







 本文介绍了知识图谱的基本概念,重点展示了使用jieba、pyhanlp和smoothnlp进行中文分词的实践,以及在构建知识图谱过程中分词技术的重要性。
本文介绍了知识图谱的基本概念,重点展示了使用jieba、pyhanlp和smoothnlp进行中文分词的实践,以及在构建知识图谱过程中分词技术的重要性。
最近也是在预研知识图谱相关技术。这里面涉及到了一些关于自然语言处理方面的内容和技术。目前已经调研了一些分词、命名体识别相关技术。今天记录下分词工具的使用。
一、什么是知识图谱?
笔者理解的知识图谱是一个巨型的语义网络,形同互联网一样。不过语义网络上每个点是一个实体,两两实体之前存在一条边也就是关系或属性。其实也就是找到一个三元组,类似于(实体、关系、实体)或(实体、属性、属性值)的形式。这里面重要的步骤就是如何把形同这样形式的三元组抽取出来,并且还要保证抽取出三元组的正确性。这无疑是一个巨大的挑战。
二、知识图谱流程图
流程图是按照自己理解画的,有什么地方不妥欢迎指正!(大佬轻喷)
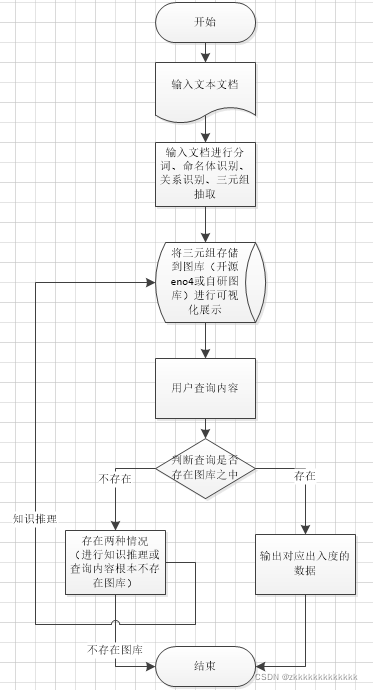
三、知识图谱的框架(工具)有哪些?
目前了解到已有知识图谱开源框架,如:deepke、bert、cndeepdive等等。
①:deepke是浙江大学知识引擎实验室开源的中文关系抽取开源框架。
该项目的官方地址:https://github.com/zjunlp/deepke/
②:bert是谷歌的一个开源框架。
该项目的官方地址:https://github.com/google-research/bert
③:deepdive是斯坦福大学的一个开源知识抽取框架,不过早在2017年就处于维护模式了。
该项目的官方地址:https://github.com/HazyResearch/deepdive
四:使用工具实现文本分词
了解到的jieba、pyhanlp、smoothnlp都可以中文分词,下面将一一介绍三个工具。
①:jieba分词
直接 pip install jieba 安装是很快的。
import jieba
import jieba.posseg as pseg
def postag(text):
words = pseg.cut(text)
return words
# 定义文本
text = 'jieba的主要功能是做中文分词,可以进行简单分词、并行分词、命令行分词,当然它的功能不限于此,目前还支持关键词提取、词性标注、词位置查询等。更让人愉悦的是jieba虽然立足于python,但同样支持其他语言和平台,诸如:C++、Go、R、Rust、Node.js、PHP、 iOS、Android等。所以jieba能满足各类开发者的需求'
# 句子已逗号分隔
jieba_list = []
sentence = text.split('。')
for i in range(len(sentence)):
word = postag(sentence[i]) #分词
for w in word:
# w这里有两个属性,分别为:w.flag==词性;w.word==词
jieba_list.append([w.flag,w.word])
# 输出jieba分词列表
print(jieba_list) ②:pyhanlp分词
值得注意的是运行pyhanlp的时候需要本地按照java环境,因为是它是调用java接口的。
from pyhanlp import *
text = 'jieba的主要功能是做中文分词,可以进行简单分词、并行分词、命令行分词,当然它的功能不限于此,目前还支持关键词提取、词性标注、词位置查询等。更让人愉悦的是jieba虽然立足于python,但同样支持其他语言和平台,诸如:C++、Go、R、Rust、Node.js、PHP、 iOS、Android等。所以jieba能满足各类开发者的需求'
# 句号分割
sentence = text.split('。')
pyhanlp_list = []
for i in range(len(sentence)):
pyhanlp_list.append(HanLP.segment(sentence[i]))
# 输出pyhanlp分词结果
print(pyhanlp_list)
③:smoothnlp分词
这个直接 pip install smoothnlp 即可。
from smoothnlp.algorithm.phrase import extract_phrase
text = 'jieba的主要功能是做中文分词,可以进行简单分词、并行分词、命令行分词,当然它的功能不限于此,目前还支持关键词提取、词性标注、词位置查询等。更让人愉悦的是jieba虽然立足于python,但同样支持其他语言和平台,诸如:C++、Go、R、Rust、Node.js、PHP、 iOS、Android等。所以jieba能满足各类开发者的需求'
# 句子以句号分割
sentence = text.split('。')
smoothnlp_list = []
for i in range(len(sentence)):
smoothnlp_list.append(extract_phrase(sentence[i]))
# 输出smoothnlp分词结果
print("smoothnlp:",a)
五、词性表
点击进入 常用词词性表 查看即可
六、总结
今天主要记录下分词工具的使用,顺便介绍了下自己理解的知识图谱。下篇文章会记录下关于命名体识别的相关技术与思想。点击进入:命名体识别文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









