







导语
在上一节中,我们求解了OLS的解析式,但是对于样本数量较多的情况下,矩阵的求解过程计算量非常大,本节讨论的是线性回归中的梯度下降法。
梯度下降法
梯度下降在李航的《统计学习方法》附录A里有比较详细的理论推导过程,大家可以参考。梯度下降是求解无约束最优化问题的一种最常见的方法,实现比较简单。它的核心在于迭代,即给定初值
x(0)
,通过不断迭代,来更新
x
,使目标函数(线性回归中就是我们的损失函数)取得极小值,直到收敛。下面是一张梯度下降的示意图,对此,我们可以这样理解,当你站在一座山上要下山,那么你环顾四周,寻找当前能下的最快的方向,一步踩下去……然后不断的这样,直到你站在了山下。
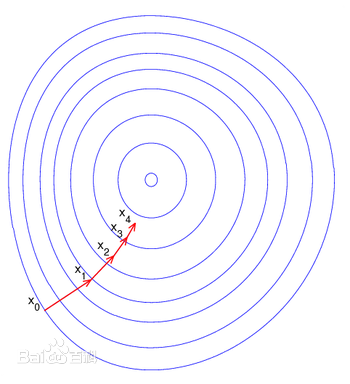
梯度下降的原理就是这样,那么问题来了,我站在山上下去的方向多了,我选哪一个呢?OK,回想另外一个问题,对于
(∂f∂x,∂f∂y)
为函数 z=f(x,y) 在点p的梯度,记做 gradf(x,y) 。
ok,梯度定义出来以后,我们就可以搜索了,定义式如下:
x(k+1)←x(k)+λkpk
其中 λk 是学习率,即每次下降的幅度,而 pk 是下降方向,通常情况下我们选择的是负梯度方向。
线性回归的梯度下降
线性回归的损失函数为:
J(θ)=12∑i=1m(θT∗x(i)−y(i))2
我们最终要求的是参数 θ ,而 x(i) 和 y(i) 已知(样本数据),因此对 θ 求导求出梯度方向。
∂∂θjJ(θ)=2∗12∗∑i=1m(θT∗x(i)−y(i))∗∂∂θj(∑θkx(i)k−y(i))=∑i=1m(θT∗x(i)−y(i))∗x(i)j
上述的表达式就是线性回归的梯度方向,由于使用了 ∑ ,因此每次更新参数 θ 使用了全部样本,此种方式也被称为 批处理梯度下降算法,更新公式为
θj:=θj+λ∗∑i=0m(θT∗x(i)−y(i))∗x(i)j
由于批处理梯度下降算法使用了所有算法,当迭代次数较多时,计算量依旧很大,因此在实践中多采用 随机梯度下降算法,即每次只用一个样本数据来更新参数 θ ,这样可以大幅降低计算量,但是这种方式的效果可能不如批处理梯度下降算法,批处理梯度下降能够得到 全局最优解,但是随机梯度处理可能在某些样本点使参数 θ 剧烈变化,因此对于学习率 λ ,在实践中其值经常是动态的,此话题下次讨论。
由于最近有些事情耽误,因此本节先讨论到这里,在逻辑回归之后,我将以具体代码示例来阐述我们做过的数学推导,曾几何时我只注重工程上的东西,但是后来发现不知道原理自己永远只能是一个coder,永远在迷雾中前行,加油吧……















 1117
1117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









