import pandas as pd
import numpy as np
from sklearn import metrics
from sklearn. metrics import classification_report
from sklearn. model_selection import train_test_split
import numpy as np
import matplotlib. pyplot as plt
plt. rcParams[ 'font.family' ] = 'SimHei'
import seaborn as sns
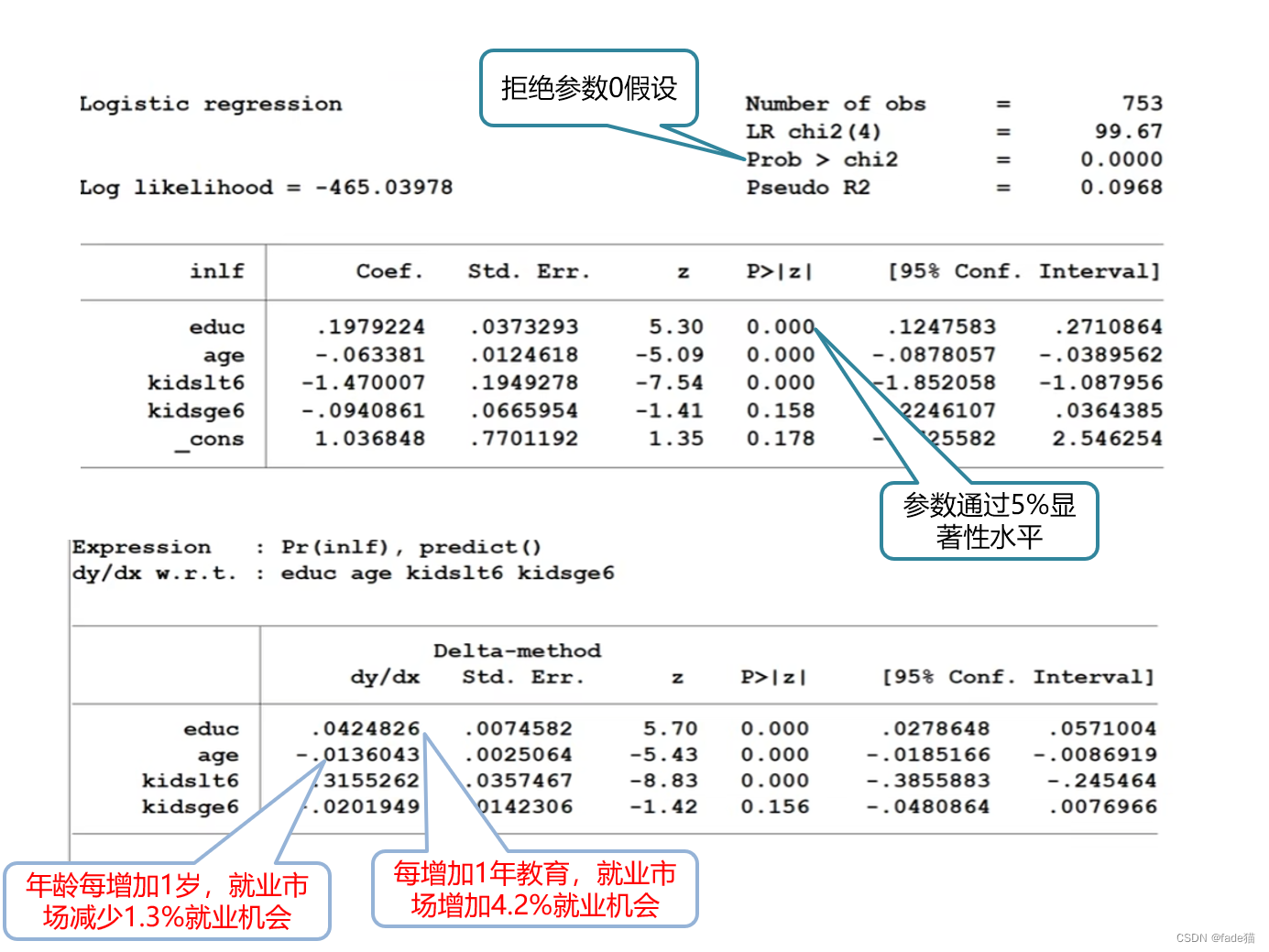
df = pd. read_csv( "heart.csv" )
X = df. drop( [ 'target' ] , axis= 1 )
y = df. target. values
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size= 0.3 , random_state= 16 )
logreg = LogisticRegression( )
logreg. fit( X_train, y_train)
y_pred = logreg. predict( X_test)
cnf_matrix = metrics. confusion_matrix( y_test, y_pred)
class_names= [ 0 , 1 ]
fig, ax = plt. subplots( )
tick_marks = np. arange( len ( class_names) )
plt. xticks( tick_marks, class_names)
plt. yticks( tick_marks, class_names)
sns. heatmap( pd. DataFrame( cnf_matrix) , annot= True , cmap= "YlGnBu" , fmt= 'g' )
ax. xaxis. set_label_position( "top" )
plt. tight_layout( )
plt. title( '混淆矩阵' , y= 1.1 )
plt. ylabel( '真实标签' )
plt. xlabel( '预测标签' )
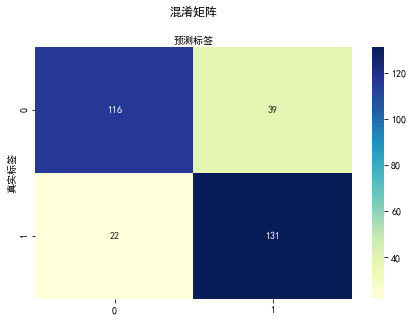
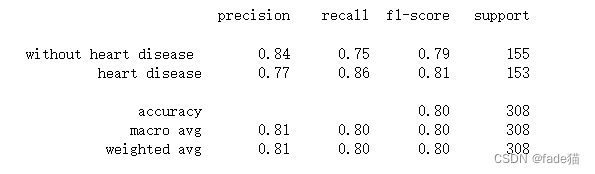
target_names = [ 'without heart disease ' , 'heart disease' ]
print ( classification_report( y_test, y_pred, target_names= target_names) )
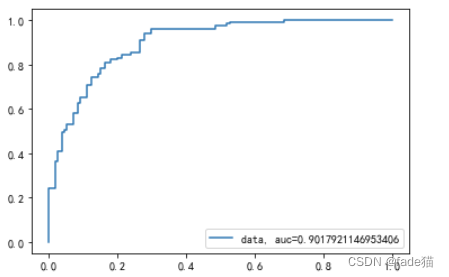
y_pred_proba = logreg. predict_proba( X_test) [ : : , 1 ]
fpr, tpr, _ = metrics. roc_curve( y_test, y_pred_proba)
auc = metrics. roc_auc_score( y_test, y_pred_proba)
plt. plot( fpr, tpr, label= "data, auc=" + str ( auc) )
plt. legend( loc= 4 )
plt. show( )
























 1940
1940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









