







前言
前面一节介绍了梯度下降的概念,本质上它是一个优化问题,通过不断的迭代来求得局部最优值,本节将介绍一个非常有名的函数-sigmoid函数,而逻辑回归可以看成是一个线性回归的值再通过非线性函数sigmoid映射到0-1空间,逻辑回归的使用非常广泛,在广告点击、预测、分类中都有它的影子,同时,它也是神经网络中神经元的一种常见形式。
sigmoid函数
sigmoid
函数是非常有名的一个非线性函数,函数形式如下所示:
g(z)=11+e−z
sigmoid 函数非常简单,我们任何一个人都可以画出它的图形,当 z=0 时, g(z)=12 ,当 z>1 时, g(z)>0.5 ,反之, g(z)<0.5 。sigmoid函数图形如下所示:
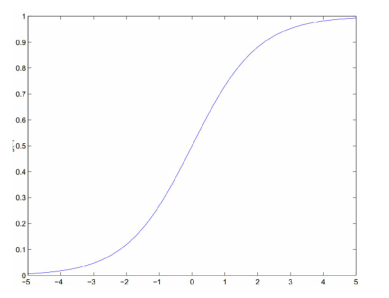
当然,在实践中应用比较多的非线性函数还有 tanh 函数。它们都能将值映射到一个区间, sigmoid 是0~1, tanh 是-1~+1。
逻辑回归
逻辑回归的过程
所谓逻辑回归,我拿神经网络中的一个基础神经单元为例,图例如下所示。对于变量
x1,x2,x3,…,xn
,它有一个权重系数
wi
,
b
是一个偏置量,
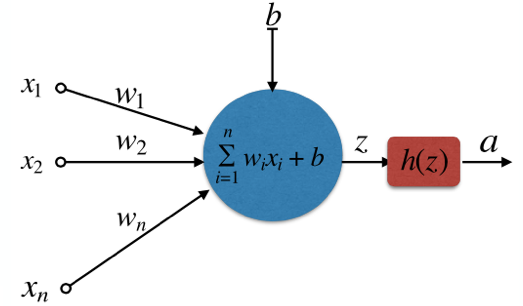
OK,我想逻辑回归它的概念大家应该已经了解了,其实就是先线性回归再带到激活函数中。下面再从数学上继续对它进行一些挖掘。
逻辑回归的二分理解
我们看到
sigmoid
函数的区间是0~1,跟概率论中的概率累积函数是一致的,好的,理解到这就是关键,我们对它进行求导,就得到了概率分布函数如下所示:
g′(z)=11+e−z∗(1−11+e−z)
逻辑回归是一个二分类的问题,就是说对于结果我们一般只取 0 或者
p(y=1|x)=11+e−z
那么
p(y=0|x)=1−11+e−z
此时,
p(y=1|x)+p(y=0|x)=1
,逻辑回归的二分类问题解释完毕。
参数的估计
这里列出最终的逻辑回归公式,如下所示:
g(z)=11+e∑ni=1wi∗xi+b=11+eWTX
在实际情况中,偏置量 b 通常取1.0,它并不会对参数
L(θ)=∑i=1m(y(i)logh(x(1))+(1−y(i))log(1−h(x(i))))
h(x) 就是激活函数实际计算出来的结果。将上述的结果对 wj 进行求导,这里忽略求和…..
∂L(θ)∂wj=(y∗1h(x)−(1−y)∗11−h(x))∗∂h(x)∂wj
∂h(x)∂wj=h(x)∗(1−h(x))∗∂WTXwj=h(x)∗(1−h(x))∗xj
因此:
∂L(θ)∂wj=(y−h(x))∗xj
与线性回归的结果是一致的。接下来,就可以按照梯度下降的更新公式更新参数 w <script type="math/tex" id="MathJax-Element-6023">w</script>。
实际例子
以《机器学习实战》中逻辑回归中提供的数据集为例,格式如下:
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
0.406704 7.067335 1
0.667394 12.741452 0
-2.460150 6.866805 1
0.569411 9.548755 0
……batch梯度下降的关键代码如下:
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn)
labelMat = mat(classLabels).transpose()
m,n = shape(dataMatrix)
alpha = 0.001 #学习率,实际情况下需要不断调整
maxCycles = 500 #迭代次数
weights = ones((n,1))
for k in range(maxCycles):
h = sigmoid(sum(dataMatrix*weights))
error = (labelMat - h)
weights = weights + alpha * dataMatrix.transpose()* error #梯度更新公式 w = w + alpha*(y-h(x))*x
return weights运行结果如下:
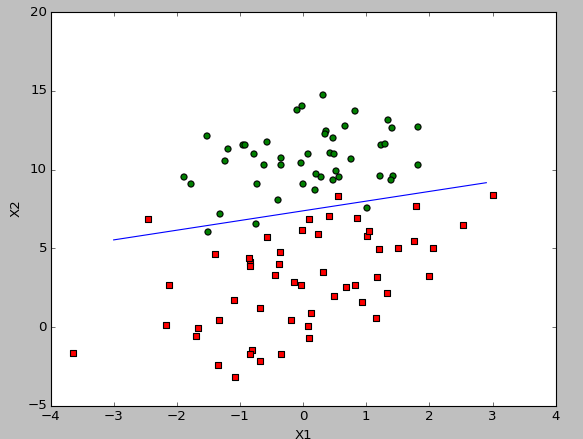















 2358
2358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









