






本爬虫代码能够爬取网易云音乐的评论,并将获取的评论信息保存到Navicat数据库中。下面是具体的实现方法。
找到含有评论的信息。
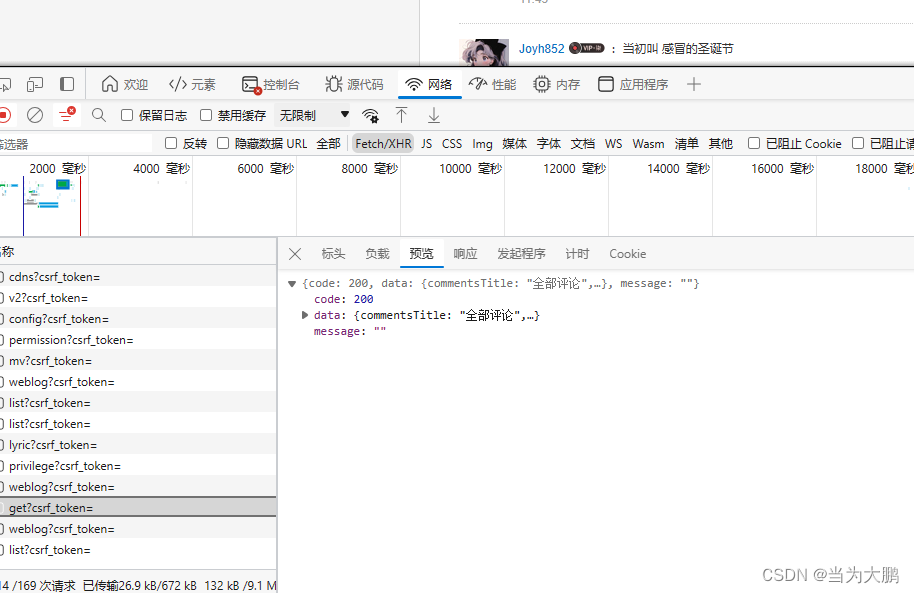
将user-agent替换成自己电脑中的。

将画线部分替换成想要爬取的音乐的id,往往在网址中就含有id。


此部分内容可以删除,但是要删除代码中对应的内容。

代码中设置了计数器,可以根据自己的需求对计数器进行删除或者修改。
将数据库的用户名和密码修改为自己的,然后就可对评论进行爬取了。
import requests
import time
import json
import datetime
import pymysql
#获取网易云所有评论(感动)用这个
headers = {#设置请求头模仿浏览器请求
'Host': 'music.163.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62'
}
def get_comments(songId, offset):#获取指定歌曲的评论
url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_{0}?limit=100&offset={1}'.format(songId, str(offset))
response = requests.get(url=url, headers=headers)#向构造的URL发送一个HTTP GET请求
result = json.loads(response.text)#将响应内容转换为JSON格式,response.text获取响应内容
if 'comments' in result:#判断result中是否含有comments
temp = []#创建了一个空列表,用于存储提取后的评论数据
for item in result['comments']:#遍历comments中的评论
data = {}#创建了一个空字典,用于存储当前评论的所有数据
data['userId'] = item['user']['userId']
data['nickname'] = item['user']['nickname']
data['content'] = item['content'].replace("\n", ",")
timeArray = time.localtime(item['time'] / 1000)
date = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
data['date'] = date
data['likedCount'] = item['likedCount']
data['category'] = '感动' # 设置固定的分类值
data['url'] = 'https://music.163.com/song?id=1465313631'
data['title'] = '化身孤岛的鲸'
temp.append(data)#将提取后的数据字典添加到临时列表中
return temp
else:
print("No comments found in the response.")
return []
if __name__ == '__main__':
db = pymysql.connect(
host='localhost',
user='用户名',
password='密码',
db='comments',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor,
#指定游标类型为DictCursor,这意味着游标将返回字典对象而不是元组,这样可以更方便地处理SQL查询结果
)
cursor = db.cursor()#创建了一个游标对象,用于执行数据库操作
# 检查表是否存在
table_name = "cs2"
check_sql = f"SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = '{table_name}'"
cursor.execute(check_sql)
result = cursor.fetchone()#获取查询后的结果
if result is None:
# 创建表
create_table_sql = """CREATE TABLE cs2 (
id INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
userId BIGINT(20),
nickname VARCHAR(255),
content TEXT,
date TIMESTAMP,
likedCount INT(11),
category VARCHAR(255)
)"""
cursor.execute(create_table_sql)
offset = 0
count = 0 # 计数器
while True:
temps = get_comments("1465313631", offset)
if len(temps) == 0 or count >= 200: # 当获取的评论数量达到200或者已经爬取完所有评论时停止
break
for temp in temps:
# 检查评论是否已经存在
check_sql = "SELECT * FROM cs2 WHERE userId=%s AND content=%s"
cursor.execute(check_sql, (temp['userId'], temp['content']))
result = cursor.fetchone()
if result is None:#评论不存在
# 插入数据
insert_sql = """INSERT INTO cs2 (userId, nickname, content, date, likedCount, category, url, title)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"""
cursor.execute(insert_sql, (
temp['userId'],
temp['nickname'],
temp['content'],
temp['date'],
temp['likedCount'],
temp['category'], # 插入 category 列数据
temp['url'],
temp['title']
))
db.commit()
count += 1 # 每插入一条数据,计数器加一
offset += 20
db.close()
















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









