







1 数据存储结构
hbase与bigtable都是采用LSM数据结构。在谈LSM之前,需要了解下B+树。
1.1 B+树
B+树具有以下特征:
1)叶子节点是有序的,叶子节点之间有指针链接;
2)所有非叶子节点存储的都是其子节点的最小(或最大)关键字;
3)所有数据存储在叶子节点,非叶子节点存储的是索引(关键字)。
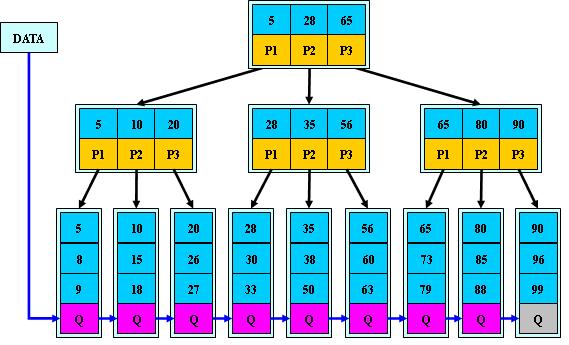
B+树优点:
最大的优点在于支持范围查询。
删除、插入数据的复杂度为O(logn)
1.2 LSM树
LSM树(Log-Structured Merge Tree,日志结构化merge树)。LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。LSM解决磁盘随机写问题。
LSM使用日志文件和内存存储将随机写转换成顺序写。它首先将预写日志的日志文件读入内存中,随着内存占用越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。读的时候先读内存,内存没有时再读硬盘,读硬盘时需要读取多个小文件。所以说定期合并小文件可以提高读性能。
LSM-tree主要目标是快速地建立索引。B-tree是建立索引的通用技术,但是,在大并发插入数据的情况下,B-tree需要大量的磁盘随机IO,很显然,大量的磁盘随机IO会严重影响索引建立的速度。特别地,对于那些索引数据大的情况(例如,两个列的联合索引),插入速度是对性能影响的重要指标,而读取相对来说就比较少。LSM-tree通过磁盘的顺序写,来达到最优的写性能,因为这会大大降低磁盘的寻道次数,一次磁盘IO可以写入多个索引块。
LSM-tree的主要思想是划分不同等级的树。以两级树为例,可以想象一份索引数据由两个树组成,一棵树存在于内存,一棵树存在于磁盘。内存中的树可以不一定是B-树,可以是其他的树,例如AVL树。因为数据大小是不同的,没必要牺牲CPU来达到最小的树高度。而存在于磁盘的树是一棵B-树。

数据首先会插入到内存中的树。当内存中的树中的数据超过一定阈值时,会进行合并操作。合并操作会从左至右遍历内存中的树的叶子节点与磁盘中的树的叶子节点进行合并,当被合并的数据量达到磁盘的存储页的大小时,会将合并后的数据持久化到磁盘,同时更新父亲节点对叶子节点的指针。

之前存在于磁盘的叶子节点被合并后,旧的数据并不会被删除,这些数据会拷贝一份和内存中的数据一起顺序写到磁盘。这会操作一些空间的浪费,但是,LSM-tree提供了一些机制来回收这些空间。
磁盘中的树的非叶子节点数据也被缓存在内存中。
数据查找会首先查找内存中树,如果没有查到结果,会转而查找磁盘中的树。
有一个很显然的问题是,如果数据量过于庞大,磁盘中的树相应地也会很大,导致的后果是合并的速度会变慢。一个解决方法是建立各个层次的树,低层次的树都比上一层次的树数据集大。假设内存中的树为c0, 磁盘中的树按照层次一次为c1, c2, c3, ... ck-1, ck。合并的顺序是(c0, c1), (c1, c2)...(ck-1, ck)。
为什么LSM-tree的插入很快
1. 首先,插入操作首先会作用于内存,并且,内存中的树不会很大,这会很快。
2. 合并操作会顺序写入一个或多个磁盘页,这比随机写快得多。
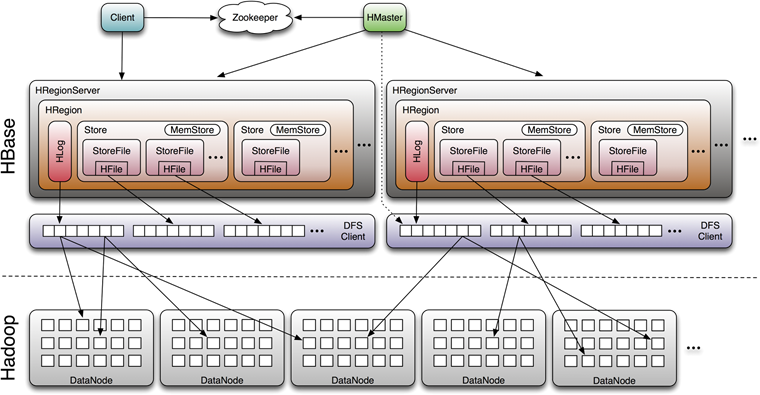
StoreFile内部有序;StoreFile之间无序。Store需要管理StoreFile的头索引。
1.2 HRegion、HStore、MemStore、StoreFile、HFile















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









