






本爬虫代码能够爬取京东商品的评论,并将获取的评论信息保存到Navicat数据库中。下面是具体的实现方法。
打开想要爬取评论的商品,按下f12打开开发者选项,点击网络找到Fetch/XHR,然后找到包含评论的信息。
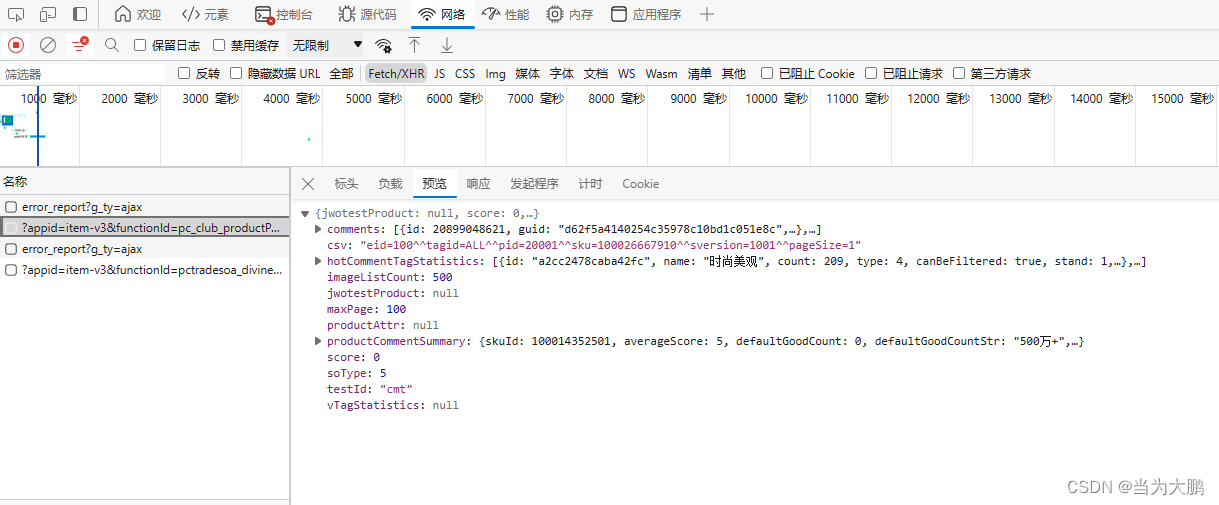
由于代码中需要设置URL,但是URL标头中的URL中的信息都是加密的,我们无法使用,因此我们需要手动的将加密部分的信息手动的替换掉。
 其中加密的uuid和t是在负载。
其中加密的uuid和t是在负载。
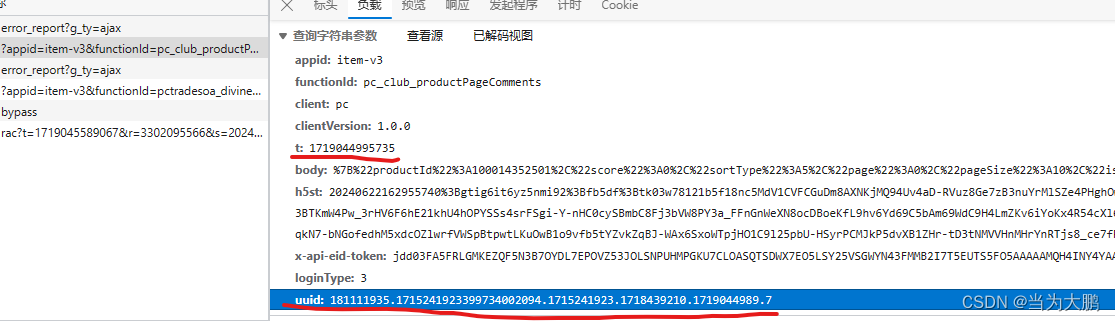
productid就是下面画线的信息。

将信息替换之后就可以对评论进行爬取了。
这是爬取评论的页码范围,可以根据自己的需要进行修改。

我为代码添加了一个计数器,要求最多爬取250条评论,可以根据自己的需求删除或者修改计数器。

下面代码可以直接删除,对代码没有影响。

import requests
import mysql.connector
#获取京东商品指定页码的评论
items = []
#手机、电脑、衣服、美妆、食品、酒类、书籍
# 根据page处理url
def get_url(n):
print('爬取第' + str(n + 1) + '页')
page = '&page=' + str(n)
url = 'https://club.jd.com/comment/productPageComments.action?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&t=1715134951798&loginType=3&uuid=181111935.1035068438.1704959833.1715132234.1715132469.11&productId=12432673&score=0&sortType=5' + page + '&pageSize=10&isShadowSku=0&fold=1&bbtf=1&shield='
return url
def save_to_mysql(data, jdcomments, category, url1, title):
# 连接到MySQL数据库
conn = mysql.connector.connect(
user='root',
password='root',
host='127.0.0.1',
database='comments'
)
cursor = conn.cursor()
# 如果表不存在,则创建表
create_table_query = (
"CREATE TABLE IF NOT EXISTS " + jdcomments + " ("
"id INT AUTO_INCREMENT PRIMARY KEY,"
"username VARCHAR(255),"
"goods VARCHAR(255),"
"buyCount VARCHAR(255),"
"score INT,"
"content TEXT,"
"time DATETIME,"
"location VARCHAR(255),"
"reply TEXT,"
"category VARCHAR(255) NOT NULL DEFAULT '" + category + "'," # 注意这里逗号的位置
"url1 VARCHAR(255) NOT NULL DEFAULT '" + url1 + "'," # 注意这里逗号的位置
"title VARCHAR(255) NOT NULL DEFAULT '" + title + "'" # 注意这里去除了多余的右括号
")"
)
cursor.execute(create_table_query)
# 插入数据到数据库,如果主键重复则更新已有记录
insert_query = (
"INSERT INTO " + jdcomments + " (username, goods, buyCount, score, content, time, location, reply, category, url1, title) "
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s) "
"ON DUPLICATE KEY UPDATE "
"username=VALUES(username), goods=VALUES(goods), buyCount=VALUES(buyCount), score=VALUES(score), content=VALUES(content), time=VALUES(time), location=VALUES(location), reply=VALUES(reply), category=VALUES(category),url1= VALUES(url1), title= VALUES(title)"
)
cursor.executemany(insert_query, data)
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()
if __name__ == '__main__':#判断脚本是被直接运行还是作为模块被导入,若为模块导入则忽略
category = "书籍" # 设置category的值为"数码"
title = "罗生门"
url1 = "https://item.jd.com/12432673.html"
items = []#是一个空列表,可能用于存储抓取到的产品信息
count = 0 # 计数器
# 循环爬取每一页评论,范围可根据实际修改
for page in range(0, 120):
# 请求头部信息,可不修改
header = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62'}
url = get_url(page)#生成当前页面的URL
response = requests.get(url=url, headers=header)
json_data = response.json()
data = json_data['comments']#从JSON响应中提取评论数据
for t in data:
content1 = t['content']
time = t['creationTime']
if 'location' in t:
location = t['location']
else:
location = '空'
user = t['nickname']
goods = t['productColor']
score = t['score']
if 'buyCount' in t.get('extMap', {}):
buyCount = t['extMap']['buyCount']
else:
buyCount = '空'
if 'replies' in t and len(t['replies']) > 0 and 'content' in t['replies'][0]:
content2 = t['replies'][0]['content']
else:
content2 = '商家没有回复'
item = (user, goods, buyCount, score, content1, time, location, content2, category, url1, title)
items.append(item)#将 item 元组添加到 items 列表中
count += 1 # 每添加一条数据,计数器加1
if count >= 250:
break
if count >= 250:
break
# 保存数据到MySQL数据库中的jdcomments表
save_to_mysql(items, "jdcomments", category, url1, title)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









