where {\displaystyle f(q_{i},D)} is {\displaystyle q_{i}}'s term frequency in the document D, {\displaystyle |D|} is the length of the document D in words, and avgdl is the average document length in the text collection from which documents are drawn. {\displaystyle k_{1}} and b are free parameters, usually chosen, in absence of an advanced optimization, as {\displaystyle k_{1}\in [1.2,2.0]} and {\displaystyle b=0.75}.[1]{\displaystyle {\text{IDF}}(q_{i})} is the IDF (inverse document frequency) weight of the query term {\displaystyle q_{i}}. It is usually computed as:








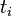 来说,它的重要性可表示为:
来说,它的重要性可表示为:
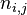 是该词
是该词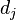 中的出现次数,而分母则是在文件
中的出现次数,而分母则是在文件
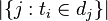 :包含词语
:包含词语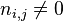 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用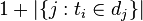
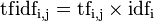






![k_1 \in [1.2,2.0]](https://wikimedia.org/api/rest_v1/media/math/render/svg/0af33de8946a560fed04ff522251656c8207f3db)




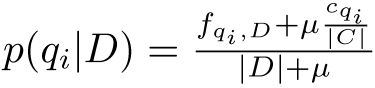















 1391
1391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









