






大家好!今天想和大家聊聊一个未来通信领域非常热门且关键的话题:如何在复杂多变的6G物理层环境中,让深度学习(DL)模型变得更加健壮和可靠?
随着6G时代的脚步越来越近,我们对无线通信的期待也水涨船高:无处不在的连接、极致的速率、极低的时延……深度学习被视为实现这些宏伟目标的关键技术之一,尤其是在物理层,它展现出优化信号处理、提升网络效率的巨大潜力。
然而,理想很丰满,现实却有点“骨感”。当前的DL模型在面对真实无线环境的“狂风暴雨”时,往往表现得有些“脆弱”——性能可能会急剧下降。为什么会这样?我们又该如何应对?
这篇博客正是基于近期一篇发表在 IEEE Network 的一篇综述文章,希望能给大家带来一个关于 6G物理层鲁棒深度学习 的全景视图,涵盖其面临的核心挑战、应对的关键策略与核心方法,以及未来的发展方向。
(一) “脆弱”的DL:6G物理层面临的三大鲁棒性挑战
想象一下,你训练了一个很棒的DL模型用于信号解调,在实验室里效果拔群。但一拿到现实环境中,它可能就“水土不服”了。这主要是因为真实无线环境远比实验室复杂,存在三大挑战:
- 瞬息万变的信道 (Time-Varying Channels): 无线信道不是一成不变的。用户移动、障碍物遮挡(建筑、车辆)、天气变化,甚至6G中更高频段(毫米波/太赫兹)对环境的敏感性、智能反射面(RIS)等新技术的引入,都让信道状态变得极其动态。DL模型如果不能实时适应这种变化,性能自然会大打折扣。
- 无处不在的干扰 (Interference of Noise): 真实环境中的噪声并非简单的“白噪声”。用户间的干扰、背景噪声、硬件损伤等形成的复杂干扰模式,会严重污染接收信号。在6G大规模连接和超密集组网的背景下,干扰问题只会更加严峻。DL模型需要具备从强干扰中提取有用信息的能力。
- 千差万别的场景 (Different Scenarios): 6G将支持极其多样化的应用(VR/AR、自动驾驶、工业物联网等),运行在不同的设备、不同的部署环境(室内、室外、工厂、车辆)下。在一个场景下训练好的模型,很可能在另一个“未曾谋面”的场景下表现糟糕。这就是所谓的“分布外泛化”能力不足,是当前DL模型普遍存在的短板。
(二) 对症下药:增强DL鲁棒性的两大策略
为了应对上述挑战,研究者们提出了两大类策略来提升DL模型的鲁棒性,它们各有侧重:
策略一:数据驱动 (Data-Driven) —— 从数据中学习适应性
这类方法的核心思想是利用数据本身来增强模型的泛化和适应能力。
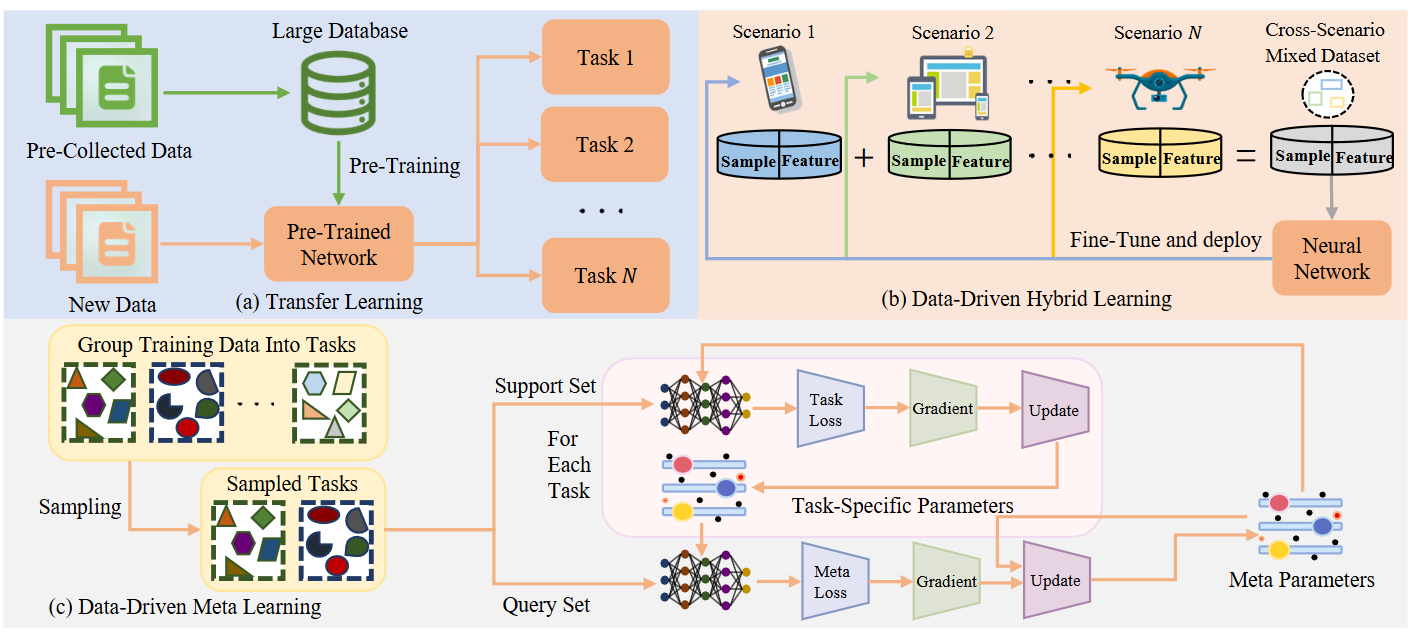
- 迁移学习 (Transfer Learning): 就像学会骑自行车能帮助更快学会骑摩托车一样。我们可以先在一个大型通用数据集上预训练一个模型,然后在特定任务的小数据集上进行微调。这能有效利用已有知识,减少对特定场景数据的依赖,提升对新环境的适应速度。(参考原文Fig. 1a)
- 数据驱动元学习 (Meta-Learning, Data-Driven): 这是一种“学会学习”的方法。通过在大量不同的“任务”(比如不同场景下的信道估计)上进行训练,让模型掌握快速适应新任务的能力,只需少量新数据就能快速调整。MAML是其中的代表。(参考原文Fig. 1c)
- 混合学习 (Hybrid Learning): 聪明地“混合”来自不同场景的数据进行训练,甚至结合自监督学习减少对标签数据的依赖,让模型天生就具备更强的跨场景适应性。(参考原文Fig. 1b)
策略二:模型驱动 (Model-Driven) —— 融合领域知识提升稳定性
这类方法不完全依赖“黑箱”学习,而是将通信领域的先验知识或数学模型融入DL结构中。
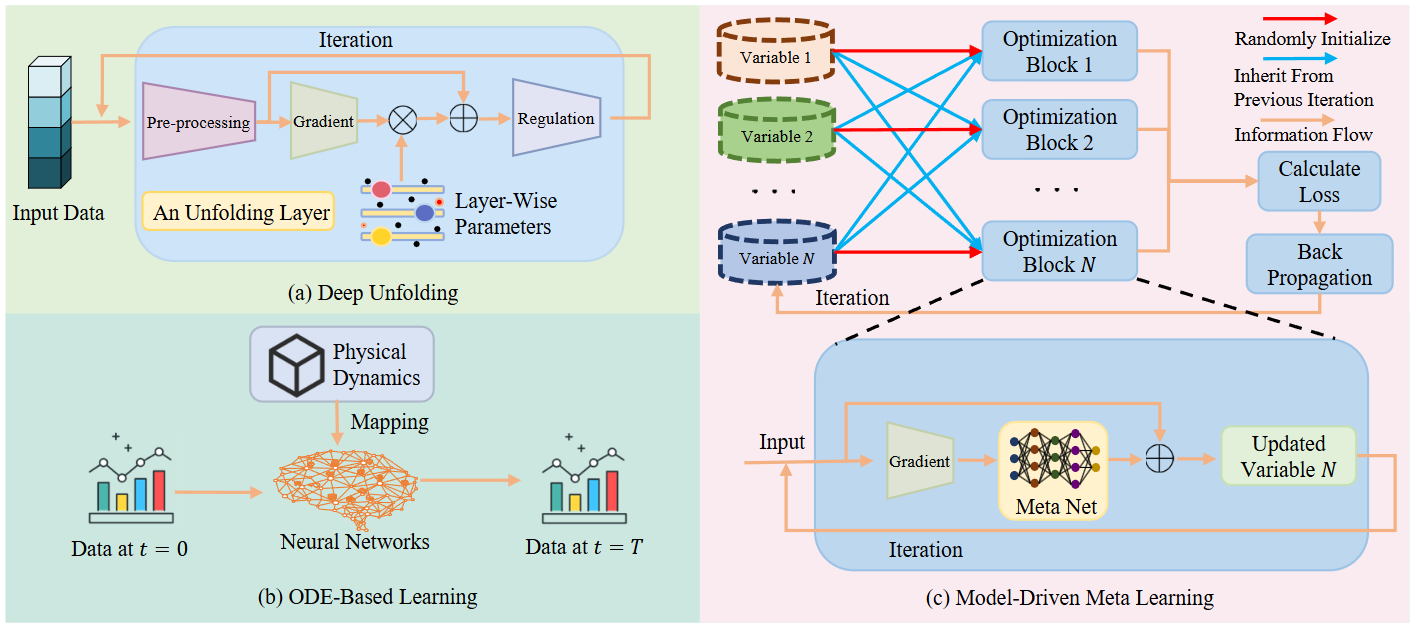
- 深度展开/深度解卷 (Deep Unfolding): 把传统的、有明确物理意义的迭代算法(如WMMSE波束赋形算法)“展开”成一个神经网络。每一层对应算法的一次迭代,其中的参数可以通过数据学习优化。这样做既保留了传统算法的物理解释性,又利用了DL的优化能力,通常更稳定且需要数据更少。(参考原文Fig. 2a)
- 模型驱动元学习 (Meta-Learning, Model-Driven): 与数据驱动元学习不同,它可能直接优化“解决问题的过程”(优化轨迹)本身,而不是仅仅优化模型参数的初始值。这使得模型能更有效地在优化空间中寻找鲁棒解。(参考原文Fig. 2c)
- 基于常微分方程(ODE)的学习 (ODE-Based Learning): 用连续时间的微分方程来描述系统动态,而不是传统的离散层。这使得模型(如Liquid Neural Networks, LNNs)能够更自然地处理连续变化的输入和系统状态,具有内在的适应性和鲁棒性,特别适合建模动态信道等。(参考原文Fig. 2b)
小结:数据驱动 vs. 模型驱动
| 特点 | 数据驱动 (Data-Driven) | 模型驱动 (Model-Driven) |
| 核心思想 | 从大量数据中学习模式与适应性 | 融合物理/数学模型与领域知识 |
| 数据需求 | 通常较高 | 通常较低 |
| 可解释性 | 较低(黑箱) | 较高(部分白盒) |
| 泛化能力 | 依赖数据多样性;可能过拟合 | 依赖模型准确性;结构相对稳定 |
| 复杂度 | 学习复杂模式能力强 | 可能受限于嵌入模型的复杂度 |
| 适用场景 | 数据丰富、动态性强的环境 | 数据有限、需物理解释的场景 |
(三) 实战效果:鲁棒DL方法案例展示
光说不练假把式。这些策略在实际任务中效果如何?我们论文中给出了两个典型案例:
- 信道解码 (Channel Decoding): 在非线性信道下,采用数据驱动元学习(MAML优化DeepSIC)的方法,相比传统Viterbi算法和简单的在线训练,能够更好地应对信道失真,在较高信噪比下获得最低的误码率(BER)。
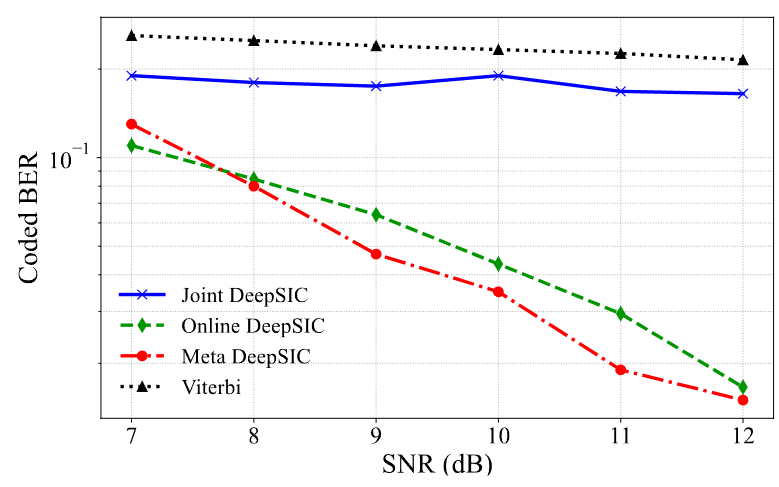
信道解码性能对比。数据驱动的元学习方法(红色虚线)在较高信噪比下误码率最低,展示了其处理非线性信道的优势。 - 波束赋形 (Beamforming): 在用户高速移动的MIMO场景下,采用模型驱动的ODE学习(梯度基的Liquid Neural Network, GLNN),无需预训练,仅通过少量在线数据就能快速适应动态信道,实现比传统WMMSE和LSTM更高的频谱效率(SE)。
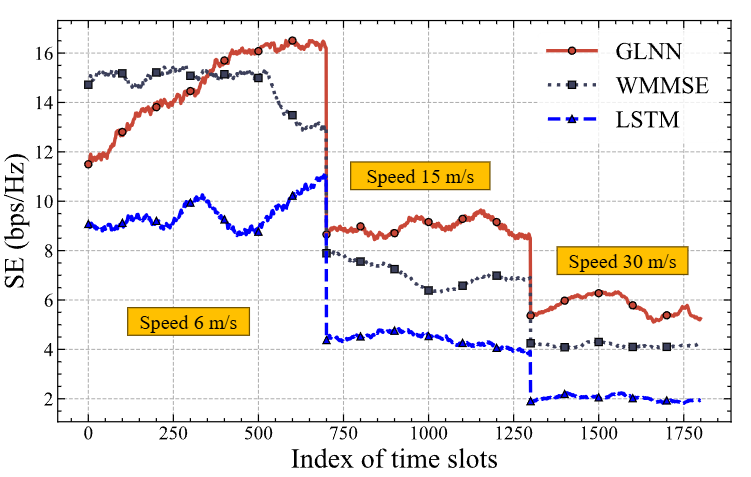
动态波束赋形性能对比。模型驱动的GLNN方法(蓝色实线)无需预训练,能快速适应用户移动带来的信道变化,实现高频谱效率。
这些案例表明,无论是数据驱动还是模型驱动,针对性地设计鲁棒DL方法确实能显著提升物理层通信在复杂环境下的性能和可靠性。
(四) 未来之路:鲁棒DL在6G的星辰大海
虽然我们已经取得了不少进展,但通往真正鲁棒智能的6G物理层,还有很长的路要走。未来的研究方向可能包括:
- 零样本学习 (Zero-Shot Learning): 如何让模型能够处理训练中完全没见过的新设备类型、新干扰模式或信道条件?这是实现真正“随机应变”的关键。
- 分布式学习 (Distributed Learning): 6G网络中设备众多,如何在保证隐私、效率和鲁棒性的前提下,协同训练分布在各处的模型?这需要克服通信开销、数据异构性等挑战。
- 多模态融合 (Multi-Modality Integration): 能不能利用视觉、位置、频谱感知等非射频信号信息,来帮助DL模型更好地理解通信环境,做出更鲁棒的决策?
- 跨层优化 (Cross-Layer Optimization): 打破网络层级壁垒,让物理层的DL决策(如波束赋形)与上层(MAC层调度、网络层路由)信息联动,接近全局最优和鲁棒性。
- 标准化 (Standardization): 如何将这些数据驱动和模型驱动的智能方法纳入未来的6G标准中,确保互操作性和产业化落地?
(结语)
构建鲁棒的深度学习系统是释放AI在6G物理层通信中全部潜力的关键一步。无论是巧妙利用数据的数据驱动策略,还是深度融合领域知识的模型驱动策略,都为我们提供了宝贵的工具箱。
未来,随着这些技术的不断演进和融合,我们有理由相信,深度学习将成为6G网络不可或缺的智能化基石,支撑起一个更加可靠、高效、智能的全连接世界。

















 3159
3159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









