点冗余
def h_low(value):
hsv_low[0]=value
def h_high(value):
hsv_high[0]=value
def s_low(value):
hsv_low[1]=value
def s_high(value):
hsv_high[1]=value
def v_low(value):
hsv_low[2]=value
def v_high(value):
hsv_high[2]=value
cv2.namedWindow('image', cv2.WINDOW_AUTOSIZE)
# H low:
# 0:指向整数变量的可选指针,该变量的值反映滑块的初始位置。
# 179:表示滑块可以达到的最大位置的值为179,最小位置始终为0。
# h_low:指向每次滑块更改位置时要调用的函数的指针,指针指向h_low元组,有默认值0。
cv2.createTrackbar('H low', 'image', 0, 179, h_low)
cv2.createTrackbar('H high', 'image', 0, 179, h_high)
cv2.createTrackbar('S low', 'image', 0, 255, s_low)
cv2.createTrackbar('S high', 'image', 0, 255, s_high)
cv2.createTrackbar('V low', 'image', 0, 255, v_low)
cv2.createTrackbar('V high', 'image', 0, 255, v_high)
while True:
dst=cv2.cvtColor(image, cv2.COLOR_BGR2HSV) # BGR转HSV
dst=cv2.inRange(dst, hsv_low, hsv_high) # 通过HSV的高低阈值,提取图像部分区域
cv2.imshow('dst', dst)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()摄像头阈值编辑
import cv2
import numpy as np
def empty(a):
pass
def stackImages(scale,imgArray):
rows = len(imgArray)
cols = len(imgArray[0])
rowsAvailable = isinstance(imgArray[0], list)
width = imgArray[0][0].shape[1]
height = imgArray[0][0].shape[0]
if rowsAvailable:
for x in range ( 0, rows):
for y in range(0, cols):
if imgArray[x][y].shape[:2] == imgArray[0][0].shape [:2]:
imgArray[x][y] = cv2.resize(imgArray[x][y], (0, 0), None, scale, scale)
else:
imgArray[x][y] = cv2.resize(imgArray[x][y], (imgArray[0][0].shape[1], imgArray[0][0].shape[0]), None, scale, scale)
if len(imgArray[x][y].shape) == 2: imgArray[x][y]= cv2.cvtColor( imgArray[x][y], cv2.COLOR_GRAY2BGR)
imageBlank = np.zeros((height, width, 3), np.uint8)
hor = [imageBlank]*rows
hor_con = [imageBlank]*rows
for x in range(0, rows):
hor[x] = np.hstack(imgArray[x])
ver = np.vstack(hor)
else:
for x in range(0, rows):
if imgArray[x].shape[:2] == imgArray[0].shape[:2]:
imgArray[x] = cv2.resize(imgArray[x], (0, 0), None, scale, scale)
else:
imgArray[x] = cv2.resize(imgArray[x], (imgArray[0].shape[1], imgArray[0].shape[0]), None,scale, scale)
if len(imgArray[x].shape) == 2: imgArray[x] = cv2.cvtColor(imgArray[x], cv2.COLOR_GRAY2BGR)
hor= np.hstack(imgArray)
ver = hor
return ver
frameWidth = 1920
frameHeight = 1080
cap = cv2.VideoCapture(1)
cap.set(3, frameWidth)
cap.set(4, frameHeight)
cap.set(10,150)
cv2.namedWindow("TrackBars")
cv2.resizeWindow("TrackBars",640,360)
cv2.createTrackbar("Hue Min","TrackBars",0,179,empty)
cv2.createTrackbar("Hue Max","TrackBars",19,179,empty)
cv2.createTrackbar("Sat Min","TrackBars",110,255,empty)
cv2.createTrackbar("Sat Max","TrackBars",240,255,empty)
cv2.createTrackbar("Val Min","TrackBars",153,255,empty)
cv2.createTrackbar("Val Max","TrackBars",255,255,empty)
while True:
success, img = cap.read()
imgHSV = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
h_min = cv2.getTrackbarPos("Hue Min","TrackBars")
h_max = cv2.getTrackbarPos("Hue Max", "TrackBars")
s_min = cv2.getTrackbarPos("Sat Min", "TrackBars")
s_max = cv2.getTrackbarPos("Sat Max", "TrackBars")
v_min = cv2.getTrackbarPos("Val Min", "TrackBars")
v_max = cv2.getTrackbarPos("Val Max", "TrackBars")
print(h_min,h_max,s_min,s_max,v_min,v_max)
lower = np.array([h_min,s_min,v_min])
upper = np.array([h_max,s_max,v_max])
mask = cv2.inRange(imgHSV,lower,upper)
imgResult = cv2.bitwise_and(img,img,mask=mask)
imgStack = stackImages(0.3,([img,imgHSV],[mask,imgResult]))
cv2.imshow("Stacked Images", imgStack)
cv2.waitKey(1)2、openMV
由于openMV并不是我主要使用的视觉模块,所以有一些没有介绍到的地方请大家谅解。
串口部分
from pyb import UART
import pyb
#--------------静态变量定义 START -------------------
# 首尾标志的十六进制表示
start_flag=b'\x64'
end_flag=b'\x65'
data_to_send=bytes([0])
#--------------静态变量定义 END -------------------
#--------------串口UART部分 START -------------------
uart = UART(3,115200,timeout_char = 1000) #串口初始化
def data_format_wrapper(is_right_angle, error_x):
'''
根据通信协议封装数据
TODO 重新编写通信协议 与配套C解析代码
is_right_angle:画面中是否出现直角
error_x:当巡直线时色块中心与画面中心的偏移量
'''
# 要发送的数据(字节形式)
global data_to_send
data_to_send = start_flag + is_right_angle + error_x + end_flag
return data_to_send
#--------------串口UART部分 END -------------------
#...
while(True):
data_to_send = data_format_wrapper(is_right_angle,error_x)
uart.write(data_to_send)
print(data_to_send)色块识别
这里直接给出多颜色识别的官方例程吧,因为后面基本上不可能只有一种颜色需要追踪,因此可以直接通过多颜色组合识别来了解色块追踪的原理。
# 多颜色组合识别
#
# 这个例子展示了使用OpenMV Cam进行多色代码跟踪。
#
# 颜色代码是由两种或更多颜色组成的色块。下面的例子只会跟踪其中有两种或多种颜色的彩色物体。
import sensor, image, time
# 颜色跟踪阈值(L Min, L Max, A Min, A Max, B Min, B Max)
# 下面的阈值一般跟踪红色/绿色的东西。你可以调整它们…
thresholds = [(30, 100, 15, 127, 15, 127), # generic_red_thresholds -> index is 0 so code == (1 << 0)
(30, 100, -64, -8, -32, 32), # generic_green_thresholds -> index is 1 so code == (1 << 1)
(0, 15, 0, 40, -80, -20)] # generic_blue_thresholds -> index is 2 so code == (1 << 2)
# 当“find_blobs”的“merge = True”时,code代码被组合在一起。
sensor.reset()
#初始化摄像头,reset()是sensor模块里面的函数
sensor.set_pixformat(sensor.RGB565)
#设置图像色彩格式,有RGB565色彩图和GRAYSCALE灰度图两种
sensor.set_framesize(sensor.QVGA)
#设置图像像素大小
sensor.skip_frames(time = 2000)
sensor.set_auto_gain(False) # 颜色跟踪必须关闭自动增益
sensor.set_auto_whitebal(False) # 颜色跟踪必须关闭白平衡
clock = time.clock()
# 只有比“pixel_threshold”多的像素和多于“area_threshold”的区域才被
# 下面的“find_blobs”返回。 如果更改相机分辨率,
# 请更改“pixels_threshold”和“area_threshold”。 “merge = True”合并图像中所有重叠的色块。
while(True):
clock.tick()
img = sensor.snapshot()
for blob in img.find_blobs(thresholds, pixels_threshold=100, area_threshold=100, merge=True):
if blob.code() == 3: # r/g code
img.draw_rectangle(blob.rect())
img.draw_cross(blob.cx(), blob.cy())
img.draw_string(blob.x() + 2, blob.y() + 2, "r/g")
if blob.code() == 5: # r/b code
img.draw_rectangle(blob.rect())
img.draw_cross(blob.cx(), blob.cy())
img.draw_string(blob.x() + 2, blob.y() + 2, "r/b")
if blob.code() == 6: # g/b code
img.draw_rectangle(blob.rect())
img.draw_cross(blob.cx(), blob.cy())
img.draw_string(blob.x() + 2, blob.y() + 2, "g/b")
if blob.code() == 7: # r/g/b code
img.draw_rectangle(blob.rect())
img.draw_cross(blob.cx(), blob.cy())
img.draw_string(blob.x() + 2, blob.y() + 2, "r/g/b")
print(clock.fps())
霍夫识别
霍夫直线识别也是通过官方例程直接给出,如果有需要可以直接复制到IDE就能使用。
# 识别直线例程
#
# 这个例子展示了如何在图像中查找线条。对于在图像中找到的每个线对象,
# 都会返回一个包含线条旋转的线对象。
# 注意:线条检测是通过使用霍夫变换完成的:
# http://en.wikipedia.org/wiki/Hough_transform
# 请阅读以上关于“theta”和“rho”的更多信息。
# find_lines()找到无限长度的线。使用find_line_segments()
# 来查找非无限线。
enable_lens_corr = False # turn on for straighter lines...打开以获得更直的线条…
import sensor, image, time
sensor.reset()
sensor.set_pixformat(sensor.RGB565) #灰度更快
sensor.set_framesize(sensor.QQVGA)
sensor.skip_frames(time = 2000)
clock = time.clock()
# 所有的线对象都有一个`theta()`方法来获取它们的旋转角度。
# 您可以根据旋转角度来过滤线条。
min_degree = 0
max_degree = 179
# 所有线段都有 `x1()`, `y1()`, `x2()`, and `y2()` 方法来获得他们的终点
# 一个 `line()` 方法来获得所有上述的四个元组值,可用于 `draw_line()`.
while(True):
clock.tick()
img = sensor.snapshot()
if enable_lens_corr: img.lens_corr(1.8) # for 2.8mm lens...
# `threshold` controls how many lines in the image are found. Only lines with
# edge difference magnitude sums greater than `threshold` are detected...
# `threshold`控制从霍夫变换中监测到的直线。只返回大于或等于阈值的
# 直线。应用程序的阈值正确值取决于图像。注意:一条直线的大小是组成
# 直线所有索贝尔滤波像素大小的总和。
# `theta_margin`和`rho_margin`控件合并相似的直线。如果两直线的
# theta和ρ值差异小于边际,则它们合并。
for l in img.find_lines(threshold = 1000, theta_margin = 25, rho_margin = 25):
if (min_degree <= l.theta()) and (l.theta() <= max_degree):
img.draw_line(l.line(), color = (255, 0, 0))
# print(l)
print("FPS %f" % clock.fps())
# About negative rho values:
# 关于负rho值:
#
# A [theta+0:-rho] tuple is the same as [theta+180:+rho].
# A [theta+0:-rho]元组与[theta+180:+rho]相同。
好的,树莓派和openMV的基本介绍已经做完了,接下来就进入我们的方案介绍。
三、方案一
方案一思路
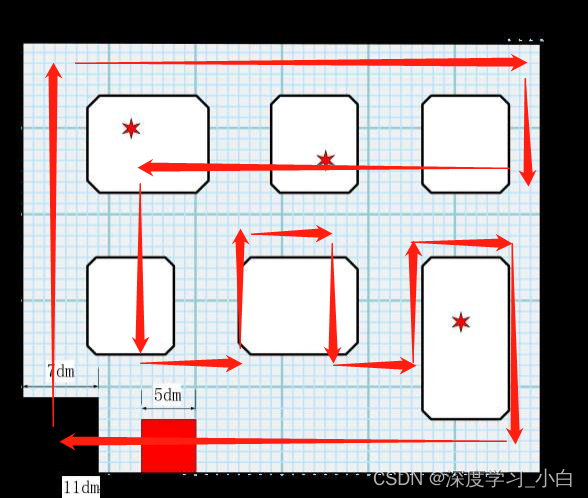
第一个方案是我们第一天制定好的,无人机按照我们设定的路径进行飞行,然后通过街区那一部分的黑线和白色区域的中心坐标来限定飞行轨迹让无人机不偏航,我们是这样想的,当只识别到黑线的时候就用黑线来进行约束,当黑线和白色区域同时识别到的时候就用两个的中心坐标的平均值进行约束。但是,在调试过程中我们发现了,只有当我们进行对黑线和白色区域的中心坐标的距离进行限定才能使我们比较完美地巡完黑线,但是后面又发现了一个问题就是,当我们用白色区域加以限定的话,就会导致误识别黑线就巡歪,所以这个方案基本上宣告作废了,但是也算是一个思路所以给提一嘴,当然如果你的无人机飞的很稳就不用担心这个问题了。
方案一路线图
方案一代码
import cv2
import numpy as np
import pyzbar.pyzbar as pyzbar
import serial
import time
import struct
import time
# ------------------变量初始化-----------------------#
# 设定期望值
move_x = 0
move_y = 0
# 设定屏幕参数
CAP_WIDTH = 640
CAP_HEIGHT = 480
# 屏幕中心
center_width = CAP_WIDTH / 2
center_height = CAP_HEIGHT / 2
# 设定识别区域的比例
ratio_interest = 1/4
# 设定限制色块面积阈值
limit_area=5000
# 定义识别到的色块的位置
detect_x=0
detect_y=0
# 定义黑色块白色块之间的限制距离
# 下半边
limit_distance_y = 50
# 右半边
limit_distance_x = 50
# 定义拐弯标志
round_detecct = 0
# ------------------变量初始化-----------------------#
# ------------------函数定义-----------------------#
def find_largest_color_block(image, color):
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
lower_range, upper_range = get_color_range(color)
mask = cv2.inRange(hsv, lower_range, upper_range)
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
max_area = 0
max_contour = None
for contour in contours:
area = cv2.contourArea(contour)
if area > max_area:
max_area = area
max_contour = contour
return max_contour, max_area
def get_color_range(color):
if color == "black":
lower_range = np.array([0, 0, 0])
upper_range = np.array([179, 255, 80])
return lower_range, upper_range
elif color == "white":
lower_range = np.array([0, 0, 77])
upper_range = np.array([91, 30, 255])
return lower_range, upper_range
elif color == "red":
lower_range = np.array([0, 126, 119])
upper_range = np.array([89, 255, 255])
return lower_range, upper_range
else:
raise ValueError("Unsupported color. Supported colors are 'black' and 'white'.")
def judge_color(black_area, white_area, limit_area):
if black_area > limit_area and white_area < limit_area:
return 0
elif white_area > limit_area and black_area < limit_area:
return 1
elif white_area > limit_area and black_area > limit_area:
return 2
else:
return 3
# ------------------函数定义-----------------------#
# ------------------相机初始化-----------------------#
cap=cv2.VideoCapture(1)
# 设置相机参数
cap.set(cv2.CAP_PROP_FRAME_WIDTH, CAP_WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, CAP_HEIGHT)
# cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 1080)
# ------------------相机初始化-----------------------#
# ------------------主函数-----------------------#
# 主线程中执行其他功能
def main_function():
global send_data_x, send_data_y
# 主函数
while True:
ret, frame=cap.read()
if not ret:
print("无法读取帧。")
break
black_contour, black_area=find_largest_color_block(frame, "black")
white_contour, white_area=find_largest_color_block(frame, "white")
red_contour, red_area=find_largest_color_block(frame, "red")
x_black, y_black, w_black, h_black=cv2.boundingRect(black_contour)
if h_black != 0:
w_sub_h_black=int(w_black / h_black)
x_white, y_white, w_white, h_white=cv2.boundingRect(white_contour)
if h_white != 0:
w_sub_h_white=int(w_white / h_white)
color_detect=judge_color(black_area, white_area, limit_area)
# 右半边感兴趣区域
ROI_RIGHT = frame[0:, int(ratio_interest*CAP_WIDTH):]
# 下半边感兴趣区域
ROI_DOWN = frame[int(ratio_interest*CAP_HEIGHT):, 0:]
if color_detect == 0: # 仅黑色
if w_sub_h_black > 1: # 黑色下半边
cv2.rectangle(ROI_DOWN, (x_black, y_black), (x_black + w_black, y_black + h_black), (0, 0, 255), 2)
black_center=(x_black + w_black / 2, y_black + h_black / 2)
# print("黑色色块框的中心坐标:", black_center)
detect_x=center_width + move_x
detect_y=y_black + h_black / 2 + ratio_interest*CAP_HEIGHT
# print("仅识别到黑色地识别到黑色下半边了")
if black_area < h_black*w_black/2:
print("识别到拐角啦")
round_detecct = 1
else: # 黑色右半边
cv2.rectangle(ROI_RIGHT, (x_black, y_black), (x_black + w_black, y_black + h_black), (0, 0, 255), 2)
black_center=(x_black + w_black / 2, y_black + h_black / 2)
# print("黑色色块框的中心坐标:", black_center)
detect_x=x_black + w_black / 2+ratio_interest*CAP_WIDTH
detect_y=center_height + move_y
# print("仅识别到黑色地识别到黑色右半边了")
if black_area < h_black*w_black/2:
print("识别到拐角啦")
round_detecct = 1
elif color_detect == 2: # 黑白双色
if w_sub_h_black > 1 or w_sub_h_white > 1: # 平均下半边
if w_sub_h_black > 1 and black_area < h_black*w_black/2 and white_area > h_white*w_white/2:
print("识别到拐角啦")
round_detecct = 1
# 根据黑白色块y的距离限制下半边运动的幅度
if abs(y_black - y_white) < limit_distance_y:
cv2.rectangle(ROI_DOWN, (x_black, y_black), (x_black + w_black, y_black + h_black), (0, 0, 255), 2)
cv2.rectangle(ROI_DOWN, (x_white, y_white), (x_white + w_white, y_white + h_white), (0, 255, 255), 2)
ave_center=((x_white + w_white / 2 + x_black + w_black / 2) / 2,
(y_white + h_white / 2 + y_black + h_black / 2) / 2)
# print("中心坐标:", ave_center)
detect_x=center_width + move_x
detect_y=(y_white + h_white // 2 + y_black + h_black / 2) / 2 + ratio_interest*CAP_HEIGHT
# print("识别到下半边了")
# 如果发现y的距离过大只根据黑色色块y来调整中心
else:
cv2.rectangle(ROI_DOWN, (x_black, y_black), (x_black + w_black, y_black + h_black), (0, 0, 255), 2)
black_center=(x_black + w_black / 2, y_black + h_black / 2)
# print("黑色色块框的中心坐标:", black_center)
detect_x=center_width + move_x
detect_y=y_black + h_black / 2 + ratio_interest * CAP_HEIGHT
# print("识别到黑色下半边了")
elif w_sub_h_black < 1 or w_sub_h_white < 1: # 平均右半边
if w_sub_h_black < 1 and black_area < h_black*w_black/2 and white_area > h_white*w_white/2:
print("识别到拐角啦")
round_detecct = 1
# 根据黑白色块x的距离限制右半边运动的幅度
if abs(x_black - x_white) < limit_distance_x:
cv2.rectangle(ROI_RIGHT, (x_black, y_black), (x_black + w_black, y_black + h_black), (0, 0, 255), 2)
cv2.rectangle(ROI_RIGHT, (x_white, y_white), (x_white + w_white, y_white + h_white), (0, 255, 255), 2)
ave_center=((x_white + w_white / 2 + x_black + w_black / 2) / 2,
(y_white + h_white / 2 + y_black + h_black / 2) / 2)
# print("中心坐标:", ave_center)
detect_x=(x_white + w_white / 2 + x_black + w_black / 2) / 2+ratio_interest*CAP_WIDTH
detect_y=center_height + move_y
# print("识别到右半边了")
# 如果发现x的距离过大只根据黑色色块x来调整中心
else:
cv2.rectangle(ROI_RIGHT, (x_black, y_black), (x_black + w_black, y_black + h_black),(0, 0, 255), 2)
black_center=(x_black + w_black / 2, y_black + h_black / 2)
# print("黑色色块框的中心坐标:", black_center)
detect_x=x_black + w_black / 2 + ratio_interest * CAP_WIDTH
detect_y=center_height + move_y
# print("识别到黑色右半边了")
else:
print("nothing detected")
detect_x=center_width + move_x
detect_y=center_height + move_y
else:
print("nothing detected")
detect_x=center_width + move_x
detect_y=center_height + move_y
# print(detect_x)
# print(detect_y)
error_x=int(detect_x - center_width)
error_y=int(detect_y - center_height)
send_data_x=struct.pack('>h', error_x)
send_data_y=struct.pack('>h', error_y)
# print(send_data_x)
# print(send_data_y)
cv2.imshow('Color Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# ------------------主函数-----------------------#
if __name__ == "__main__":
# 执行主线程的功能
main_function()
cap.release()
cv2.destroyAllWindows()
四、方案二
方案二思路
第二个方案是最后一个晚上我们发现我们之前那个方案一直存在一个很大的未知的漏洞所以我们临时决定更换的,那个时候更换方案是很绝望的,因为基本等于宣告无缘国赛了,不过我们还是换了,一个是再坚持也没意义,另外一个就是这个方案比起之前那个基本等于全闭环会更可靠。
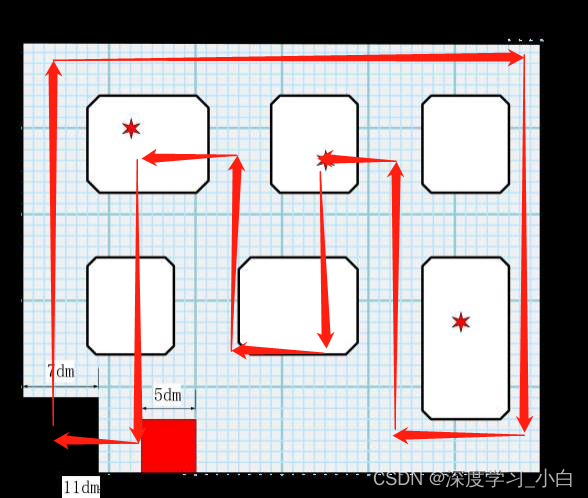
我们的想法就是因为基本上这张地图都有两条黑线,所以我们不如直接通过两条黑线的中心坐标的平均值来限定我们的飞行轨迹,然后在没有黑线的地方就使用开环来控制,然后如果遇到了误识别的情况我们的想法就是利用一条黑线的位置然后加上我们增加的补偿来弥补,这样就等于拟合出来了双黑线的情况。
同时我们还根据限定区域出现黑色并且黑色在限定区域的占空比来判断是否到达拐角,全程我们无人机不转机头方向(因为转机头方向很容易判断不准确导致满盘皆输)。
方案二路线图
方案二代码
import cv2
import numpy as np
import pyzbar.pyzbar as pyzbar
import serial
import time
import struct
import RPi.GPIO as GPIO
import threading
# 设置GPIO模式为BCM
GPIO.setmode(GPIO.BCM)
# 定义LED黄所连接的GPIO引脚
led_pin_yellow=16
# 定义LED红所连接的GPIO引脚
led_pin_red=20
# 定义LED绿所连接的GPIO引脚
led_pin_green=21
# 定义激光模块所连接的GPIO引脚
laser_pin=12
# 定义激光模块S脚所接高电平的GPIO引脚
laser_S_pin=26
# 设置GPIO引脚为输出模式
GPIO.setup(led_pin_yellow, GPIO.OUT)
GPIO.setup(led_pin_red, GPIO.OUT)
GPIO.setup(led_pin_green, GPIO.OUT)
GPIO.setup(laser_pin,GPIO.OUT)
GPIO.setup(laser_S_pin,GPIO.OUT)
# 创建一个Event对象,用于线程间的通信
blink_event_yellow=threading.Event()
blink_event_red=threading.Event()
blink_event_green=threading.Event()
laser_event=threading.Event()
# 定义闪烁的函数
def blink_led_yellow():
while True:
# 等待Event的触发,当主线程设置Event后才会继续执行
blink_event_yellow.wait()
# 打开LED
GPIO.output(led_pin_yellow, GPIO.HIGH)
time.sleep(0.1) # 等待0.5秒
# 关闭LED
GPIO.output(led_pin_yellow, GPIO.LOW)
time.sleep(0.1) # 等待0.5秒
# 定义闪烁的函数
def blink_led_red():
while True:
# 等待Event的触发,当主线程设置Event后才会继续执行
blink_event_red.wait()
# 打开LED
GPIO.output(led_pin_red, GPIO.HIGH)
time.sleep(0.1) # 等待0.5秒
# 关闭LED
GPIO.output(led_pin_red, GPIO.LOW)
time.sleep(0.1) # 等待0.5秒
# 定义闪烁的函数
def blink_led_green():
while True:
# 等待Event的触发,当主线程设置Event后才会继续执行
blink_event_green.wait()
# 打开LED
GPIO.output(led_pin_green, GPIO.HIGH)
time.sleep(0.5) # 等待0.5秒
# 关闭LED
GPIO.output(led_pin_green, GPIO.LOW)
time.sleep(0.5) # 等待0.5秒
# 定义激光闪烁的函数
def laser_blink():
while True:
# 等待Event的触发,当主线程设置Event后才会继续执行
laser_event.wait()
# 打开S
GPIO.output(laser_S_pin, GPIO.HIGH)
GPIO.output(laser_pin, GPIO.HIGH)
time.sleep(0.5) # 等待0.5秒
# 关闭LED
GPIO.output(laser_pin, GPIO.LOW)
time.sleep(0.5) # 等待0.5秒
# ------------------串口初始化-----------------------#
# 创建串口对象
ser=serial.Serial('/dev/ttyAMA0', baudrate = 115200, timeout = 1)
# 等待一段时间以确保串口已经打开
time.sleep(2)
# 首尾标志的十六进制表示
start_flag=b'\x45'
end_flag=b'\x46'
# 要发送的数据(字节形式)
data_to_send=bytes([0])
# ------------------串口初始化-----------------------#
# ------------------变量初始化-----------------------#
# 期望值
move_x = 0
move_y = 0
CAP_WIDTH = 640
CAP_HEIGHT = 480
previous_max_area_idx = None
transition_count = 0
transition_flag = b'\x00'
lower_black=np.array([0, 0, 0])
upper_black=np.array([179, 255, 60])
turn_flag = b'\x00'
# ------------------变量初始化-----------------------#
# ------------------函数定义-----------------------#
def get_largest_and_secend_black_area(image):
hsv=cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
mask=cv2.inRange(hsv, lower_black, upper_black)
contours, _=cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if len(contours) >= 1:
sorted_contours=sorted(contours, key = cv2.contourArea, reverse = True)
largest_contour=sorted_contours[0]
second_largest_contour=sorted_contours[1] if len(sorted_contours) > 1 else None
return largest_contour, second_largest_contour
else:
return None, None
def get_largest_black_area(image):
hsv=cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
mask=cv2.inRange(hsv, lower_black, upper_black)
contours, _=cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
max_area=0
max_contour = None
for contour in contours:
area=cv2.contourArea(contour)
if area > max_area:
max_area=area
max_contour=contour
return max_contour, max_area
def get_largest_black_area_region(image):
#global previous_max_area_idx
#global transition_count, transition_flag
global turn_flag
height, width, _=image.shape
middle_x=width // 2
middle_y=height // 2
ratio_top = 0
ratio_right = 0
ratio_down = 0
top=image[0:10, int(1/2*middle_x):]
down=image[470:480, 0:int(3 / 4*width)]
# left=image[0:, 0:middle_x]
right=image[int(1/2*middle_y):, 630:width]
max_area_top,max_area_top_count = get_largest_black_area(top)
max_area_right,max_area_right_count = get_largest_black_area(right)
max_area_down,max_area_down_count = get_largest_black_area(down)
# get_largest_black_area(left)
x_top, y_top, w_top, h_top=cv2.boundingRect(max_area_top)
S_top = w_top*h_top
x_right, y_right, w_right, h_right=cv2.boundingRect(max_area_right)
S_right = w_right*h_right
x_down, y_down, w_down, h_down=cv2.boundingRect(max_area_down)
S_down = w_down*h_down
if S_top!=0:
ratio_top = max_area_top_count / S_top
if S_right!=0:
ratio_right = max_area_right_count / S_right
if S_down!=0:
ratio_down = max_area_down_count / S_down
if ratio_top > 0.9:
turn_flag = b'\x01'
elif ratio_right > 0.9:
turn_flag = b'\x02'
elif ratio_down > 0.9:
turn_flag = b'\x03'
else:
turn_flag = b'\x00'
print(turn_flag)
return turn_flag
# ------------------函数定义-----------------------#
# ------------------相机初始化-----------------------#
cap=cv2.VideoCapture(0)
# 设置相机参数
cap.set(cv2.CAP_PROP_FRAME_WIDTH, CAP_WIDTH)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, CAP_HEIGHT)
# ------------------相机初始化-----------------------#
# ------------------主函数-----------------------#
# 主线程中执行其他功能
def main_function():
global send_data_x, transition_flag, center_x
# 主函数
while True:
ret, frame=cap.read()
if not ret:
break
blink_event_green.set()
turn_flag=get_largest_black_area_region(frame)
largest_area, second_area=get_largest_and_secend_black_area(frame)
center_x = 320
center_y = 240
if largest_area is not None:
x_largest, y_largest, w_largest, h_largest=cv2.boundingRect(largest_area)
largest_area_count = cv2.contourArea(largest_area)
w_largest_new = int(w_largest-(w_largest*h_largest-largest_area_count)/h_largest)
h_largest_new = int(h_largest-(w_largest*h_largest-largest_area_count)/w_largest)
if h_largest_new!=0:
largest_w_sub_h=w_largest_new / h_largest_new
else:
largest_w_sub_h=5.1
if second_area is not None:
x_second, y_second, w_second, h_second=cv2.boundingRect(second_area)
second_w_sub_h=w_second / h_second
second_area_count = cv2.contourArea(second_area)
w_second = int(w_second-(w_second*h_second-second_area_count)/h_second)
cv2.rectangle(frame, (x_second, y_second), (x_second + w_second, y_second + h_second), (0, 255, 255), 2)
if second_area_count > 400 and second_w_sub_h < 0.2 and abs(x_largest - x_second) > 150:
center_x=(x_largest + x_second) / 2
center_y=240
blink_event_red.set()
if second_area_count > 400 and second_w_sub_h > 5 and abs(y_largest - y_second) > 150:
center_y=(y_largest + y_second) / 2
center_x = 320
blink_event_red.set()
else:
if largest_w_sub_h < 0.2:
if x_largest < 250:
center_x = x_largest + 200
blink_event_yellow.set()
else:
center_x = x_largest - 200
blink_event_yellow.set()
if largest_w_sub_h > 5:
if y_largest < 180:
center_y = y_largest + 100
blink_event_yellow.set()
else:
center_y = y_largest - 100
blink_event_yellow.set()
cv2.rectangle(frame, (x_largest, y_largest), (x_largest + w_largest_new, y_largest + h_largest_new), (0, 0, 255), 2)
else:
center_x=320
print("识别不到啦")
error_x=int(center_x - 320)
print(error_x)
send_data_x=struct.pack('>h', error_x)
# 将首尾标志和数据拼接成字节流
encoded_data=start_flag + turn_flag + send_data_x + end_flag
# 发送数据
ser.write(encoded_data)
print(encoded_data)
blink_event_green.clear()
blink_event_red.clear()
blink_event_yellow.clear()
cv2.imshow("Frame", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# time.sleep(1) # 假设主线程每隔1秒执行一次功能
GPIO.cleanup()
# ------------------主函数-----------------------#
if __name__ == "__main__":
# 创建并启动LED黄闪烁的线程
led_thread=threading.Thread(target = blink_led_yellow)
led_thread.daemon=True # 将线程设置为守护线程,当主线程结束时自动结束闪烁线程
led_thread.start()
# 创建并启动LED红闪烁的线程
led_thread=threading.Thread(target = blink_led_red)
led_thread.daemon=True # 将线程设置为守护线程,当主线程结束时自动结束闪烁线程
led_thread.start()
# 创建并启动LED绿闪烁的线程
led_thread=threading.Thread(target = blink_led_green)
led_thread.daemon=True # 将线程设置为守护线程,当主线程结束时自动结束闪烁线程
led_thread.start()
# 创建并启动LED绿闪烁的线程
led_thread=threading.Thread(target = laser_blink)
led_thread.daemon=True # 将线程设置为守护线程,当主线程结束时自动结束闪烁线程
led_thread.start()
# 执行主线程的功能
main_function()
cap.release()
cv2.destroyAllWindows()
同时,这里也给大家介绍一下我们发现的一种特殊的方法可以解决OpenCV为了为最大色块描框导致的包含区域过大的情况,我们的解决方案是这样的,描框的宽度和高度对于我们限定识别有很大的帮助,所以只有准确的宽高才能为我们识别提供帮助,这里我们可以通过OpenCV描出来的框的面积减去本身色块面积然后就能得到多余的面积,然后我们只要对减去这段面积的宽高就能得到修正后的宽高,进行更加准确的处理。

















 3048
3048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









