







 本文深入浅出地讲解了统计学中的核心概念,包括集中趋势的衡量如众数、中位数、平均数,离散程度的分析如方差、标准差,以及分布形状的描述如偏态系数和峰态系数。提供了详细的定义、计算公式和Python实现代码,适合初学者理解和掌握。
本文深入浅出地讲解了统计学中的核心概念,包括集中趋势的衡量如众数、中位数、平均数,离散程度的分析如方差、标准差,以及分布形状的描述如偏态系数和峰态系数。提供了详细的定义、计算公式和Python实现代码,适合初学者理解和掌握。
思维导图(目录结构):

- 集中趋势
- 众数:一组数据中出现频数最多的数值,常用用Mo表示
#求众数 def Max_number(nums): res = {} for num in nums: res.setdefault(num,0) res[num] += 1 res = sorted(res.items(),key = lambda x:x[1],reverse = True) return res[0][0] - 中位数:一组数据排序后处于中间位置上的数值,常用Me表示。
#中位数 def mid_number(nums): nums = sorted(nums) if len(nums) % 2 == 0: index = len(nums) //2 return (nums[index] + nums[index-1]) / 2 else: index = (len(nums)-1) // 2 return nums[index] - 分位数:是指将一个随机变量的概率分布范围分为几个等份的数值点,常用的有中位数(即二分位数)、四分位数、百分位数等。
- 平均数:又称均值,是全部数据的平均值,主要分为以下三种:设一组样本数据为,
,样本量为n,则样本的平均数用
表示算术平均数:是指在一组数据中所有数据之和再除以数据的个数。它是反映数据集中趋势的一项指标,计算公式为:
- 算术平均数:是指在一组数据中所有数据之和再除以数据的个数。它是反映数据集中趋势的一项指标,计算公式为:
#算术平均数 def average_numbers(numbers): sum_ = 0 n = len(numbers) for number in numbers: sum_ +=number res = sum_ / n return res - 加权平均数:加权平均数是不同比重数据的平均数,加权平均数就是把原始数据按照合理的比例来计算,计算公式w为:
#加权平均数 def weight_average(numbers): f=0 sum_ = 0 for number in numbers: sum_ += number[0]*number[1] f += number[1] return sum_/f -
几何平均数:n个观察值连乘积的n次方根就是几何平均数,,计算公式为:
#几何平均数 def Geo(nums): mul = 0 for num in nums: mul *=num n = 1/len(nums) return mul**(n)
- 算术平均数:是指在一组数据中所有数据之和再除以数据的个数。它是反映数据集中趋势的一项指标,计算公式为:
二、离散程度
- 数值型数据
- 方差:各数据与其平均数离差平方的平均数 公式为:
#方差 def var(numbers): xbar = average_numbers(numbers) n = len(numbers) - 1 sum_ = 0 for number in numbers: sum_ += (number - xbar) **2 return sum_ / n - 标准差:方差的平方根 公式为:
#标准差 def std(numbers): return var(numbers)**0.5 -
极差:也称全距,一组数据的最大值与最小值之差,公式为:R = max(xi) - min(xi)
#极差 def max_min(numbers): return max(numbers) - min(numbers) -
平均差:是总体所有单位与其算术平均数的离差绝对值的算术平均数
#平均差 def averge_sub(numbers): n = len(numbers) xbar = average_numbers(numbers) sum_ = 0 for number in numbers: sum_ +=abs(number - xbar) return sum_ / n
- 方差:各数据与其平均数离差平方的平均数 公式为:
-
顺序数据-四分位差:75%位置上的四分位数与25%位置上的四分位数之差:QD = QU – QL
-
分类数据-异众比率:指的是总体中非众数次数与总体全部次数之比 公式为:
其中:
表示异众比率,
为变量值的总频数,
为众数的频数
-
相对离散程度-离散系数:一组数据的标准差与其相应的平均数之比
三、分布形状
- 偏态系数:测量数据分布不对称的统计量称为偏态系数,公式为:
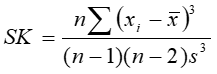
- 峰态系数:是指数据分布峰值的高低,公式为:
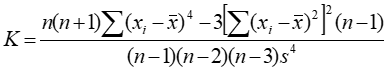
****************************************************************假装有分隔线*****************************************************************
本文是在木东居士的统计学习小组 学习笔记 供大家参考
居士是腾讯的以为数据科学家 在工作之余组织一些学习小组 不是培训班 让大家在一起讨论学习
数据科学家学习小组之统计学(第二期)
https://mp.weixin.qq.com/s/JUnaXgjDMcLinMxpJLZ36g
机器学习小组(第一期)学习形式+打卡方式+参考资料
https://mp.weixin.qq.com/s/fUAUm74AAqWYI_UIMmB-mA
感兴趣的童鞋可以关注一下

















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









