







5.1 CUDA事件计时
https://blog.csdn.net/qq_24990189/article/details/89602618
注意,从这里之后的代码都要用CHECK来检查runtime API的错误。
一个例外:cudaEventQuery(),这个函数可能返回的是cudaErrorNotReady,并不代表真的错了。
计时的步骤:
先定义两个cudaEvent_t变量,并初始化事件,然后开始record。
第五行要query一下事件队列。很容易记忆,都是成对的操作。

这里既可以是host代码,也可以是device代码。但这个cudaEventSynchronize()什么时候使用还没搞懂。什么时候同步呢?估计到后面学到流才能明白。

用这条语句来输出花费的时间。

销毁事件变量
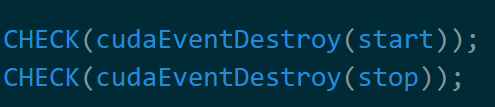
这是唯一使用到事件的地方,暂且记下来。
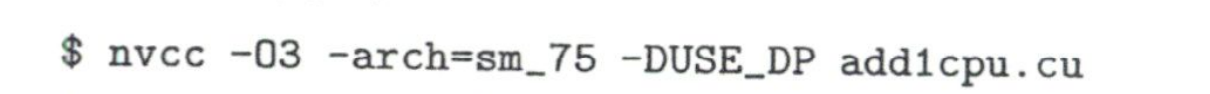
不知道这里的-03是什么意思,但影响还蛮大的,在自己的主机上测试单精度加法需要180ms,远没有达到书中给的60ms。学到了在命令行预定义宏的方法。-D后面加个空格比较好。
但是综合测试下来,发现使用显卡却使用了更多的时间,因为数据转移远比计算需要更多时间。可以用nvprof列一张时间占比的表:

太美好了,这个表。但不知道为什么我的nvprof用不了…所以用了nsight

好看是好看了,但感觉没有表来的直接,比如一条指令call了多少次得点进去看才行。可能是没用熟练。
5.2 影响GPU加速的因素
概念
理论显存带宽:指GPU在单位时间内访问设备内存的字节数。一般实际显存带宽要低于这个值,但也远远高于GPU与CPU之间的传输带宽,如PCIe x16 Gen3仅有16GB/s,而2070TI有360GB/s。
算术强度:算术操作的工作量和必要的内存操作的工作量之比。例如数组相加问题,需要将两个数从内存中取出来,但只做一次运算,再将结果存回内存。算术强度很低。在CUDA中,读写操作都要花费很大代价。
SM(streaming multiprocessor),流多处理器。一个SM有若干个cuda核心,从开普勒架构到福特架构,一个SM中最多驻留的线程数为2048个,图灵架构最多1024个(3090 ti居然有10572个,疯了 属于安培架构,A100也是安培架构),所以一个GPU可以驻留几万到几十万个线程。
原则一:缩短数据传输的时间。一些操作即使在GPU运算的速度不快,也要早GPU中运行,避免使用PCIe来传输。
原则二:提高算术强度,要是计算主导而非访存主导(取出数据做尽可能多的事情,尽可能复杂的操作)
原则三:增大核函数并行规模(尽量塞满GPU)。
文末给了一个很有趣的比较:对于算术强度较低的运算,v100其实性价比不高,因为单精度比双精度运算只快一倍。GeForce理论上能够快32倍。所以V100很适合做高性能计算。
5.3 一些cuda数学库,效率很高,用的时候再查查。
docs.nvidia.com/cuda/cuda-math-api















 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









