






为什么使用交叉熵作为损失函数
之前在学习分类问题是,突然有个疑问,为什么损失函数变成使用交叉熵了,而不是所熟悉的均方差MSE?
关于这个问题,我查了很多资料,对于这个问题的回答各式各样的都有,所以结合自己的理解在此做一个总结。我觉得对于这个问题可以分成两步来看, 一是为什么交叉熵可以作为损失函数,二是为什么在分类问题中一般使用交叉熵而不使用均方误差。
为什么交叉熵可以作为损失函数
交叉熵的定义如下:
L
i
=
−
[
y
(
i
)
l
o
g
y
^
(
i
)
+
(
1
−
y
(
i
)
)
l
o
g
(
1
−
y
^
(
i
)
)
]
L_i = -[y^{(i)}log\hat{y}^{(i)} + (1-y^{(i)})log(1-\hat{y}^{(i)})]
Li=−[y(i)logy^(i)+(1−y(i))log(1−y^(i))]
大多数情况下我们都是直接拿来用,但是它是怎么来的?为什么能表征真实样本标签和预测概率之间差距?也许很多人还不是很清楚,没关系,接下来就慢慢解读。
交叉熵损失函数的数学原理
以二分类问题为例,逻辑回归、神经网络等模型,真实样本标签为[0,1],分别表示负类和正类。模型最后会通过一个Sigmod函数,输出一个概率值,这个概率值反映了预测为正类的可能性:概率值越大,样本为正类的可能性越大。
Sigmod函数的表达式和图形表示如下:
g
(
s
)
=
1
1
+
e
−
s
g(s)=\frac{1}{1+e^{-s}}
g(s)=1+e−s1
其中s是模型上一层的输出,Sigmod函数特点为:当s为0时,g(s)=0.5;s >> 0时,g
≈
\approx
≈ 1,;s << 0时,g
≈
\approx
≈ 0。显然,g(s)将前一级的线性输出映射到[0,1]之间的数值概率上。这里的g(s)就是交叉熵中的模型预测输出。
之前说过,模型预测输出表征了当前样本为正类(即标记值为1)的概率:
y
^
=
P
(
y
=
1
∣
x
)
\hat{y} = P(y=1|x)
y^=P(y=1∣x)
所以,当前样本为负类的概率可以表示为:
1
−
y
^
=
P
(
y
=
0
∣
x
)
1-\hat{y} = P(y=0|x)
1−y^=P(y=0∣x)
重点来了,从极大似然的角度来看,把上述两种情况整合到一起:
P
(
y
∣
x
)
=
y
^
y
∗
(
1
−
y
^
)
1
−
y
P(y|x)=\hat{y}^{y}*(1-\hat{y})^{1-y}
P(y∣x)=y^y∗(1−y^)1−y
不懂极大似然估计也没关系,可以这么看:
当真实样本标签为
y
=
0
y=0
y=0时,上面式子第一项为1,概率等式转化为:
P
(
y
=
0
∣
x
)
=
1
−
y
^
P(y=0|x)=1-\hat{y}
P(y=0∣x)=1−y^
当真实样本标签为
y
=
1
y=1
y=1时,上米昂式子第二项为1,概率等式转化为:
P
(
y
=
1
∣
x
)
=
y
^
P(y=1|x)=\hat{y}
P(y=1∣x)=y^
两种情况下概率表达式跟之前完全一致,,只不过把两种情况整合在一起了。
重点看一下整合之后的概率表达式,我们希望的是概率
P
(
y
∣
x
)
P(y|x)
P(y∣x)越大越好。首先,我们对P(y|x)引入log函数,因为log运算不会对函数本身的单调性产生影响,
P
(
y
∣
x
)
P(y|x)
P(y∣x)取最大时,
l
o
g
P
(
y
∣
x
)
logP(y|x)
logP(y∣x)也是最大。如下:
l
o
g
P
(
y
∣
x
)
=
l
o
g
(
y
^
y
∗
(
1
−
y
^
)
1
−
y
)
=
y
l
o
g
y
^
+
(
1
−
y
)
l
o
g
(
1
−
y
^
)
logP(y|x) = log(\hat{y}^{y}*(1-\hat{y})^{1-y})=ylog\hat{y}+(1-y)log(1-\hat{y})
logP(y∣x)=log(y^y∗(1−y^)1−y)=ylogy^+(1−y)log(1−y^)
我们希望
l
o
g
P
(
y
∣
x
)
logP(y|x)
logP(y∣x)越大越好,反过来,只需要
l
o
g
P
(
y
∣
x
)
logP(y|x)
logP(y∣x)的负值
−
l
o
g
P
(
y
∣
x
)
-logP(y|x)
−logP(y∣x)越小就可以了。那我们就引入损失函数,令
l
o
s
s
=
−
l
o
g
P
(
y
∣
x
)
loss=-logP(y|x)
loss=−logP(y∣x)即可。则得到损失函数为:
L
o
s
s
=
−
[
y
l
o
g
y
^
+
(
1
−
y
)
l
o
g
(
1
−
y
^
]
Loss=-[ylog\hat{y}+(1-y)log(1-\hat{y}]
Loss=−[ylogy^+(1−y)log(1−y^]
上述已经推导出单个样本的损失函数,如果要计算N个样本的总损失函数,只要将N个Loss叠加起来就可以了:
L
o
s
s
=
−
∑
[
y
l
o
g
y
^
+
(
1
−
y
)
l
o
g
(
1
−
y
^
]
Loss=-\sum[ylog\hat{y}+(1-y)log(1-\hat{y}]
Loss=−∑[ylogy^+(1−y)log(1−y^]
此时,便完整实现了交叉熵损失函数的推到过程。
为什么在分类问题中一般使用交叉熵而不使用均方误差
在回归问题中,我们常常使用均方误差(MSE)作为损失函数,其公式如下:
l
o
s
s
=
1
2
m
∑
i
=
1
m
(
y
i
−
y
i
^
)
loss = \frac{1}{2m}\sum^{m}_{i=1}(y_i-\hat{y_i})
loss=2m1i=1∑m(yi−yi^)
这也比较好理解,因为回归问题要求拟合实际的值,通过MSE衡量预测值和实际值之间的误差,可以通过梯度下降的方法来优化。而分类问题,需要一系列的激活函数(sigmod、softmax)来将预测值映射到0-1之间,这时候再使用MSE的时候需要好好考虑下了,因为激活函数的缘故,将损失函数关于参数的梯度变得复杂化(不再保证凸优化问题),使用给优化带来难度。


上面复杂的推到过程 ,其实结论就是下面一张图:
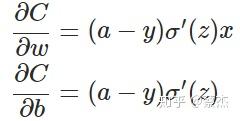
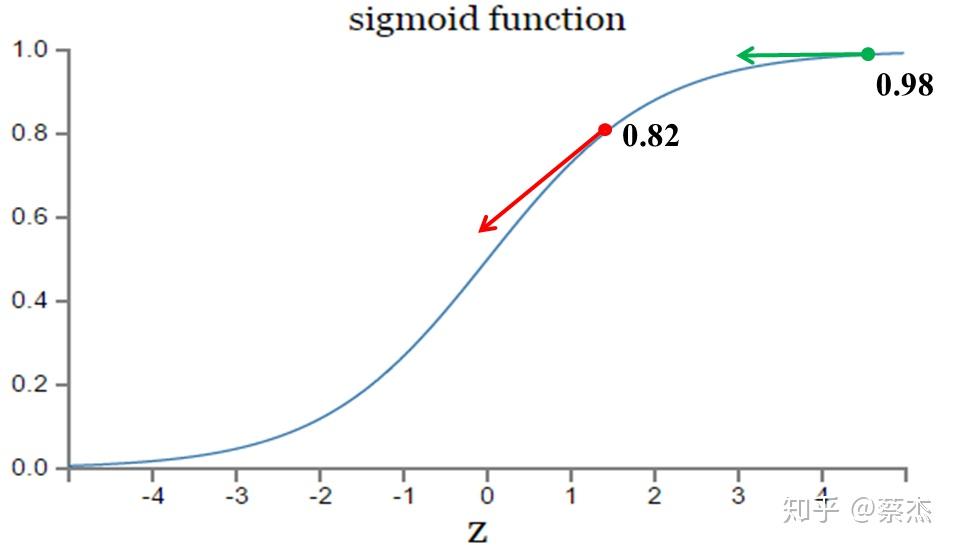
从上述公式可以看出,w和b的梯度跟激活函数的梯度成正比,激活函数的梯度越大,w和b的大小调整越快,训练收敛的越快。而sigmod函数却是长下面这样:
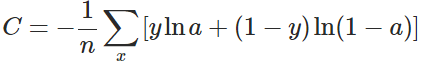
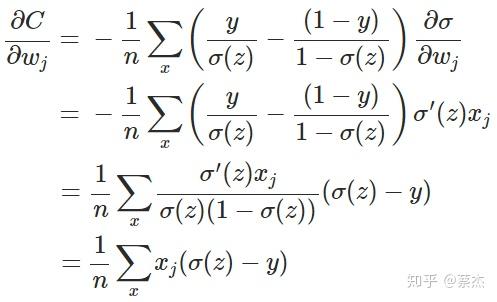
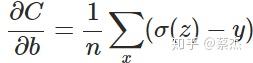
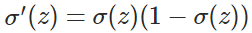
总结
由于神经网络、logistic回归等一般存在sigmod函数作为激活函数,因此若使用MSE作为损失函数时,损失函数关于待求参数的导数中会出现sigmod的导数,而sigmod函数的导数是关于原函数的二次函数(以
σ
(
z
)
\sigma(z)
σ(z)为自变量时,导数为
σ
(
z
)
(
1
−
σ
(
z
)
)
\sigma(z)(1-\sigma(z))
σ(z)(1−σ(z))),这会使得偏导数变得复杂,不利于参数的更新(可能出现)。
而交叉熵求导时,由于log函数的存在,会使得分母上出现相应的二次方项,消元后,梯度是关于
y
−
y
^
y-\hat{y}
y−y^的线性函数,即误差越大,参数更新幅度越大。
更直观的可以这样理解,令预测值与真实值的差
(
y
−
a
)
(y-a)
(y−a)为A,
y
=
1
y=1
y=1为例,那么
σ
′
(
z
)
=
σ
(
z
)
(
1
−
σ
(
z
)
)
\sigma{\prime}(z) = \sigma(z)(1-\sigma(z))
σ′(z)=σ(z)(1−σ(z))转化为
A
(
1
−
A
)
A(1-A)
A(1−A),所以单样本损失函数的梯度
(
a
−
y
)
σ
′
(
z
)
x
(a-y)\sigma{\prime}(z)x
(a−y)σ′(z)x转化为关于误差A的函数
A
2
(
1
−
A
)
x
A^2(1-A)x
A2(1−A)x,是一个关于A的三次函数,无法实现A越大,梯度越大;反观交叉熵的梯度正比于A,A越大,梯度越大,参数更新越快。














 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









