







1 模型评估
在数据量充足情况下,对比不同算法,通常采用如下步骤:
1)将数据集分成训练、验证、测试三部分子数据集;
2)训练和验证两个子数据集随机变换,训练模型;对得到的模型用验证数据验证,得到验证误差;
3)选择验证误差最小的那个模型作为最终模型,这个模型就是我们要选择的最佳模型;
4)用最佳模型去跑测试数据集,即可得到该模型的预测误差。不同算法的预测效果就从该预测误差体现出来。
2 模型选择与交付
模型选择是这样的,先计算模型对验证数据的验证误差,然后取验证误差最小的那个模型。注意,在拆分训练、验证、测试三部分子数据集时要随机划分。
最后,模型交付给用户,需要用得到的模型在全部数据集上再训练一遍,因为 这样才能充分利用已有数据,即已有经验。
3 模型(算法)性能对比

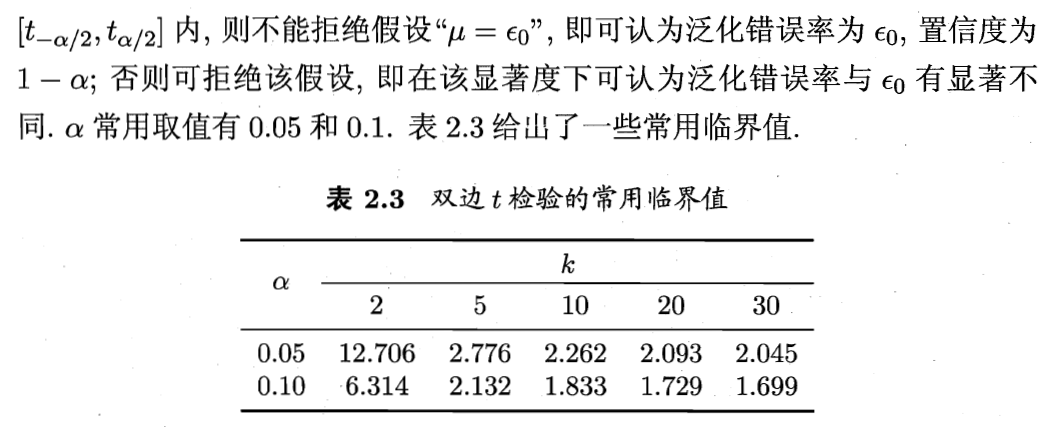
3.1 t检验






4 分类的性能度量
分类任务中,主要用错误率和精度来衡量算法的好坏。
错误率是指分类错误的样本数占样本总数的比例。
精度是指分类正确的样本数占样本总数的比例。
5 混淆矩阵
如有150个样本数据,这些数据分成3类,每类50个。分类结束后得到的混淆矩阵为:

每一行之和为50,表示50个样本,
第一行说明类1的50个样本有43个分类正确,5个错分为类2,2个错分为类3


















 6551
6551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









