







题目:node2vec: Scalable Feature Learning for Networks
作者:Aditya Grover and Jure Leskovec
来源:KDD 2016
node2vec是一种综合考虑DFS邻域和BFS邻域的graph embedding方法。简单来说,可以看作是deepwalk的一种扩展,是结合了DFS和BFS随机游走的deepwalk。
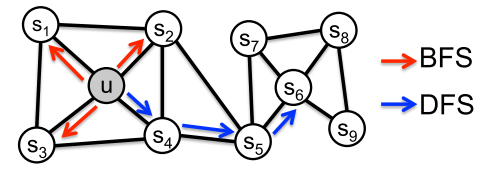
其中BFS对应结构相似性,DFS对应节点同质性。关于为什么BFS和DFS分别对应节点的结构相似性和同质性的讨论见知乎关于Node2vec算法中Graph Embedding同质性和结构性的进一步探讨。采用SkipGram方法对Graph提取表示。根据SkipGram的思路,重点在于定于上下文(Context),也就是Neighborhood。
为了将BFS和DFS结合,去融合发掘图中节点的两种相似性,采用一种二阶的方法Biased-random walk代替BFS和DFS,拥有两个参数p和q,来控制多大的概率反复经过一些Node和控制往回走和往前走。总之,整个Random Walk的目的就是在DFS和BFS之间采取某种平衡。
模型
优化目标
设 f ( u ) f(u) f(u) 是将顶点 u u u 映射为embedding向量的映射函数,对于图中每个顶点 u u u,定义 N S ( u ) N_{S}(u) NS(u) 为通过采样策略 S S S 采样出的顶点 u u u 的近邻顶点集合。
node2vec优化的目标是给定每个顶点条件下,令其近邻顶点(如何定义近邻顶点很重要)出现的概率最大。
max f ∑ u ∈ V log Pr ( N S ( u ) ∣ f ( u ) ) \max _{f} \sum_{u \in V} \log \operatorname{Pr}\left(N_{S}(u) | f(u)\right) fmaxu∈V∑logPr(NS(u)∣f(u))
为了将上述最优化问题可解,文章提出两个假设:
- 条件独立性假设
假设给定源顶点下,其近邻顶点出现的概率与近邻集合中其余顶点无关。
Pr ( N S ( u ) ∣ f ( u ) ) = ∏ n i ∈ N S ( u ) Pr ( n i ∣ f ( u ) ) \operatorname{Pr}\left(N_{S}(u) | f(u)\right)=\prod_{n_{i} \in N_{S}(u)} \operatorname{Pr}\left(n_{i} | f(u)\right) Pr(NS(u)∣f(u))=ni∈NS(u)∏Pr(ni∣f(u))
- 特征空间对称性假设
这里是说一个顶点作为源顶点和作为近邻顶点的时候共享同一套embedding向量。(对比LINE中的2阶相似度,一个顶点作为源点和近邻点的时候是拥有不同的embedding向量的) 在这个假设下,上述条件概率公式可表示为
Pr ( n i ∣ f ( u ) ) &#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4464
4464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









