






 本文详细介绍了C语言中文件的概念、类型(程序文件和数据文件)、文件名管理、二进制与文本文件的区别、数据在文件中的存储、流和文件指针、文件的打开与关闭、顺序读写、文件结束判定以及文件缓冲区的作用。
本文详细介绍了C语言中文件的概念、类型(程序文件和数据文件)、文件名管理、二进制与文本文件的区别、数据在文件中的存储、流和文件指针、文件的打开与关闭、顺序读写、文件结束判定以及文件缓冲区的作用。
一、为什么要使用文件?
如果没有⽂件,我们写的程序的数据是存储在电脑的内存中,如果程序退出,内存回收,数据就丢失 了,等再次运⾏程序,是看不到上次程序的数据的,如果要将数据进⾏持久化的保存,我们就要使⽤⽂件。
二、什么是文件:
磁盘(硬盘)上的⽂件是⽂件。 但是在程序设计中,我们⼀般谈的⽂件有两种:程序⽂件、数据⽂件(从⽂件功能的⻆度来分类 的)。
程序文件:程序⽂件包括源程序⽂件(后缀为.c),⽬标⽂件(windows环境后缀为.obj),可执⾏程序(windows 环境后缀为.exe)。
数据文件:⽂件的内容不⼀定是程序,⽽是程序运⾏时读写的数据,⽐如程序运⾏需要从中读取数据的⽂件,或者输出内容的⽂件。
三、文件名:
我们在生活中也要取各种各样的名字,这样才能方便人们识别,文件也是一样的,也需要定义名字来方便我们使用。
注意:⼀个⽂件要有⼀个唯⼀的⽂件标识,以便⽤⼾识别和引⽤。
⽂件名包含3部分:⽂件路径+⽂件名主⼲+⽂件后缀 例如: c:\code\test.txt 为了⽅便起⻅,⽂件标识常被称为⽂件名。
四、二进制文件和文本文件:
根据数据的组织形式,数据⽂件被称为⽂本⽂件或者⼆进制⽂件。 数据在内存中以⼆进制的形式存储,如果不加转换的输出到外存的⽂件中,就是⼆进制⽂件。 如果要求在外存上以ASCII码的形式存储,则需要在存储前转换。以ASCII字符的形式存储的⽂件就是⽂本⽂件。
五、数据在文件中的存储方式:
⼀个数据在⽂件中是怎么存储的呢?
字符⼀律以ASCII形式存储,数值型数据既可以⽤ASCII形式存储,也可以使⽤⼆进制形式存储。 如有整数10000,如果以ASCII码的形式输出到磁盘,则磁盘中占⽤5个字节(每个字符⼀个字节),⽽ ⼆进制形式输出,则在磁盘上只占4个字节(VS2019测试)。
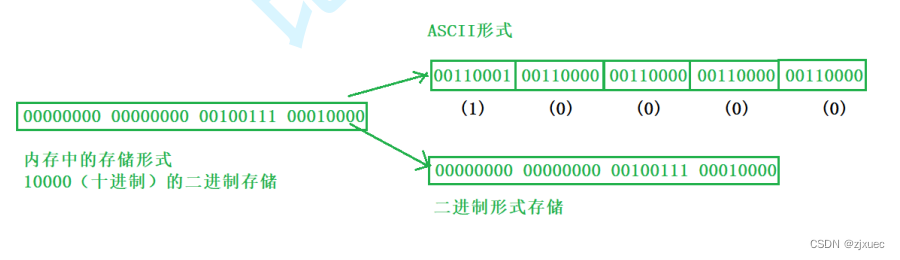
如上图所示,整数10000在内存中有这两种存储方式。
六、 流和文件指针:
指针我们在之前学过,int类型的指针是int*,而文件指针的类型就是FILE*
在VS2013编译环境提供的stdio.h头文件有如下的申明:
struct _iobuf {
char *_ptr;
int _cnt;
char *_base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char *_tmpfname;
};
typedef struct _iobuf FILE;不同的C编译器的FILE类型包含的内容不完全相同,但是⼤同⼩异。 每当打开⼀个⽂件的时候,系统会根据⽂件的情况⾃动创建⼀个FILE结构的变量,并填充其中的信 息,使⽤者不必关⼼细节。
FILE* pf便是创建了一个文件指针。
我们程序的数据需要输出到各种外部设备,也需要从外部设备获取数据,不同的外部设备的输⼊输出 操作各不相同,为了⽅便程序员对各种设备进⾏⽅便的操作,我们抽象出了流的概念,我们可以把流 想象成流淌着字符的河。
标准流:
stdin - 标准输⼊流,在⼤多数的环境中从键盘输⼊,scanf函数就是从标准输⼊流中读取数据。
stdout - 标准输出流,⼤多数的环境中输出⾄显⽰器界⾯,printf函数就是将信息输出到标准输出 流中。
stderr - 标准错误流,⼤多数环境中输出到显⽰器界⾯。
在c语言程序启动时,会默认打开这三个流,这样我们使⽤scanf、printf等函数就可以直接进⾏输⼊输出操作的。这三个流的类型都是FILE*类型。
七、文件的打开和关闭:
在c语言中,我们打开文件要用到的函数为fopen,关闭文件要用到的函数为fclose
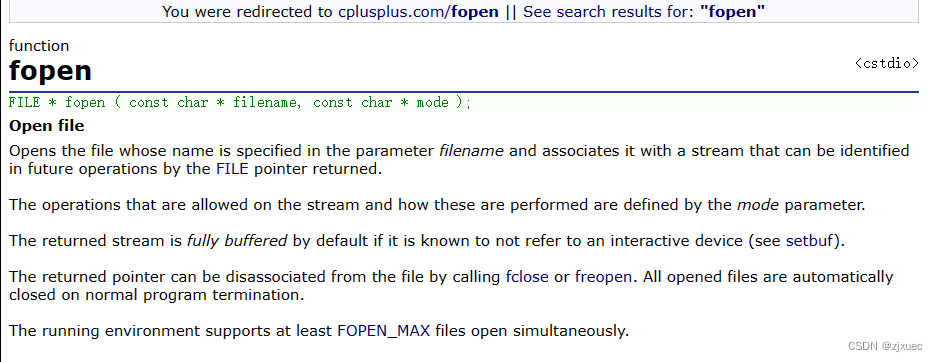
这是关于fopen函数的解释,其中的参数filename是文件名,node是文件的打开模式
下图是node的打开模式图:
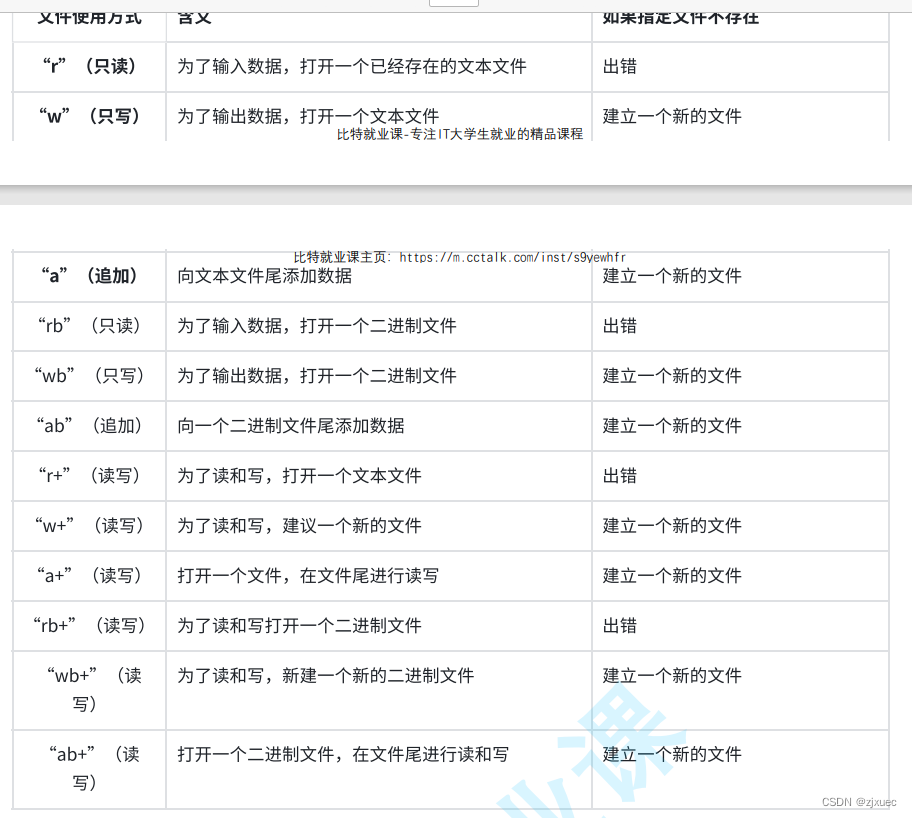
不同的字符代表了不同的模式。
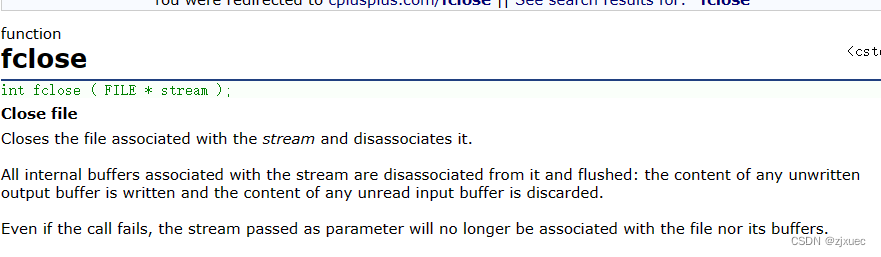
这是fclose函数的解释,参数stream为文件指针。
例子:


成功将字符w写入到bit1的文件当中
代码:
int main()
{
FILE* fe = fopen("bit1.txt", "w");
if (fe == NULL)
{
perror("fopen");
return 1;
}
fputc('w', fe);
fclose(fe);
fe = NULL;
return 0;
}八、文件的顺序读写:
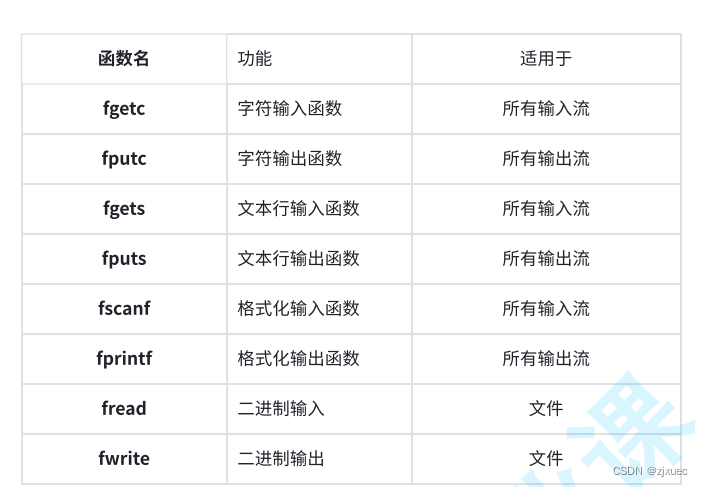
fseek函数:

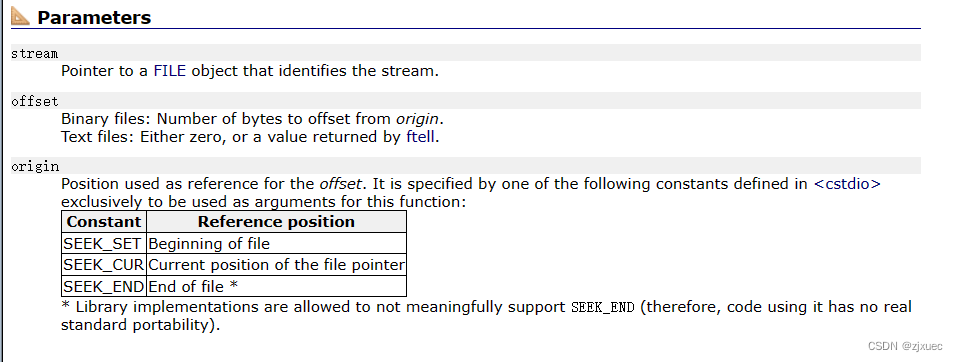
这是fseek函数的解释,他的作用是根据文件指针的位置和偏移量来定位文件指针
stream是文件指针,offset是偏移的字节数,origin有三个选项,SEEK_SET是文件的开头,SEEK_CUR是文件指针的当前位置,SEEK_END是文件的末尾。
例子:

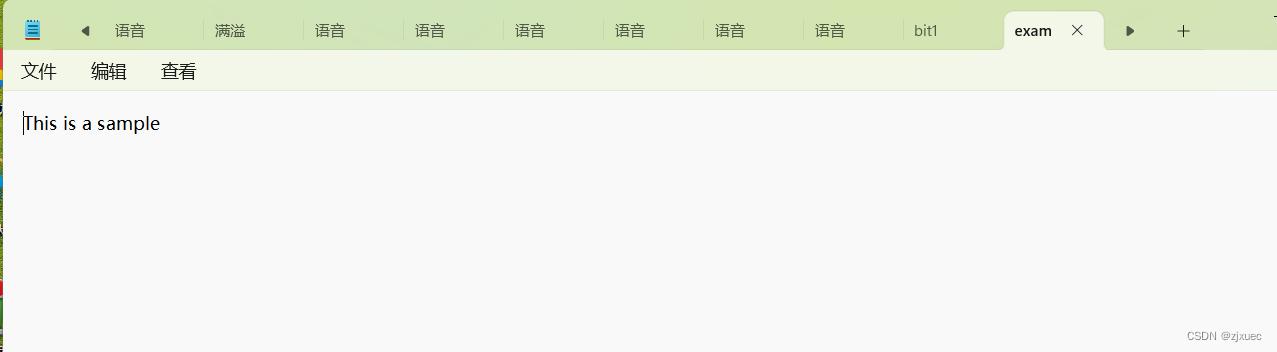
偏移九个字节后,指向了s前的一个空格,然后再输入 sam,最后在文本上显示This is a sample
代码:
int main()
{
FILE* pf;
pf = fopen("example.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
fputs("This is an apple", pf);
fseek(pf, 9, SEEK_SET);
fputs(" sam", pf);
fclose(pf);
pf = NULL;
return 0;
}ftell函数:

这是ftell函数的解释,他的作用是返回文件指针相对于起始位置的偏移量。
例子:

代码:
int main()
{
FILE* pf;
long size;
pf=fopen("myfile.txt","rb");
if(pf==NULL)
{
perror("fopen");
return 1;
}
fseek(pf,0,SEEK_END);
size=ftell(pf);
fclose(pf);
pf=NULL;
printf("%ld\n",size);
return 0;
}rewind函数:
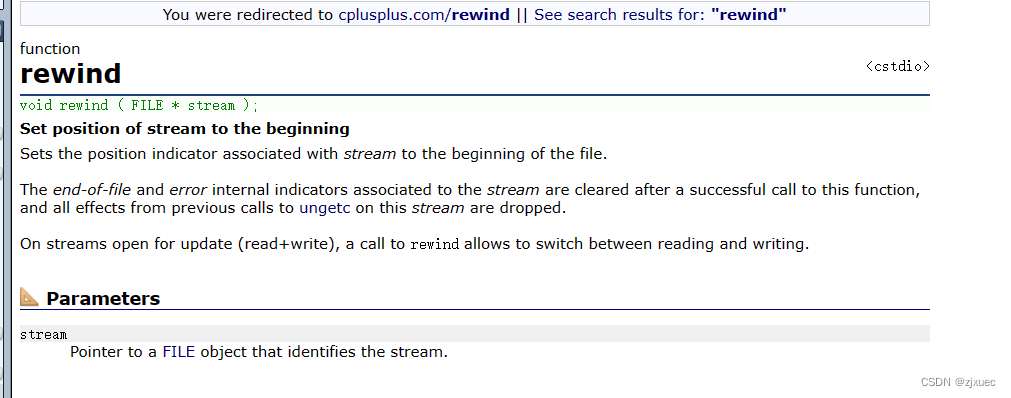
这是rewind函数的解释,他的作用是让文件指针的位置回到文件的起始位置。
例子:

代码:
int main ()
{
int n;
FILE * pFile;
char buffer [27];
pFile = fopen ("file.txt","w+");
if(pFile==NULL)
{
perror("fopen");
return 1;
}
for ( n='A' ; n<='Z' ; n++)
{
fputc ( n, pFile);
}
rewind (pFile);
fread (buffer,1,26,pFile);
fclose (pFile);
pFile=NULL;
buffer[26]='\0';
printf(buffer);
return 0;
}九、文件读取结束的判定:
1 被错误使⽤的 feof
牢记:在⽂件读取过程中,不能⽤feof函数的返回值直接来判断⽂件的是否结束。 feof 的作⽤是:当⽂件读取结束的时候,判断是读取结束的原因是否是:遇到⽂件尾结束。
那我们该如何判断呢?
1. ⽂本⽂件读取是否结束,判断返回值是否为 EOF ( fgetc ),或者 NULL ( fgets )
例如:fgetc 判断是否为 EOF,fgets 判断返回值是否为 NULL 。
2. ⼆进制⽂件的读取结束判断,判断返回值是否⼩于实际要读的个数。
例如:fread判断返回值是否⼩于实际要读的个数。
文本文件例子:
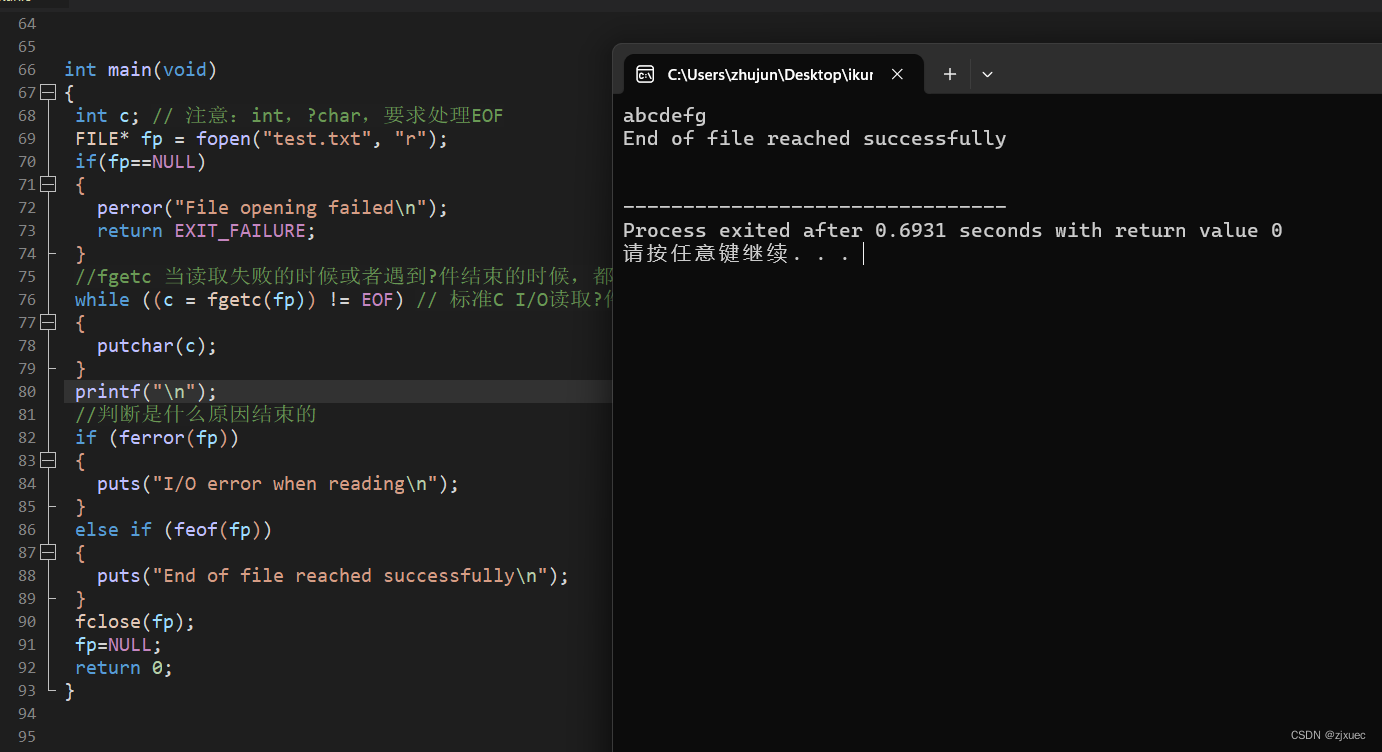

代码:
int main(void)
{
int c; // 注意:int,?char,要求处理EOF
FILE* fp = fopen("test.txt", "r");
if(fp==NULL)
{
perror("File opening failed\n");
return EXIT_FAILURE;
}
//fgetc 当读取失败的时候或者遇到?件结束的时候,都会返回EOF
while ((c = fgetc(fp)) != EOF) // 标准C I/O读取?件循环
{
putchar(c);
}
printf("\n");
//判断是什么原因结束的
if (ferror(fp))
{
puts("I/O error when reading\n");
}
else if (feof(fp))
{
puts("End of file reached successfully\n");
}
fclose(fp);
fp=NULL;
return 0;
}
二进制文件例子:

代码:
enum
{
SIZE = 5
};
int main(void)
{
double a[SIZE] = {1.,2.,3.,4.,5.};
FILE *fp = fopen("test.bin", "wb"); // 必须用二进制模式
fwrite(a, sizeof *a, SIZE, fp); // 写 double 的数组
fclose(fp);
fp=NULL;
double b[SIZE];
fp = fopen("test.bin","rb");
size_t ret_code = fread(b, sizeof *b, SIZE, fp); // 读 double 的数组
if(ret_code == SIZE)
{
puts("Array read successfully, contents: ");
for(int n = 0; n < SIZE; ++n)
printf("%f ", b[n]);
putchar('\n');
} else
{ // error handling
if (feof(fp))
printf("Error reading test.bin: unexpected end of file\n");
else if (ferror(fp))
{
perror("Error reading test.bin");
}
}
fclose(fp);
fp=NULL;
return 0;
}
十、文件缓冲区:
ANSIC 标准采⽤“缓冲⽂件系统” 处理的数据⽂件的,所谓缓冲⽂件系统是指系统⾃动地在内存中为 程序中每⼀个正在使⽤的⽂件开辟⼀块“⽂件缓冲区”。从内存向磁盘输出数据会先送到内存中的缓 冲区,装满缓冲区后才⼀起送到磁盘上。如果从磁盘向计算机读⼊数据,则从磁盘⽂件中读取数据输 ⼊到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的⼤⼩根据C编译系统决定的。
代码:
#include<stdio.h>
#include<windows.h>
int main()
{
FILE* pf;
pf=fopen("test.txt","w");
if(pf==NULL)
{
perror("fopen");
return 1;
}
fputs("abcdef",pf);
Sleep(10000);
fflush(pf);//在高版本的vs上不能使用
Sleep(10000);
fclose(pf);
pf=NULL;
return 0;
}平时我们写文件会发现程序一执行完便会将数据写入到文件中,但我们执行上述代码时会发现,一执行程序去打开test文件会发现test文件中没有任何元素,只有在10秒后刷新了文件缓冲区后才能在test文件里看到我们写入的数据,而我们用fclose关闭文件时,也会进行刷新文件缓冲区的操作,所以也要在fclose前加入睡眠10秒来进行区分。
这⾥可以得出⼀个结论: 因为有缓冲区的存在,C语⾔在操作⽂件的时候,需要做刷新缓冲区或者在⽂件操作结束的时候关闭⽂ 件。 如果不做,可能导致读写⽂件的问题。
文件相关的操作就讲到这里了,希望能够对大家有所帮助。















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









